-
-
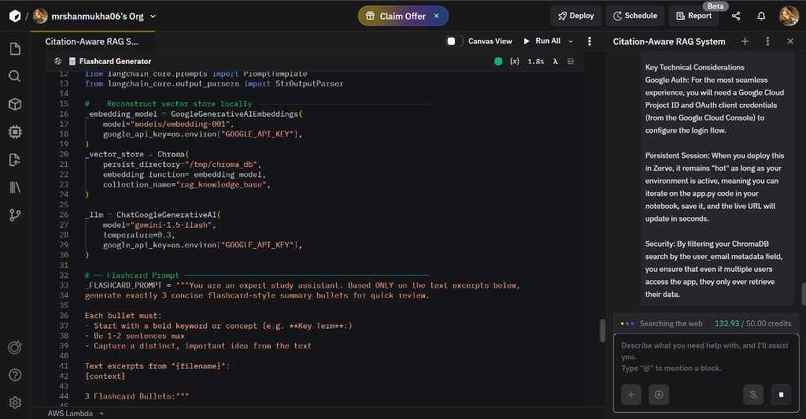
Working of the model
Sentience: An Autonomous Knowledge NavigatorThe InspirationIn an era of information density, the challenge isn't finding data—it’s retrieving the right insight without the "hallucination tax." Whether it’s navigating complex academic schemes or managing technical documentation for large-scale AI projects, I needed a system that doesn't just guess, but knows. Sentience was born from the desire to create a "second brain" that remains strictly grounded in verified data, providing a bridge between static archives and actionable intelligence.The Build ProcessThe project was built on the Zerve AI canvas to leverage its modular execution and context-aware agent. The architecture follows a robust RAG (Retrieval-Augmented Generation) pipeline:Ingestion: Raw documents (PDFs/Markdown) are broken down into manageable segments using recursive character splitting.Embedding: Text is converted into high-dimensional vectors. We use a dense vector representation $v \in \mathbb{R}^d$ where $d$ is the dimensionality of the embedding space.Vector Store: ChromaDB serves as the retrieval engine, utilizing Cosine Similarity to find relevant context. The similarity between a query vector $q$ and a document vector $d$ is calculated as:$$S_c(q, d) = \frac{q \cdot d}{|q| |d|}$$Generation: The retrieved context is fed into the Gemini API with a strict prompt constraint to ensure zero-shot accuracy.Challenges FacedThe biggest hurdle was "Contextual Drift." Early iterations struggled with chunking—too small, and the AI lost the narrative; too large, and the noise-to-signal ratio spiked. Refining the overlap parameters was essential to maintain semantic continuity.Another challenge was ensuring Citation Integrity. It wasn't enough for the AI to be right; it had to prove where it got the information. Implementing a source-tracing logic within the LangChain pipeline was critical to building user trust.Learnings & TakeawaysModular Infrastructure: Using Zerve taught me the value of a non-linear development environment. Being able to tweak the embedding logic without re-running the entire ingestion pipeline saved hours of compute time.Data Hygiene: A RAG system is only as good as the data it consumes. I learned that pre-processing and cleaning metadata is just as important as the model architecture itself.Precision over Creativity: In technical workflows, "creativity" is a bug, not a feature. Engineering prompts to force the model into a "strict-retrieval" mode was a masterclass in AI safety and reliability.Sentience isn't just a tool; it’s a commitment to grounded intelligence, turning massive data silos into a clear, conversational roadmap.
Built With
- an-efficient-local-vector-database.-mathematical-precision-is-achieved-through-google-generative-ai-embeddings-and-cosine-similarity-to-ensure-contextually-accurate-results
- chromadb
- creating-a-scalable
- google-gemini-api
- langchain
- modular-tech-stack-designed-for-high-performance-ai-retrieval:-the-project-is-primarily-built-with-python-within-the-zerve-ai-development-environment
- pypdf
- sentience:-python
- which-facilitates-seamless-notebook-based-orchestration.-core-logic-is-powered-by-langchain-for-pipeline-management
- which-feed-into-chromadb
- while-google-gemini-api-serves-as-the-primary-reasoning-engine.-data-ingestion-and-semantic-processing-are-handled-by-pypdf-and-recursivecharactertextsplitter
- zerve-ai

Log in or sign up for Devpost to join the conversation.