What it does:
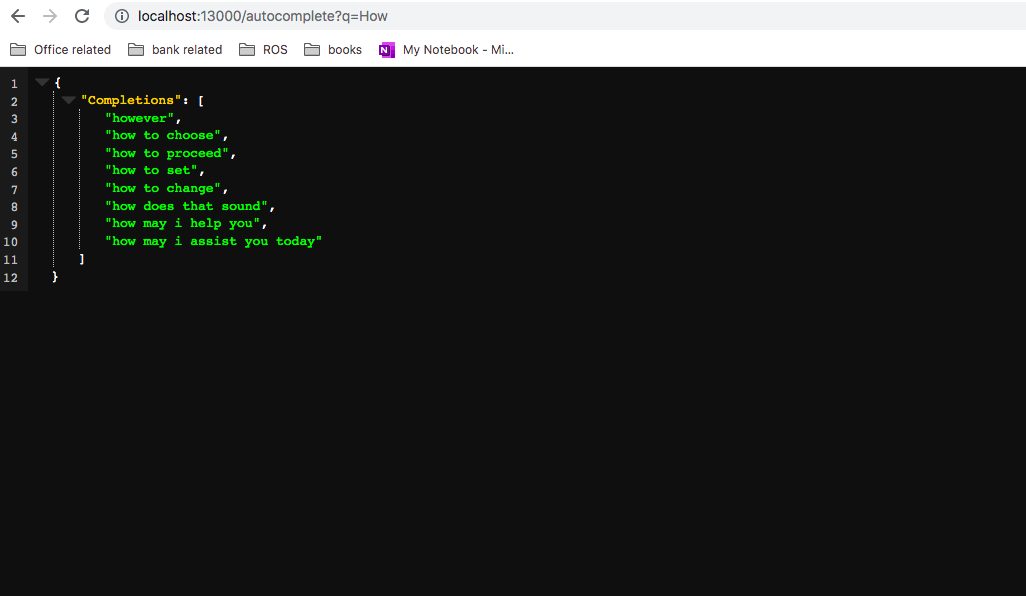
Trains the model with the dataset fed in to generate the predictions based on the input query.
How we built it:
Researched about probable language models which we could use, devised a pipeline which could meet the expected results; went ahead with training the model and using the trained output files to generate the required/expected outcome.
Challenges we ran into:
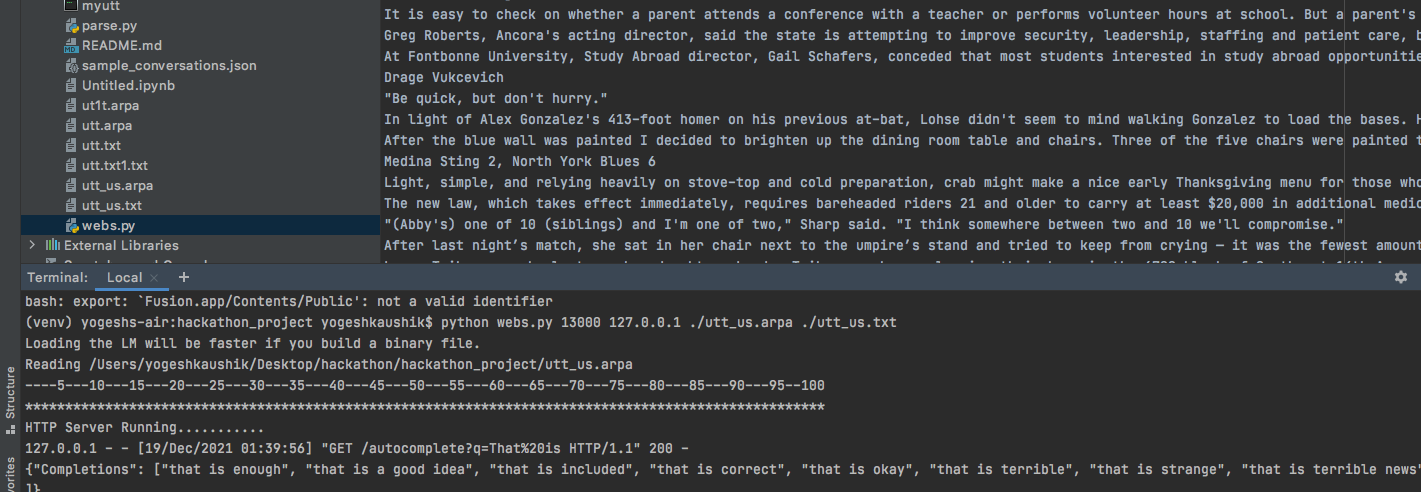
KenLM setup, Dataset creation and training
Accomplishments that we're proud of:
Successfully created a working model which meets the demands of problem statement.
What we learned:
We got a chance to learn about Ngrams, KenLM, nltk.
What's next for Sentence Completion using Ngram:
More accurate search results, pre-processing for spelling check, UI integration with Flask/FastAPI





Log in or sign up for Devpost to join the conversation.