-
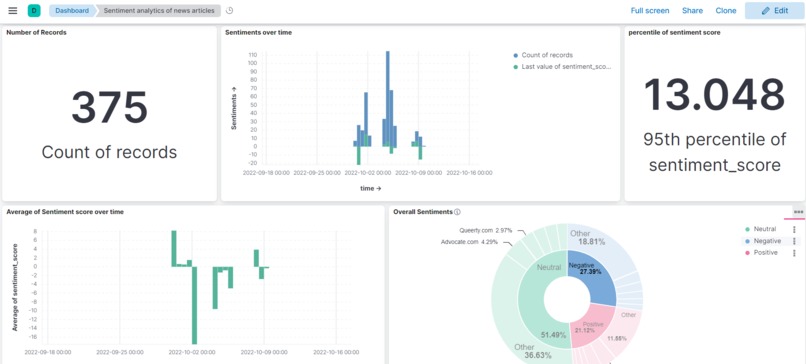
Dashboard preview
-
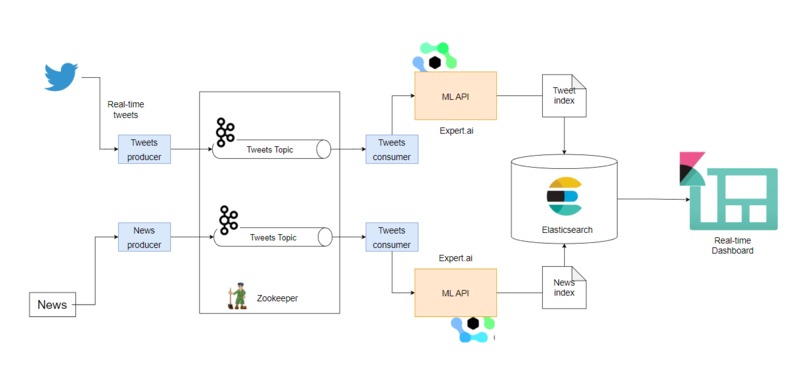
Project Architecture


The Goal
The project aims to detect hate speech against individuals, communities, organizations, company on social media and use that data for analytics. Along with hate speech, the project also focuses on sentiment analysis of news media articles about any of the above-mentioned entity and present the resultant data in a dashboard.
Project Architecture

- Data Producers: There are 2 producers, one producing Tweets and the other one is responsible for sending news articles. The producer services send the messages via a Kafka topic.
- Data Consumers: Like producers, there are 2 consumers. One for tweets and another for news articles. On the consumer, the Expert.ai NLP API is called for the classification and speech detection of the received messages. The classified data is then sent to the Elasticsearch indexes, that is used by Kibana for dashboarding.
- Apache Kafka: Has two topics, "topic-1" and "topic-2", each with 2 partitions and 2 replicas.
- Elasticsearch & Kibana: Two separate indexes for storing news articles and tweets. Kibana accesses the data for visualization.
Inspiration
While browsing the internet I came across some negative/abusive comments against a community. People from around the world were abusing the ones who are different, and who are not like us. It is okay if they are different but that doesn't give us the right to spread hate against them. Some people have learned to accept them, but many cases still register, related to racism, social abuse, and social media bullying.
So, I thought, why not make a real-time analytics pipeline where we can witness how a community or an individual is treated on social media and the internet? Using the obtained data and with the help of analytics, we can take effective measures against such actions and Make the world a better place.
What it does
The concept is simple. A pipeline that takes data from different sources, like Twitter, and news APIs, send them via Kafka brokers to an Elasticsearch index which Kibana finally uses for visual representation. These data can be further used for analytics and studying human behaviour on social media and the Internet.
The Expert.ai NL APIs play a major role in classifying and detecting the contents. The Sentiment Analysis and Hate speech detection APIs work on the data made available via Kafka and store the result in the Elasticsearch indexes.
The data from Elastcsearch is used by Kibana to visualize by the Data Science team to do further analytics and get valuable insights.
How I built it
- The main components are containerized using Docker. Thus, a single docker-compose command fires up the entire pipeline.
- Containers include "Apache Kafka", "Zookeeper", "Elasticsearch", and "Kibana".
- The producer and consumer services are built using "fastAPI".
- The Machine Learning section is handled by Expert.ai APIs. Includes Sentiment Analysis and the Hate-Speech detection algorithm. Expert.ai makes building the ML pipeline very easy and hassle-free.
Structure
Sender
| - producer.py
| - main.py
Receiver
| - consumer.py
| - model.py
| - elk.py
| - main.py
Sender: The main job is to send the data (message) via Apache Kafka. The producer.py module handles Apache Kafka using the kafka-python package.
Receiver: This is where the majority of work takes place.
- The
consumer.pymodule handles the messages sent via Kafka. - The
model.pymodule takes care of the Expert.ai NL APIs. - The
elk.pymodule deals with the Elasticsearch using the elasticsearch package.
Expert.ai NL API
The Expert.ai API code is inside model.py. A Model class has been defined to handle all NL tasks.
class Model:
def __init__(self):
pass
def hate_speech(self, text):
# hate speech code
def sentiment_analysis(self, text):
# sentiment analysis code
The Hate Speech detector aims at detecting and classifying instances of direct hate speech delivered through private messages, comments, social media posts and other short texts.
The detector can identify three main categories of hate speech based on purpose:
- Personal insult
- Discrimination and harassment
- Threat and violence
Sentiment analysis is a type of document analysis that determines how positive or negative the text's tone is.
Tools used
- Twitter V2 API Tweepy
- NewsAPI
- Expert.ai
- Apache Kafka
- Elasticsearch
- Kibana
- Docker
What I learned
Before this project, I have never worked with real-time systems. I was only involved with handling ML models. But thanks to Expert.ai's hackathon, I have learned a lot about data ingestion pipelines and fundamentals of Data Engineering. Also, this is the first time where I got the chance to explore Apache Kafka and Elasticsearch. And after building this project, I now at least have an idea of why and how to deal with a data pipeline.
What's next for Sense Media
I want to make this a standalone tool. A tool that can be integrated with any project, irrespective of the tech stack. I want to make it modular so that one can quickly set up a real-time pipeline within no time.
Built With
- docker
- elasticsearch
- expertai
- fastapi
- kafka
- kibana
- python

Log in or sign up for Devpost to join the conversation.