-
-
Minimalistics draft design
-

-
-
-
-
-

About the Project — Semantiq
Inspiration
Semantiq was inspired by a critical limitation we encountered in educational data:
most curriculum alignment systems assume that training and testing data share the same standards. At the Rice Datathon, we discovered something much harder — our datasets had zero overlapping standards.
- Training data: algebra, functions, statistics (96 standards)
- Testing data: geometry, number systems (15 standards)
- Overlap: 0 standards
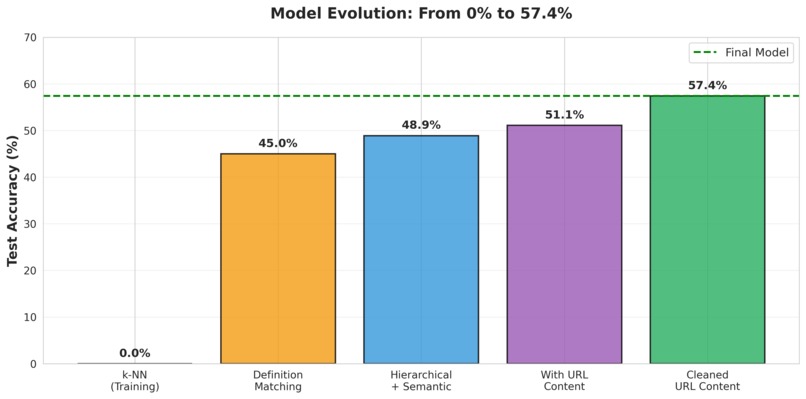
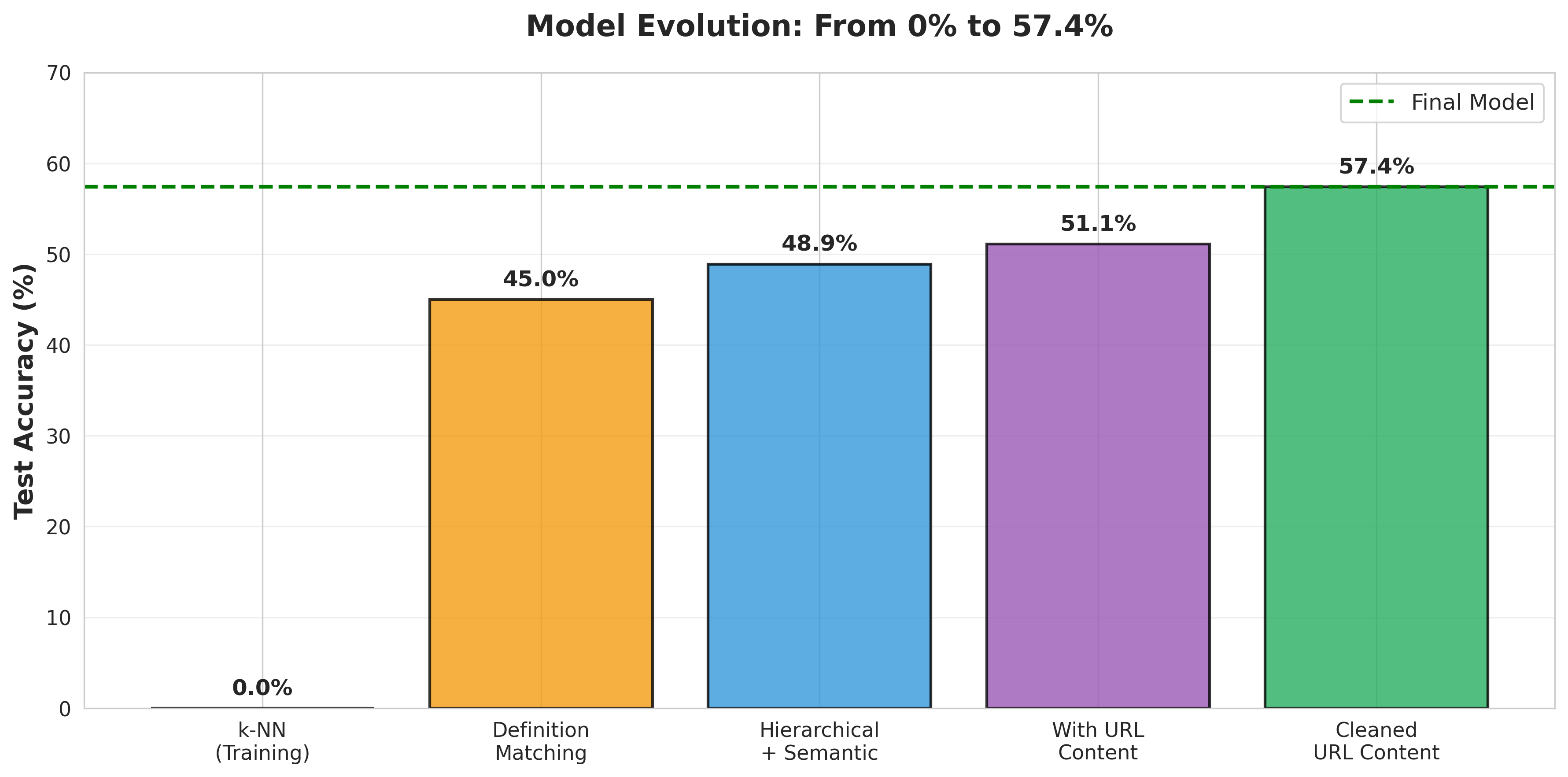
Traditional supervised machine learning completely failed (0% accuracy).
This forced us to rethink the problem and ask a new question:
Can AI align educational content to standards it has never seen before?
That question became the foundation of Semantiq.
What We Learned
Building Semantiq taught us several key lessons:
Zero-shot learning is not optional in real education data.
Standards evolve, differ by region, and rarely overlap cleanly. Systems must generalize beyond training labels.Semantic understanding beats surface-level matching.
Simple keyword models failed, while semantic embeddings captured real meaning — even across domains.Hierarchy matters.
Educational standards are structured. By filtering candidates using hierarchy before semantic matching, we significantly improved accuracy.Errors can be intelligent.
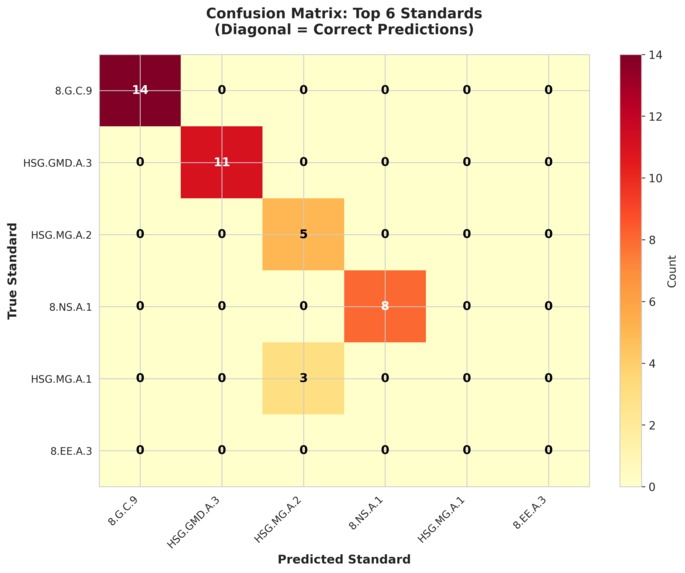
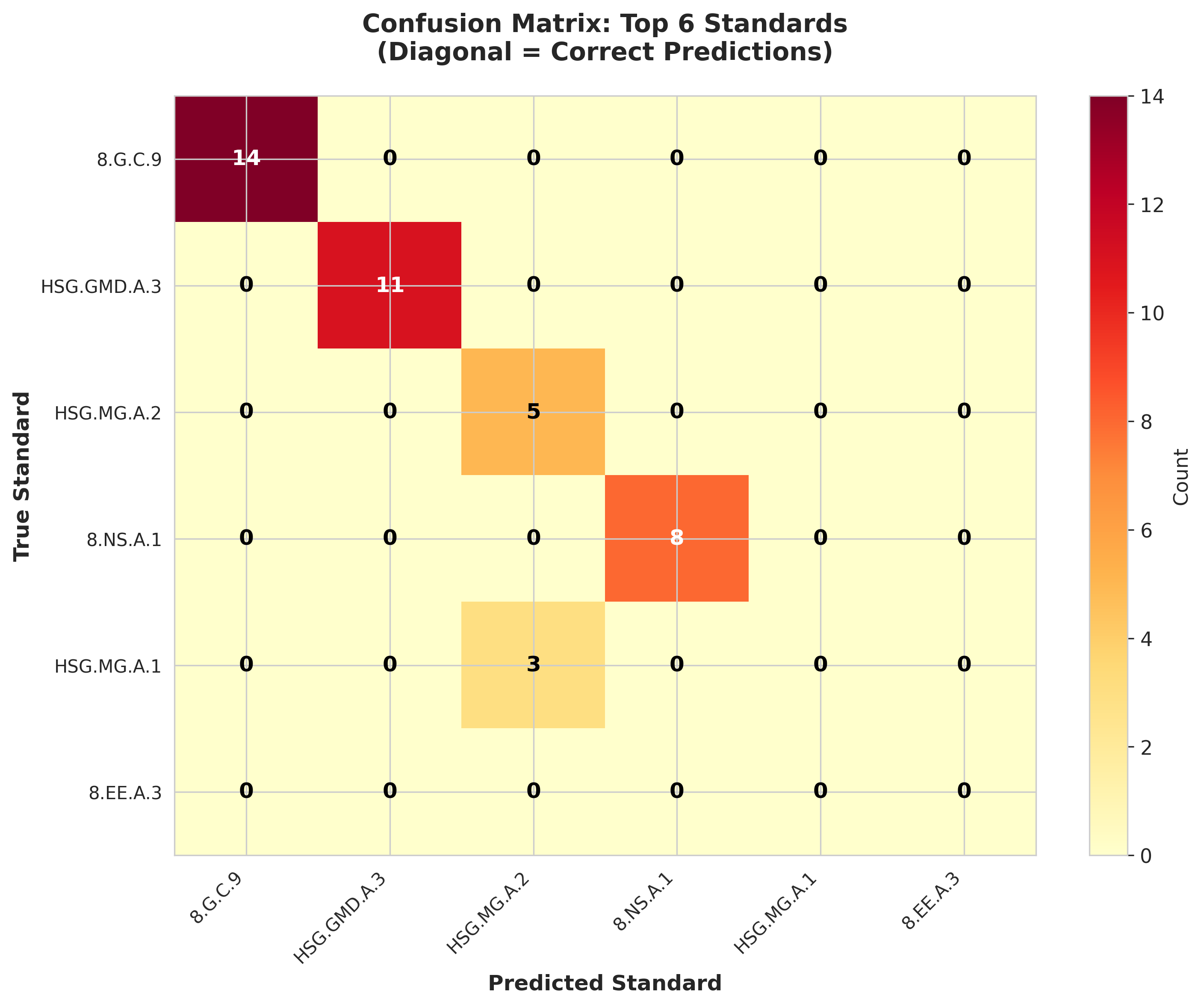
Our model never confused geometry with algebra — mistakes happened only between semantically similar standards, proving real understanding.
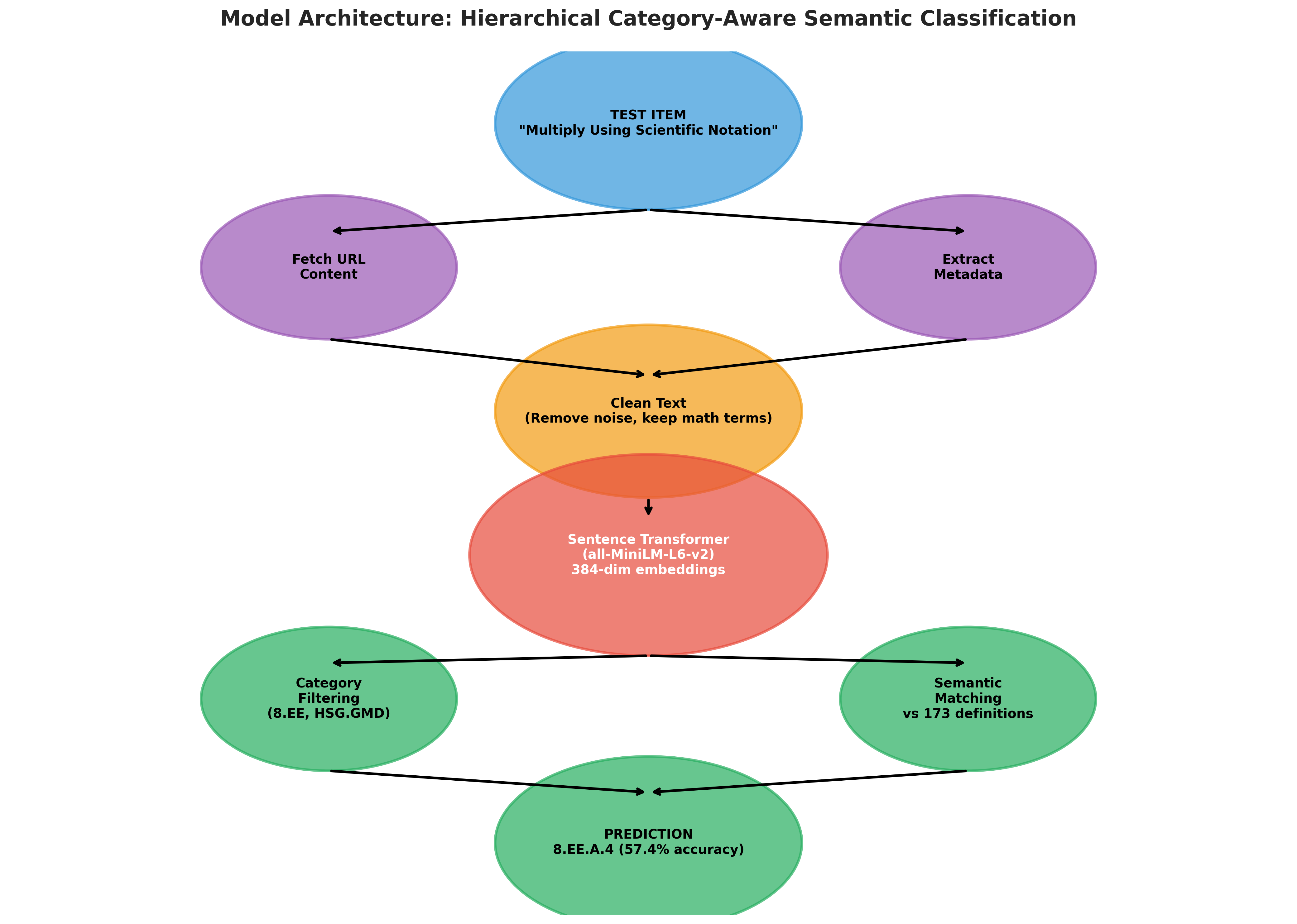
How We Built It
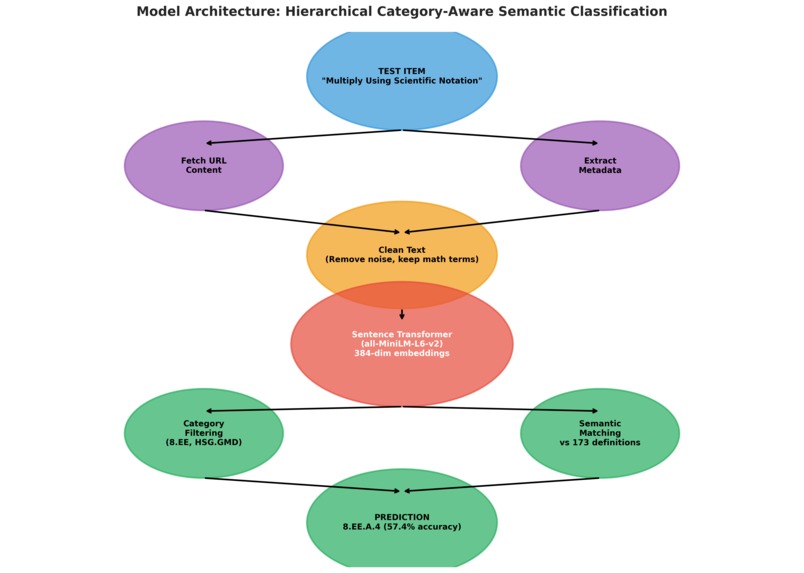
Semantiq is a zero-shot semantic classification pipeline designed to align textbook content with learning standards — even when no labeled examples exist.
1. Content Collection
We enriched each textbook item by fetching its full online content:
- title
- description
- cluster context
- full page text (via web scraping)
This gave the model enough semantic signal to reason beyond short labels.
2. Smart Text Cleaning
Raw pages were extremely noisy. We built a cleaning pipeline that:
- removed 100+ common noise words
- preserved 80+ math-specific terms
- reduced text length while increasing signal
This step alone improved accuracy by over 6%.
3. Semantic Embeddings
We encoded all content and standards using Sentence-BERT (all-MiniLM-L6-v2):
Each standard and each textbook item became a 384-dimensional vector representing meaning, not keywords.
4. Zero-Shot Matching
For each textbook item:
- We filtered standards by hierarchical prefix (e.g.,
8.EE) We computed cosine similarity between embeddings
We selected the closest standard as the prediction
This allowed us to classify previously unseen standards without any training examples.
Challenges We Faced
1. Zero Overlap Between Train and Test
Supervised models failed completely.
We had to redesign the system around semantic reasoning instead of learning labels.
2. Noisy Educational Text
Textbook pages contained ads, navigation, and irrelevant text.
Without aggressive cleaning, embeddings were unusable.
3. Similar Standards
Some standards differ only by operation (e.g., convert vs operate in scientific notation).
These cases remain challenging even for strong language models.
Final Result
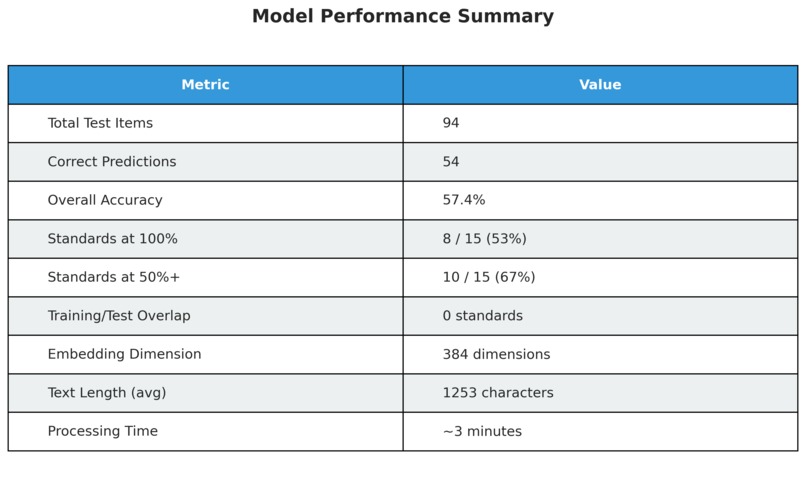
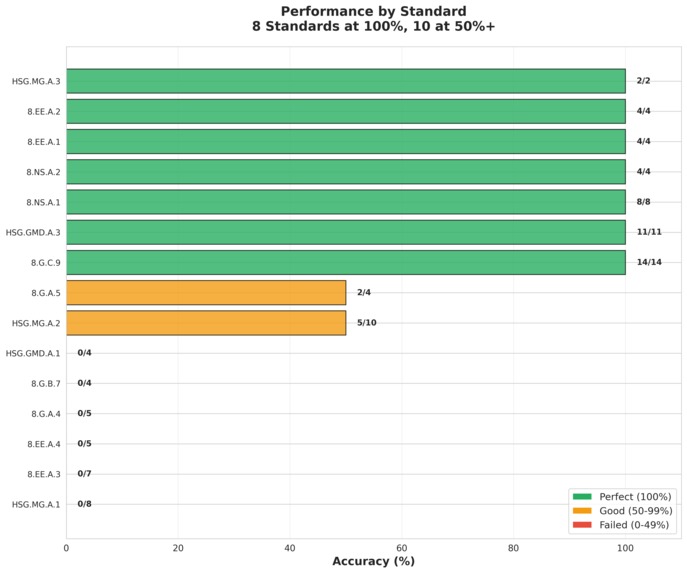
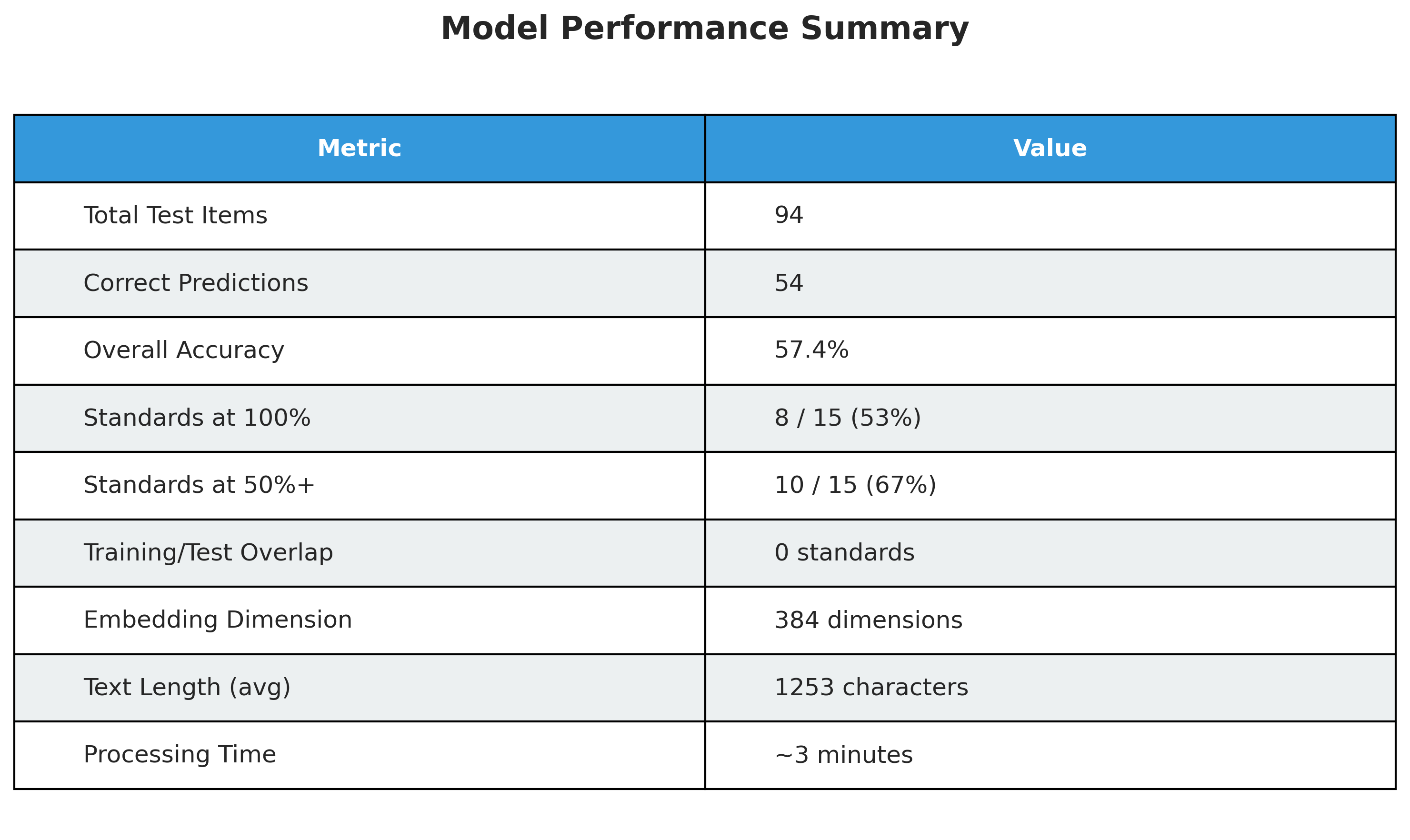
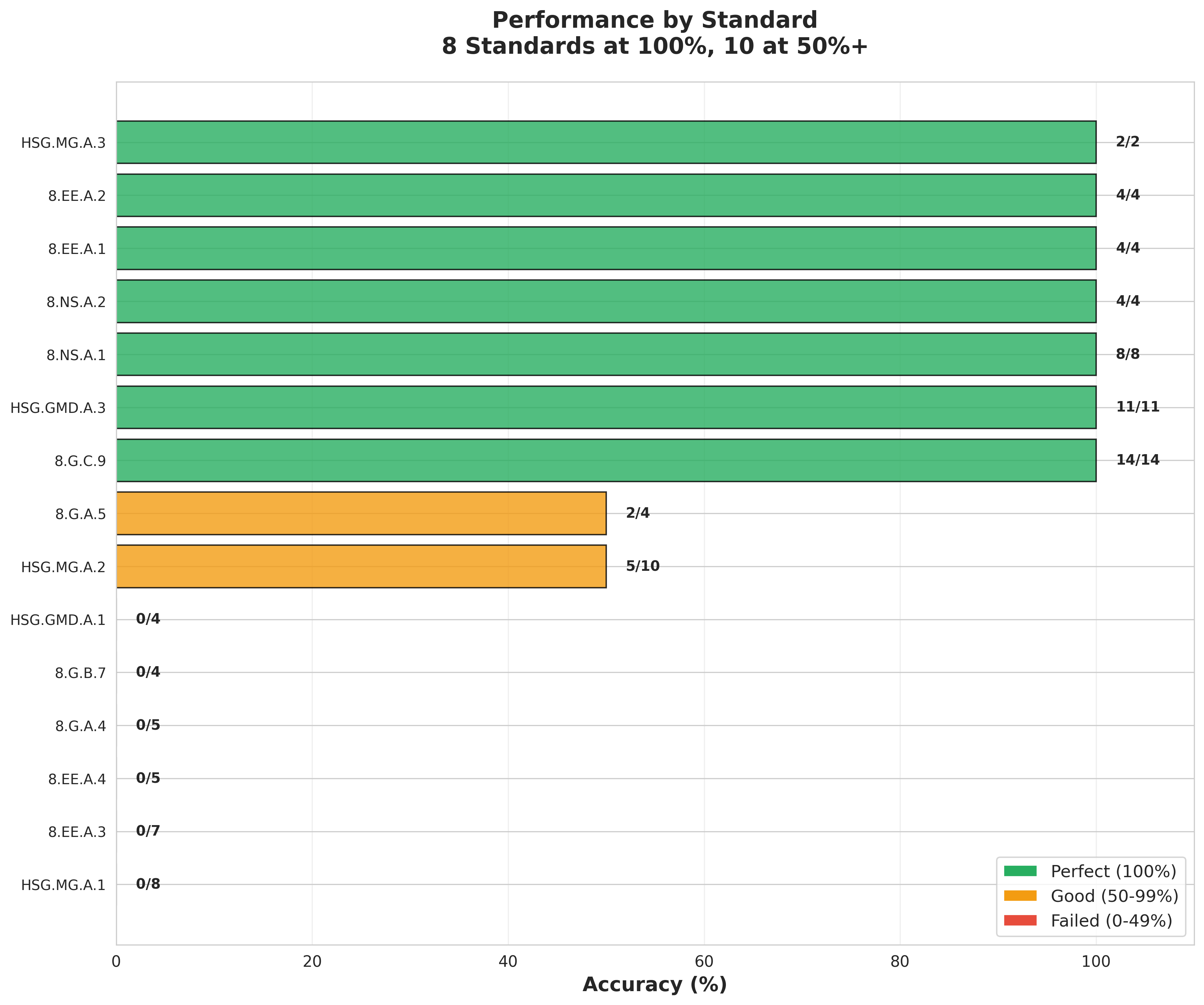
Despite having zero training examples for all test standards, Semantiq achieved:
- 57.4% overall accuracy
- 8 standards with 100% accuracy
- 10 out of 15 standards with 50%+ accuracy
- 173 total possible standards
This demonstrated that semantic AI can align curriculum even under extreme domain shift.
Impact
Semantiq automates a task that normally takes weeks and reduces it to seconds.
- Saves teachers hours of manual work
- Enables scalable curriculum auditing
- Improves access to standards-aligned materials
- Supports under-resourced schools
We estimate a potential impact of 150,000 hours saved annually, equivalent to $7.5 million in educator time.
What’s Next
- MathML parsing for formula understanding
- Domain-specific fine-tuning
- Multi-modal learning (diagrams, figures)
- Active learning with teacher feedback
- Deployment for schools and publishers
Semantiq shows that when AI truly understands meaning, it can solve problems that labels alone never could.
Built With
- all-minilm-l6-v2
- csv
- github
- json
- python
- visual-studio




Log in or sign up for Devpost to join the conversation.