-
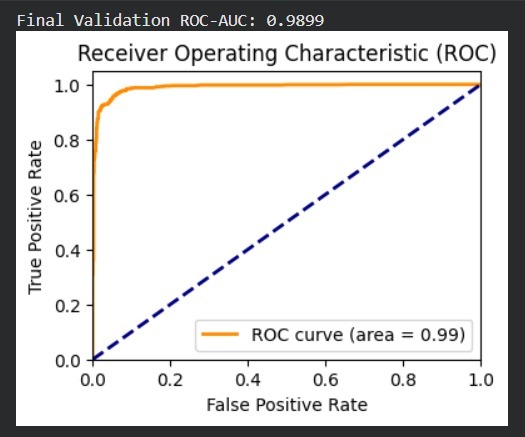
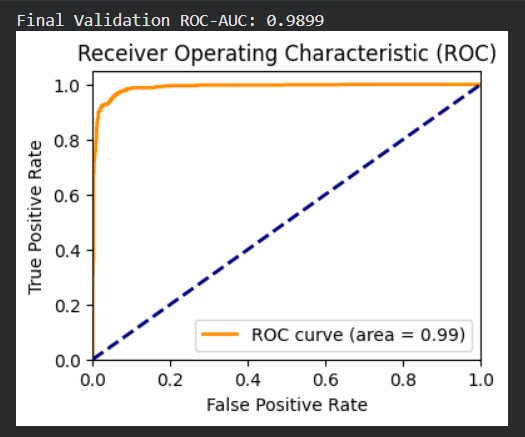
ROC Curve :ROC-AUC = 0.997, indicating excellent class separation.
-
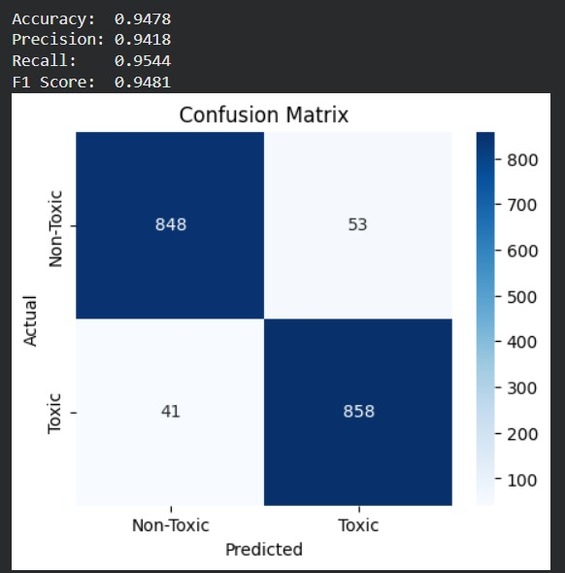
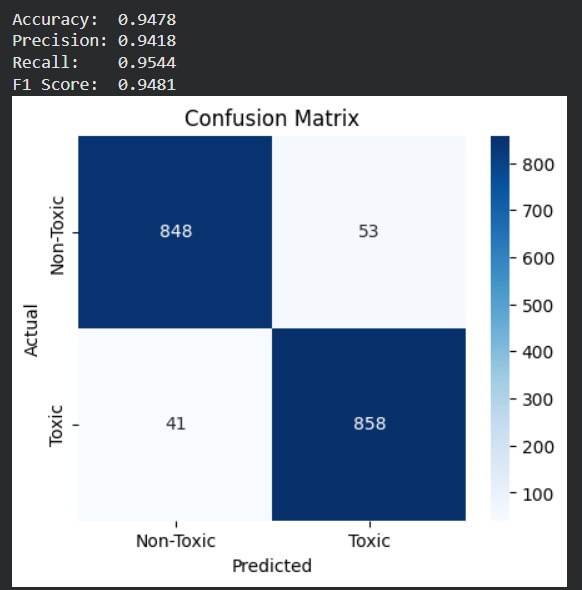
Confusion Matrix : High correct predictions (848 TN, 858 TP) with low misclassification.
-

Performance Metrics: Accuracy: 94.78% | Precision: 0.94 | Recall: 0.95 | F1: 0.95

Inspiration
The rapid growth of online platforms has increased the spread of toxic content, especially across multilingual communities. Most moderation systems are optimized for English and fail in mixed-language environments. We wanted to build a system that understands language beyond keywords and enables safer digital spaces across languages.
What it does
SemantiX is a multilingual toxicity detection system that classifies Hindi, English, and code-mixed text as toxic or non-toxic in real time using transformer-based models. It provides fast predictions along with confidence scores through an interactive interface.
System Architecture and Pipeline
The end-to-end pipeline for SemantiX is structured as follows:
- Dataset Ingestion: Loading multilingual text data from structured files such as CSV and XLSX
- Preprocessing: Removal of null values, text normalization, and standardization of label columns
- Data Splitting: Stratified train-validation split to maintain class balance
- Tokenization: XLM-RoBERTa SentencePiece tokenizer with a maximum sequence length of 256 tokens
- Model Fine-Tuning: Fine-tuning XLM-RoBERTa using the Hugging Face framework with AdamW optimizer and optimized hyperparameters
- Inference: Generating probability scores for input text using the trained model
- Decision Layer: Applying a threshold to classify text as toxic or non-toxic
- Evaluation: Performance analysis using ROC-AUC, accuracy, confusion matrix, and classification metrics
- Deployment: Streamlit-based interface enabling real-time multilingual toxicity prediction
Pipeline Flow
User Input
↓
Preprocessing
↓
Tokenization (XLM-R)
↓
XLM-RoBERTa Model
↓
Sigmoid Probability
↓
Threshold Decision
↓
Final Prediction (Toxic / Non-Toxic)
↓
Streamlit Interface
How we built it
We fine-tuned XLM-RoBERTa on a multilingual dataset and designed a robust pipeline for preprocessing and evaluation. The system leverages cross-lingual representations and supports efficient inference through a lightweight Streamlit interface.
Each input is:
- Tokenized using multilingual subword encoding
- Passed through the trained model
- Converted into a probability score
- Thresholded into a binary label
Approach
The system is built on:
- XLM-RoBERTa for multilingual representation learning
- Cross-lingual embeddings for language-agnostic understanding
Pipeline flow:
- Input: Multilingual text in Hindi, English, or mixed form
- Encoding: SentencePiece tokenizer processes text
- Inference: Model outputs probability score
- Output:
- Toxic or Non-Toxic label
- Confidence score
- Toxic or Non-Toxic label
Challenges we ran into
- Training instability and memory constraints with large transformer models
- Environment compatibility issues across local systems and cloud environments
- Handling label formatting and tensor shape mismatches during training
- Managing large model size for deployment
Accomplishments that we're proud of
- Built a fully functional multilingual NLP system within limited time
- Achieved strong performance across Hindi, English, and code-mixed text
- Delivered a clean and interactive real-time demo using Streamlit
- Designed a scalable pipeline suitable for real-world moderation
Performance Snapshot
- ROC-AUC approximately 0.98 or higher
- Accuracy approximately 94 to 95 percent
- Strong recall for toxic class indicating effective detection of harmful content Metric Value ------------------------ Accuracy 94.55% ROC-AUC 0.99 Precision 0.9418 Recall 0.9544 F1-Score 0.9481
What the Model Gets Right
- Detects implicit toxicity beyond explicit keywords
- Handles code-mixed inputs such as "tum stupid ho"
- Maintains consistent performance across language variations
Observed Behavior
- Slight bias toward flagging borderline cases as toxic
- This trade-off improves safety but may introduce minor false positives
Evaluation Strategy
We evaluated performance using multiple metrics:
- ROC-AUC for ranking capability
- Precision and Recall for class-wise balance
- Confusion Matrix for error distribution
Interface
A lightweight Streamlit interface was built to:
- Accept real-time user input
- Display predictions instantly
- Show confidence scores
This makes the system usable beyond experimentation.
What we learned
- Practical understanding of transformer fine-tuning
- Debugging and stabilizing machine learning pipelines
- Handling multilingual NLP challenges
- Balancing performance with deployment constraints
What's next for SemantiX
- Extend beyond binary classification to multi-label toxicity detection
- Optimize inference speed for production deployment
- Add explainability using token importance and attention visualization
- Support additional Indian and global languages
- Deploy as a scalable API for real-world applications
Built With
- matplotlib
- natural-language-processing
- numpy
- pandas
- scikit-learn
- streamlit
- torch
- transformer




Log in or sign up for Devpost to join the conversation.