











Inspiration
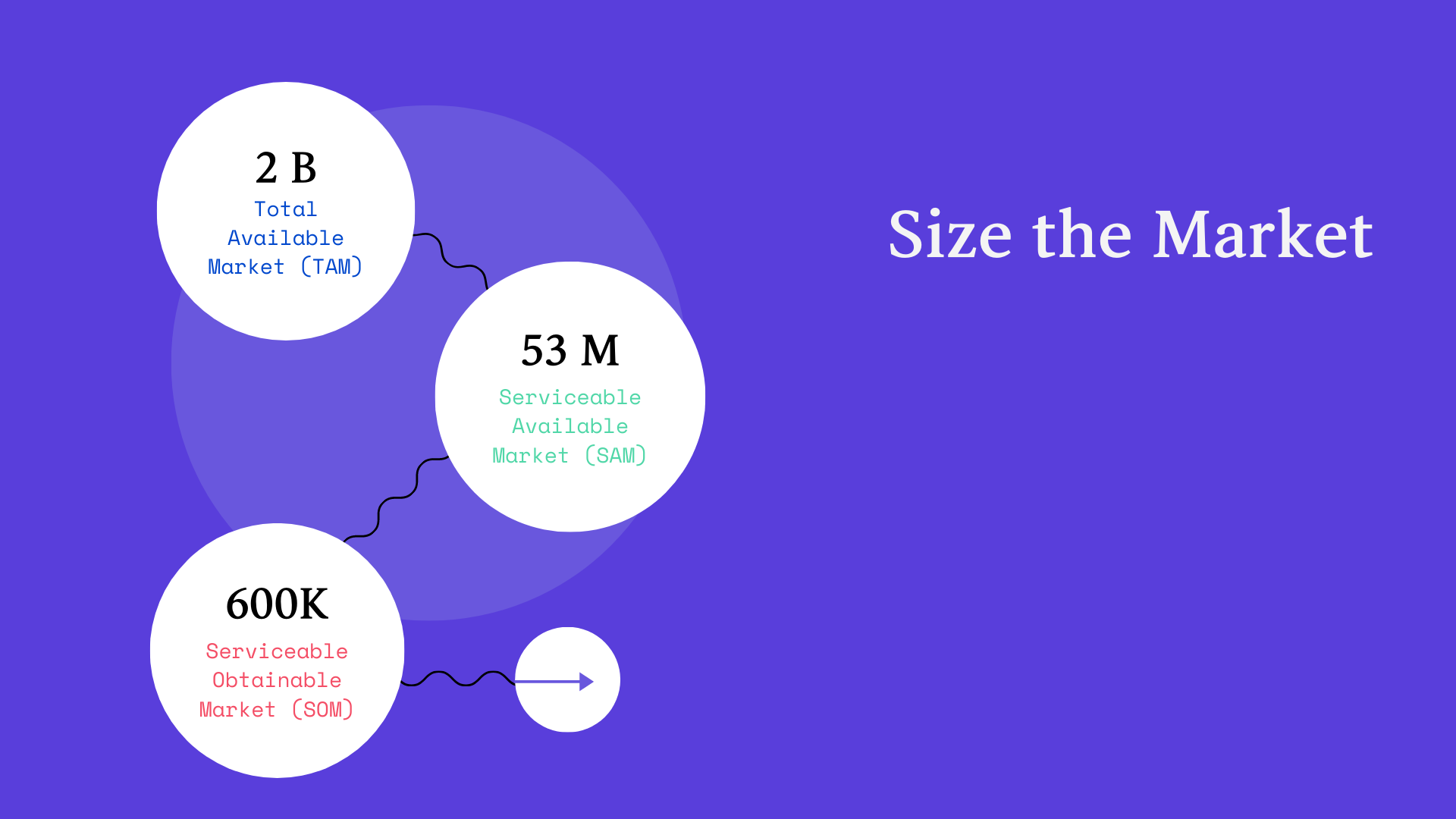
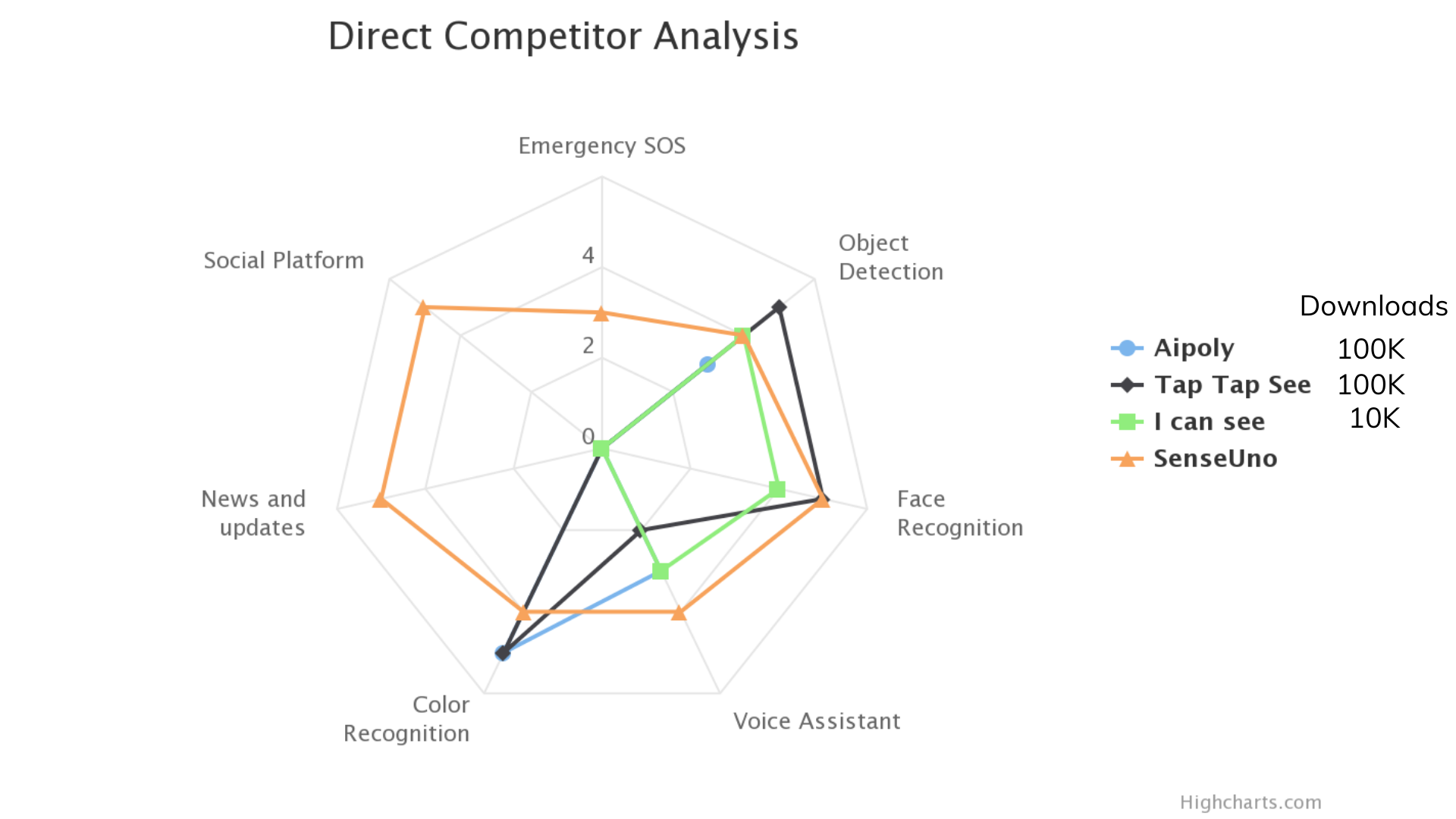
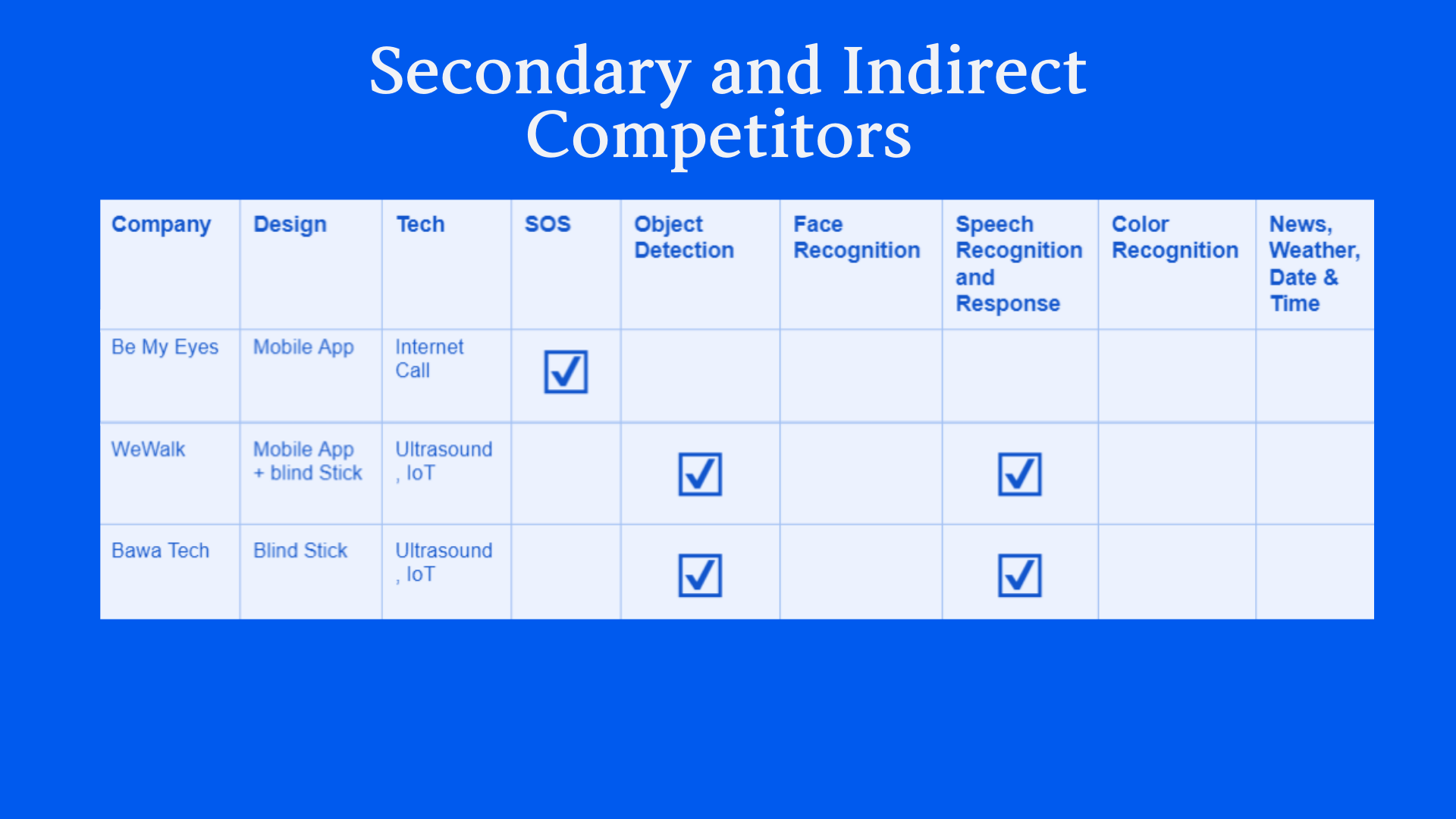
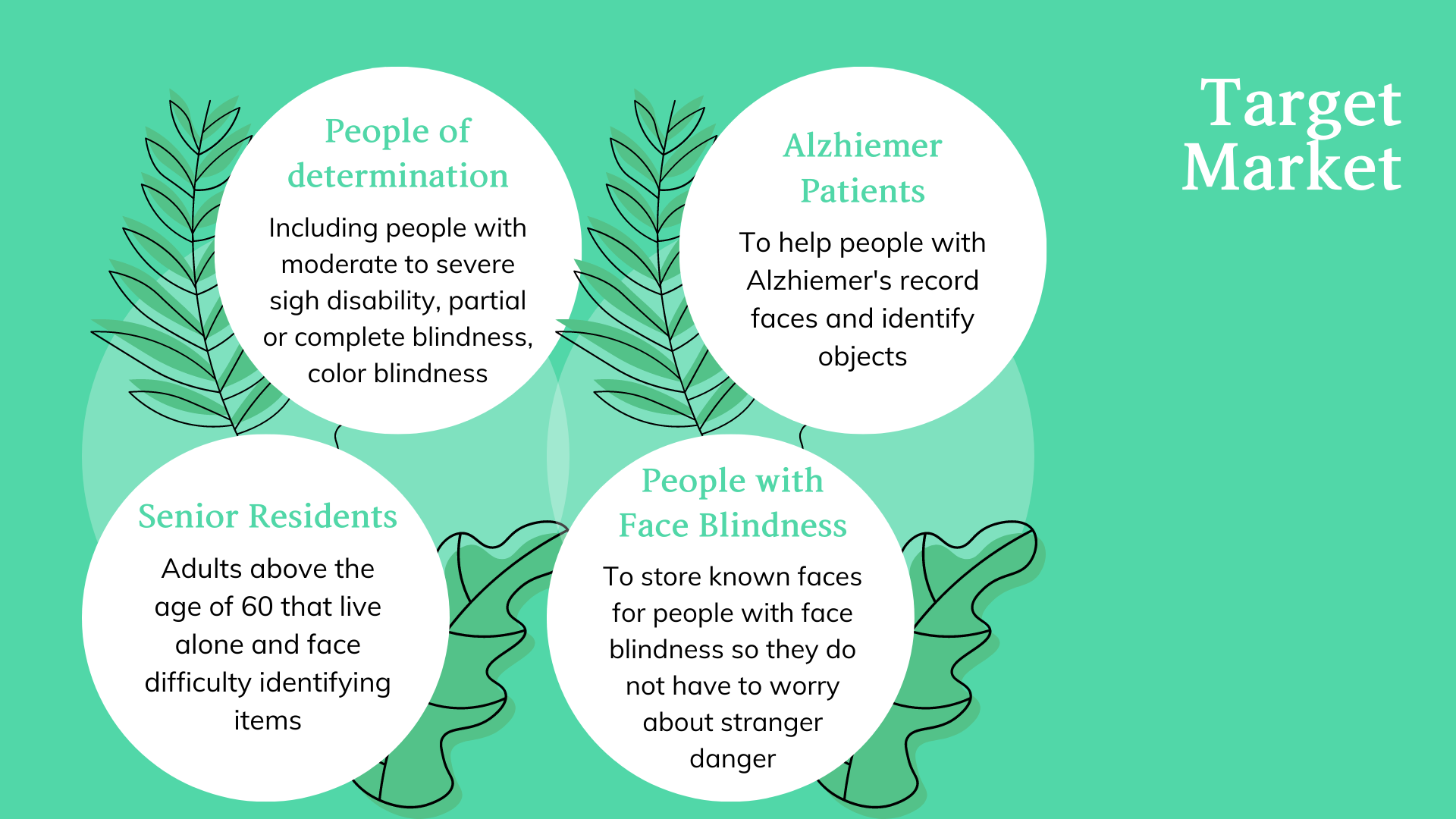
What happens when you hand a person with Visual Impairment (PVI) a smartphone? As the world continues to use smartphones, there is a growing awareness of developing more accessible applications for people of determination. Researchers suggest that mobile apps are influencing the social placement of people with VI (PVI), even within rural regions. However, there is a gap in the services offered and their accessibility. With over 2 billion people in the world facing visual impairment, this gap needs to be addressed to uplift the social and safety standards of people with VI.
Assistive technologies range from smart walking sticks to mobile apps. Assistive tech is predicted to grow by $8 billion dollars by 2025. However, this tech is still mainly accessible by funded institutions.
The inequity is far deeper than awareness and access. The research emphasized the effect of social disadvantage in increasing feelings of alienness and danger. This can be described as the inequalities that rise for PVI because their environment is not designed to accommodate their needs.
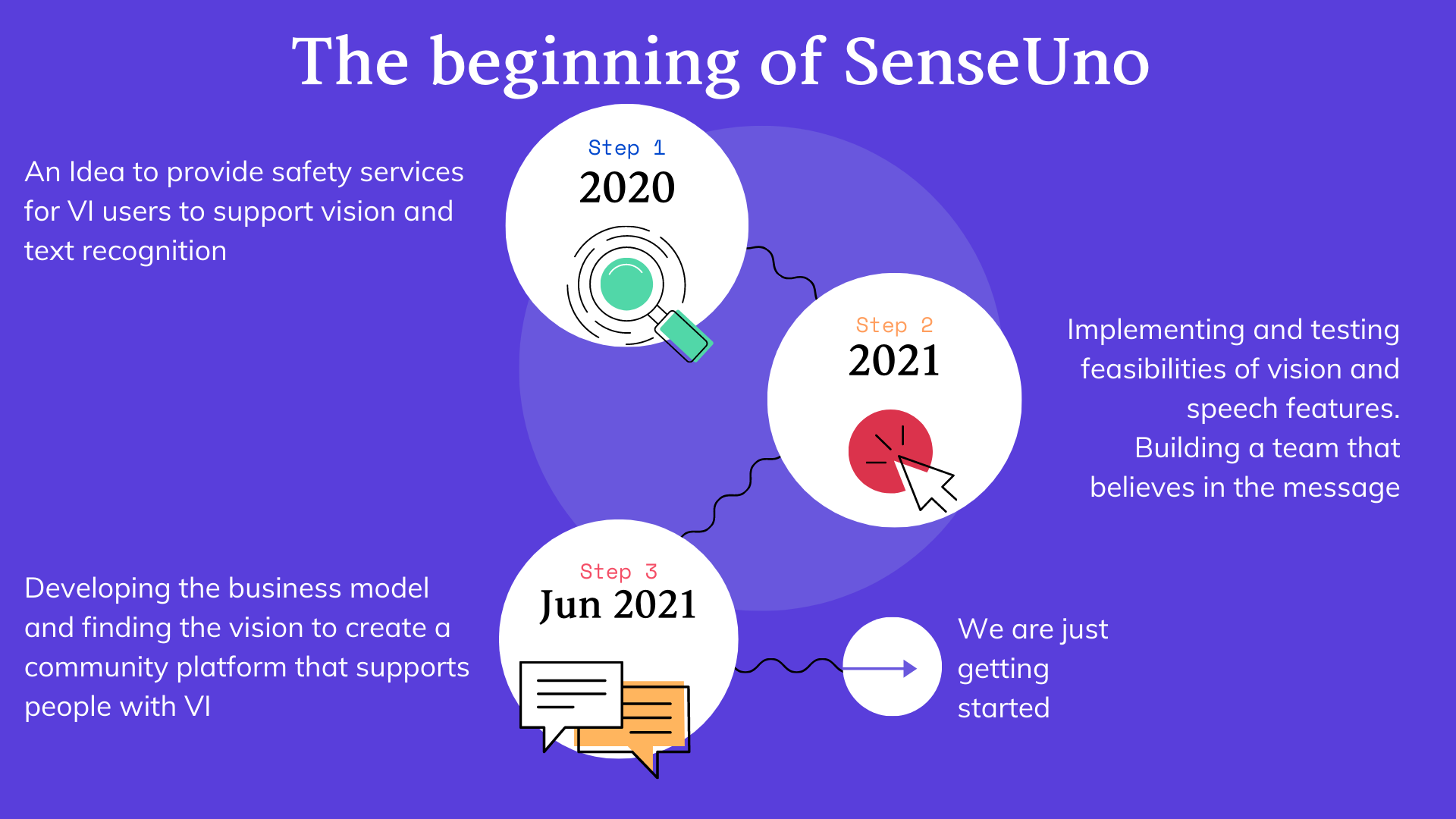
Hence, to address all these gaps in access and assistance for PVI, we designed a mobile application prototype made to assist their movement, named SenseUno to mimic their first sense: Sight.
What it does
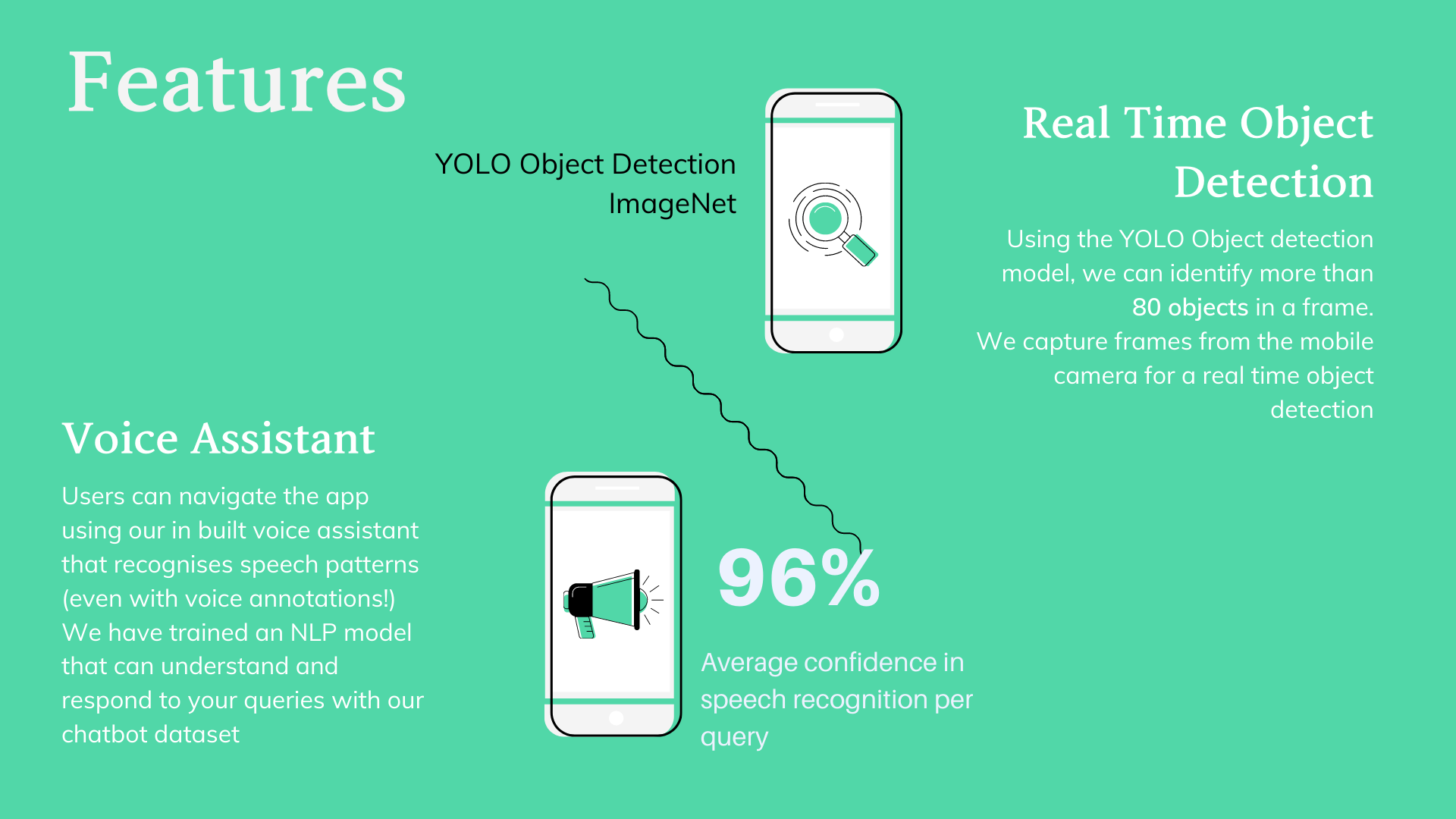
SenseUno is a movement assistance app that uses Computer Vision and NLP to help users identify objects and people in front of them using their phone camera. Users can ask questions about the description of an object, face, color, and weather, date, and time through this application. SenseUno can even identify and remember faces if requested. Furthermore, SenseUno will also provide a social platform designed specifically for PVI to help create and empower communities. Our solution is catered to make users feel like they have a companion, even alone.
How we built it
Using Computer Vision to perform object detection and face recognition. Object detection was carried out using You Only Look Once (YOLO), which is a real time object detection system based on Open Source Computer Vision (OpenCV). Detected details from the scene are stored into MySQL Database. The user interacts with the application via a speech input which converts audio input query to text using Automated Speech Recognition (ASR). RASA server accesses the database based on user’s query to produce descriptive information accomplishing Natural Language Generation (NLG) by generating meaningful phrases which are speech synthesized using Google Text To Speech (GTTS) API for VI user to hear.
Challenges we ran into
A challenge of this project was to balance the information delivery so as to support the VI user and not overpower them with object descriptions. The balance between information push and information pull was tested in user experiments and in the design of an Interaction Manager (IM) which best supports the user under various conditions.
Accomplishments that we're proud of
We were able to build a state-of-the-art machine learning model able to classify and describe objects surrounding the user, recognize speech as well as text, and also utilize Google text to speech engine to provide real-time updates as per the user's request.
What we learned
We learned how to use the industry-standard machine learning techniques and apply them to issues that people with VI face in their daily routines. We also learned to address the lack of independence using technology.
What's next for SenseUno
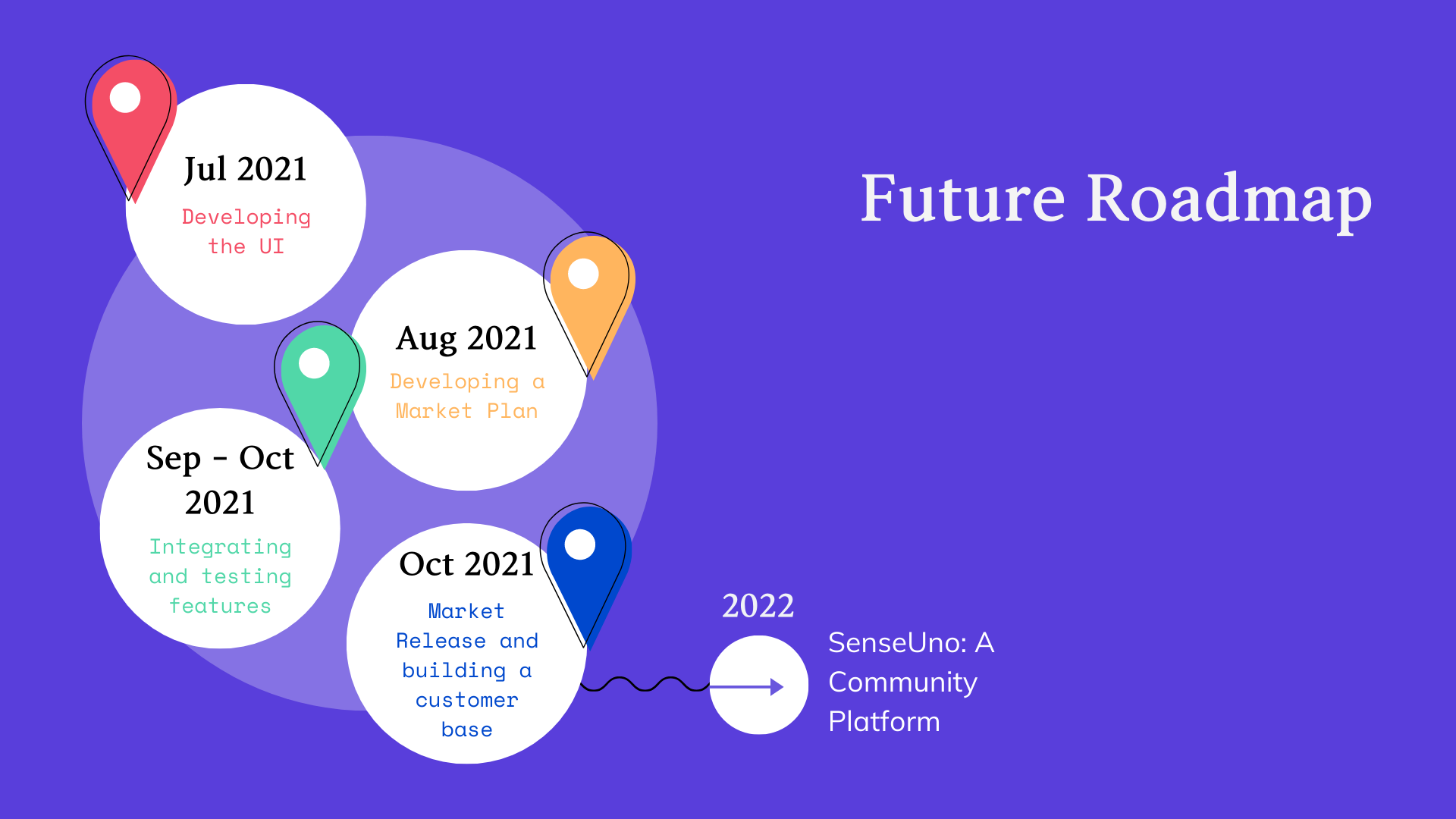
We aim to expand SenseUno for outdoor usages as well, further improving the independence of VI users. We also plan on diversifying our application by providing a social platform for users with other disabilities besides visual impairment.
Built With
- asr
- gtts
- html
- javascript
- mysql
- nlg
- opencv
- python
- rasa
- yolo



Log in or sign up for Devpost to join the conversation.