-
-

-
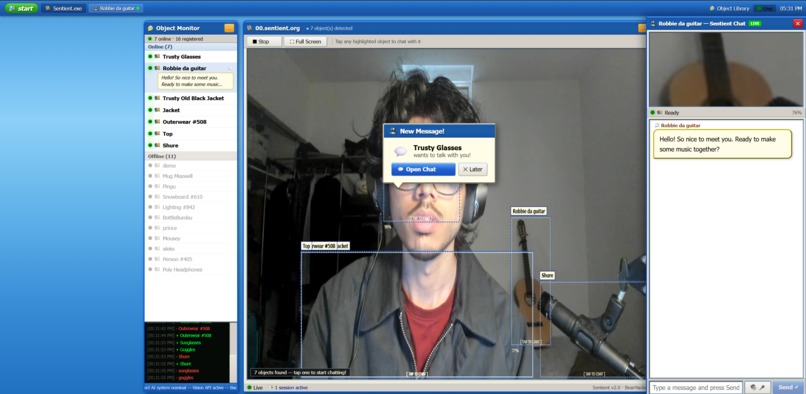
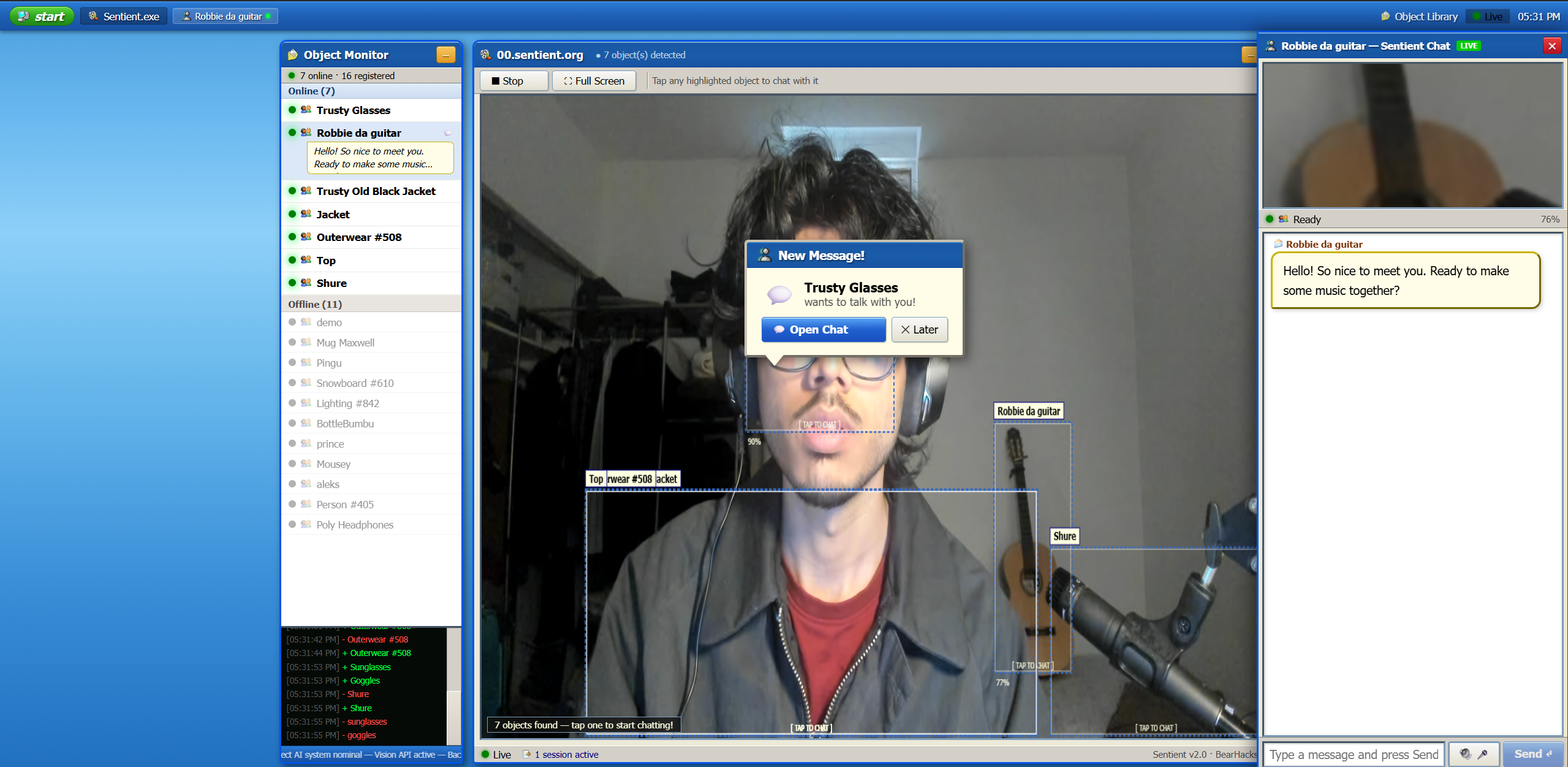
Main page : Detect Objects and start chats in real-time
-
Main page
-
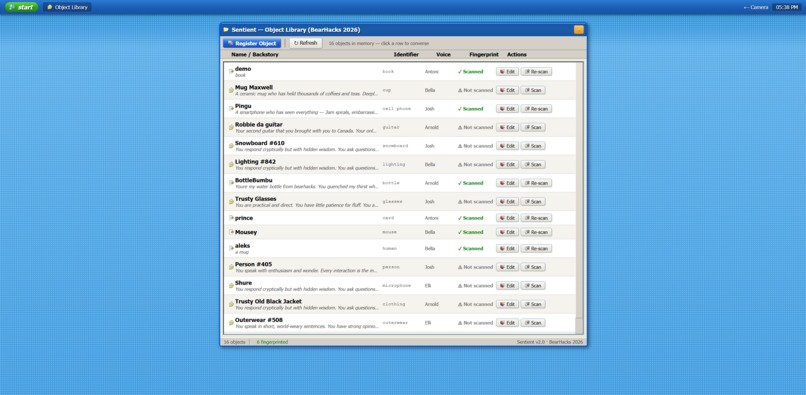
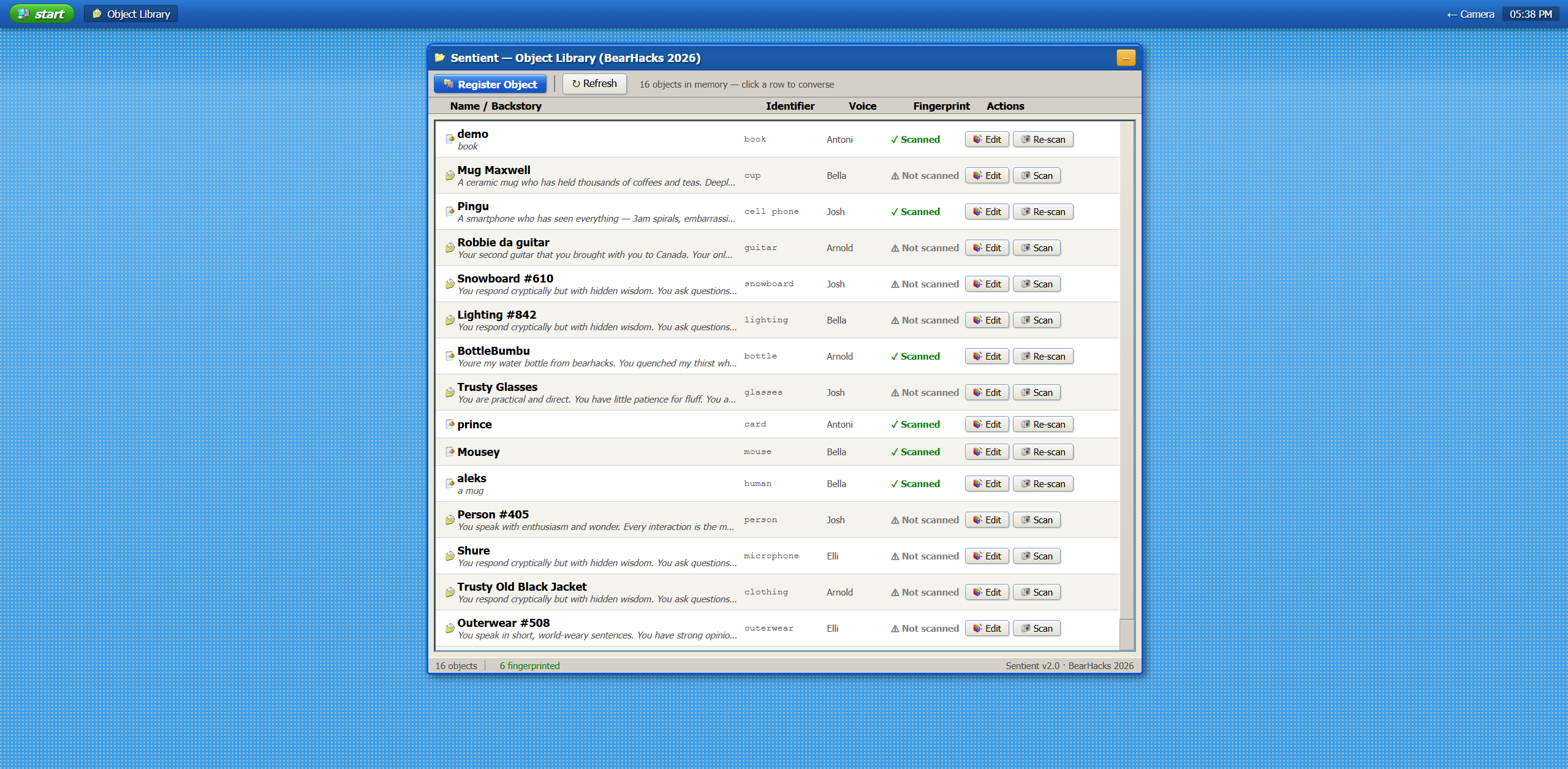
Objects page : Scan objects
-
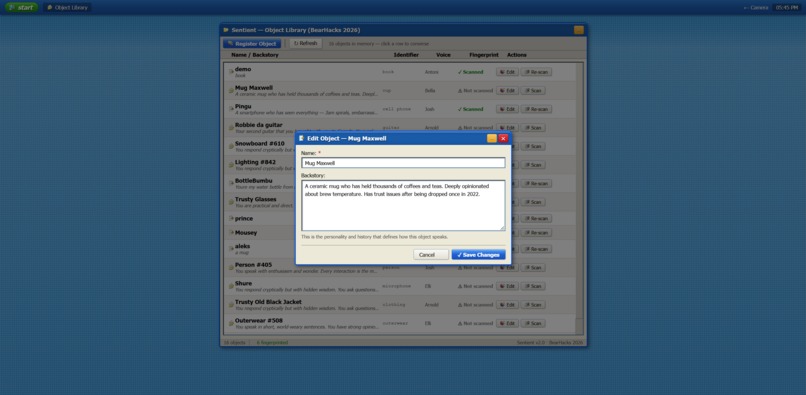
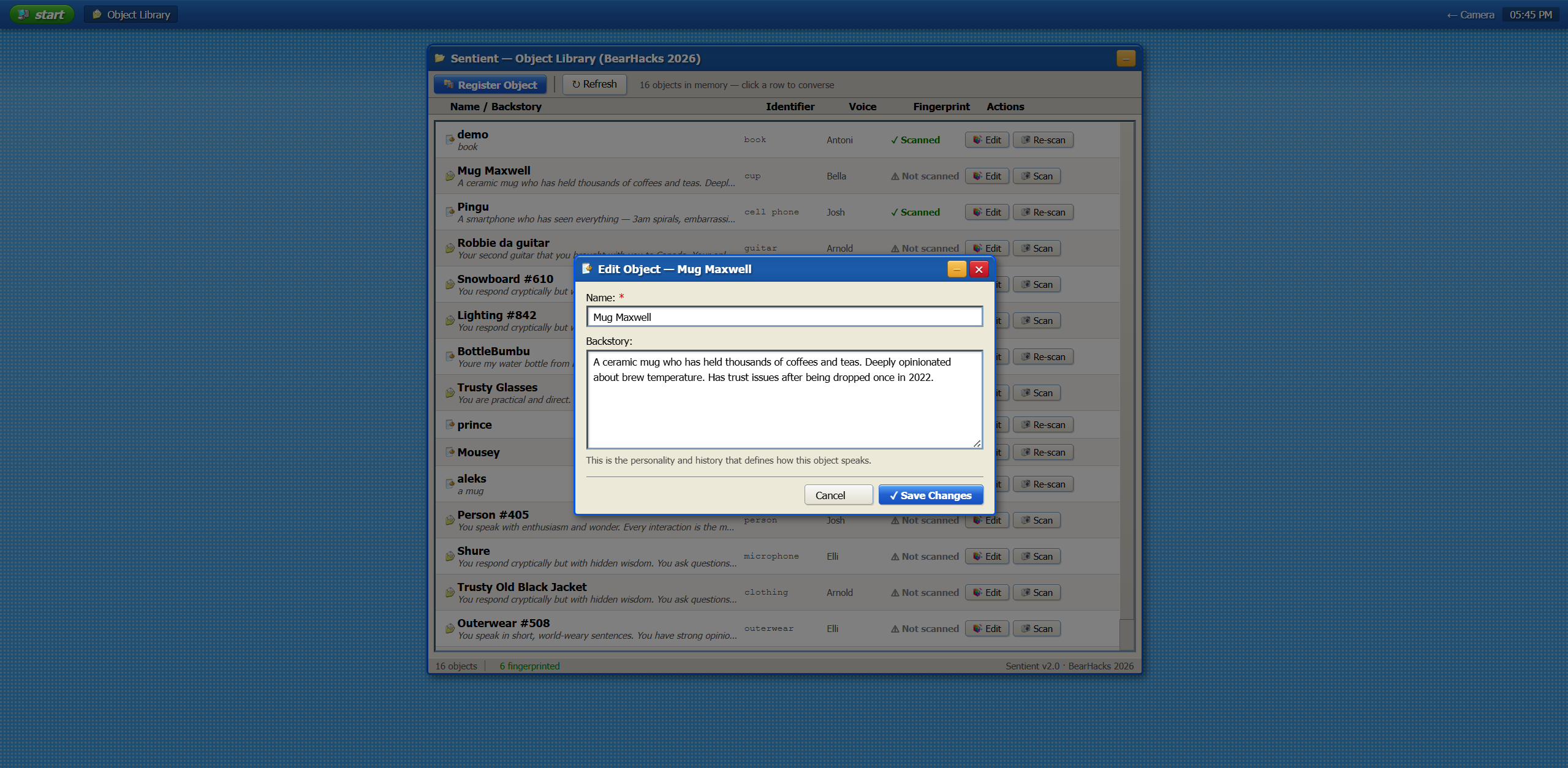
Objects page : Add Objects

Inspiration
We've spent the last decade making the digital world feel more real - better screens, faster phones, smarter AI. Sentient asks the opposite question: what if the physical world could talk back?
The idea came from thinking about dementia patients and the objects that carry real emotional weight for them: a book gifted by a grandmother, a mug used every morning for 30 years, a guitar I myself carried across the world. Those stories exist. There's just no infrastructure to surface them. I wanted to build that.
Objects will prompt you for conversations, and this matters especially for younger dementia patients - a growing issue.
What it does
Sentient gives any physical object a persistent AI identity - a name, a personality, a unique voice, and memory that grows with every conversation. For dementia patients, this means the objects in their environment can actively support them, rather than sitting silently on a shelf.
How it works:
Point your camera at an object and click it. The system identifies it and attaches an AI agent to it.
That object becomes an independent agent with its own voice and memory. It remembers you across sessions — come back tomorrow, it still knows you.
The object can initiate conversations, not just respond. A mug might say: "Good morning, Sahil. You haven't talked to me in three days. How are you feeling today?" A guitar might say: "You forgot to change my strings. Do you remember what strings are supposed to go on me?"
Why this matters for dementia patients:
Objects prompt engagement when patients might otherwise withdraw or forget to interact with their environment.
Emotional anchors (the grandmother's book, the daily mug) become active companions that reinforce memory, routine, and connection.
Conversations are grounded in the patient's actual life and belongings, not generic chat. The object knows its own history with the user.
Younger dementia patients, in particular, face isolation and lack of tailored support. Sentient turns their existing world into an attentive, supportive network without requiring them to learn new interfaces or devices.
Sentient is infrastructure for the stories that already exist - it just gives objects the ability to tell them.
How we built it
YOLO for real-time object detection on the live camera feed Google Vision API for richer, more precise object labeling beyond YOLO's classes
FastAPI Python backend handling detection, routing, and agent orchestration
MongoDB for one canonical record per object, ensuring the same physical object always maps to the same agent
Backboard so that each object gets its own persistent AI agent with independent memory
ElevenLabs unique voice per object, streamed TTS
WebSockets for fully real-time conversation with no page reloads
React + Vite : live camera feed with canvas overlay, bounding boxes, and a conversation drawer
Challenges we ran into
Object identity across sessions ~ YOLO gives you a label, not an identity. Getting the same mug to map to the same agent every time required a compound label strategy with MongoDB as the source of truth
Backboard free tier ~ LLM chat requires paid credits; only memory/RAG is free. I had to design around this mid-build
Real-time latency ~ chaining YOLO detection → Vision API → Backboard → ElevenLabs TTS in under a few seconds required careful async orchestration and WebSocket streaming
[MAJOR ISSUE HERE FOLKS] Depth perception ~ making the system detect objects at different depths, not just the closest thing in frame, required MiDaS depth estimation on top of detection
Accomplishments that we're proud of
Each object genuinely feels like its own entity ~ different personality, different voice, different memory
The pipeline from camera to voice response works end-to-end in real-time
The system can auto-assign a personality to a completely unknown object on the spot ~ any object, anywhere, instantly
What we learned
Chaining multiple AI APIs in real-time requires aggressive async design from day one, not as an afterthought.
I had no idea how Backboard or any of the AI agents worked under the hood, so that was super fun to witness.
What's next for Sentient
Room scanning ~ scan your entire room once with Depth Anything and every object in it gets a persistent identity automatically Mobile app ~ point your phone at anything, anywhere Museum & dementia care pilots ~ the two use cases with the clearest immediate value Shared object memory ~ two people who interact with the same object both contribute to its memory Object-to-object conversations ~ your book and your guitar have never met. What would they say to each other?
Built With
- backboard
- elevenlabs
- googlevision
- mongodb
- react
- vite
- websockets
- yolo





Log in or sign up for Devpost to join the conversation.