-
Libraries used by the program: Apache Spark, Stanford CoreNLP, and MIT Java Interface to the Princeton WordNet Lexical Database
-

A sample business insights, using: sbt "run -b \"Mon Ami Gabi\""
Inspiration
According to the U.S. Government:
https://www.sba.gov/sites/default/files/FAQ_Sept_2012.pdf
Small businesses make up: 99.7 percent of U.S. employer firms, 64 percent
of net new private-sector jobs,
and according to the U.S. Small Business & Entrepreneurship Council,
http://sbecouncil.org/about-us/facts-and-data/
In 2012, according to U.S. Census Bureau data, there were 5.73 million employer
firms in the U.S. Firms with fewer than 500 workers accounted for 99.7 percent
of those businesses, and businesses with less than 20 workers made up 89.6
percent. Add in the number of nonemployer businesses – there were 23.0 million
in 2013 – then the share of U.S. businesses with less than 20 workers increases
to 97.9 percent.
It is very important to know how technologies like Apache Spark can be used in the sphere of small businesses, since they represent 99.7 percent of U.S. employer firms, and have so much weight in the employment rate in the U.S. and thereafter, in society. Of course, Apache Spark can be as well used in big corporations.
There are many projects with Apache Spark that are able to analyze numerical data fast and with a very high level of precision. An example of one of those projects is, e.g.,
https://github.com/je-nunez/apache_spark
which does a segmentation analysis (K-Means clustering) on the numerical data provided by the 2014 Housing Survey from The Center for Microeconomic Data of the Federal Reserve Bank of New York. (This numerical data, in the input format of an Excel spreadsheet and available here: https://www.newyorkfed.org/medialibrary/interactives/sce/sce/downloads/data/FRBNY-SCE-Housing-Module-Public-Microdata-Complete.xlsx, is an example of the numerical data that Apache Spark can process, and even to higher scale to that provided in that survey of The Center for Microeconomic Data of the Federal Reserve Bank of New York.)
Apache Spark excels in analyzing multiple-dimensions of numerical data, doing numerical regressions, or mixed with categorical dimensions, doing classifications. As well, as shown in the paragraph below, clustering. It is a very capable Machine Learning Library, with Generalized Linear Regression, Logistic Regression, Random Forests, MultiLayer Perceptrons (MLPs), etc.
But this competition is about Apache Spark applied to businesses and the economy. On one hand, I, as an outsider to the business field, do not possess a big numerical dataset with detailed business operations in multiple dimensions, on which Apache Spark easily will excel. (I'm thinking in numerical datasets like the ones that can be obtained from Six-Sigma Quality assurance, or Total-Quality-Management, because these very detailed numerical datasets are internal to the company that feeds and owns them. I.e., these numerical, business operations, datasets are private.)
On the other hand, Apache Spark is not restricted to numerical (multi-dimensional) data, and, for small businesses, the main data is simple English text in the manner of business reviews, like in the Yelp dataset. For this, Spark is able to easily accommodate into its engine other very important systems like the Stanford CoreNLP library, and the MIT Java Interface to the Princeton WordNet Lexical Database. Spark is able to integrate its data to syntactic analysis executed by Stanford CoreNLP and semantic analysis done the MIT Java Interface to Princeton WordNet.
What it does
(I wanted to do a Graphical User Interface for the program, but it would have taken me time from Apache Spark, where is were I put most of my effort, and the other libraries used here. Besides, to add a GUI over this functionality, now that it works, doesn't seem to be complicated since the workload is taken mainly by Apache Spark, not a custom UI, which the program doesn't depend upon.)
This program has two different ways of running.
One is to get business insights for a given business in the Yelp academic database, using its -b option. For example:
sbt "run -b \"Earl of Sandwich\""
It will do a syntactical and semantical analysis of the Yelp reviews for that business and produce a report like this:
compound: roast beef (occurrences: 149)
compound: tomato soup (occurrences: 113)
amod: best sandwich (occurrences: 79)
amod: full montagu (occurrences: 64)
amod: long line (occurrences: 62)
amod: long lines (occurrences: 20)
amod: full montague (occurrences: 15)
dobj: get montagu (occurrences: 11)
so we know that, for Earl of Sandwich, people were recommending specifically their roast beef, tomato soup, and the full montagu, and they were complaining about long lines. These insights are meaningful for the (small) business owner, because they summarize what people do appreciate of the business, and more, than these summaries are shorter than reading each review one by one. E.g., the Earl of Sandwich has 1957 5-stars reviews only, so reading them is time consuming, and probably a small business owner does not have time for reading them all. (As a side note, Yelp indicates that Earl of Sandwich -Las Vegas- has 4.5 stars average stars out of 5 maximum, and it is taken as an example here. I am not associated to that company nor have ever visited this business.)
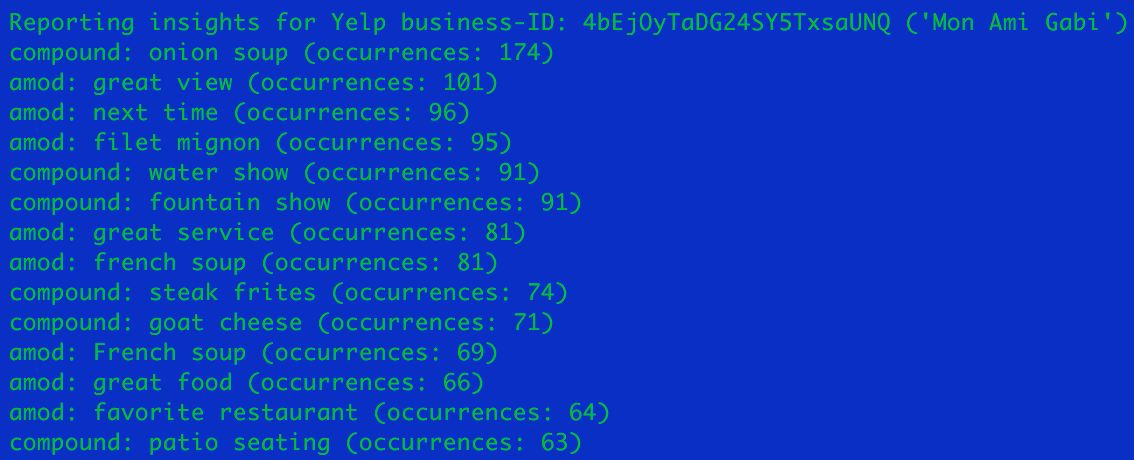
For example, in the image above in this page, it is seen the heading of the insights on another business, Mon Ami Gabi in Las Vegas (again, the argument to the -b option must be the exact business name as it appears in Yelp -this can be solved in the next version of the project):
sbt "run -b \"Mon Ami Gabi\""
where it can be seen that the preferences of the Yelp reviewers are:
compound: onion soup (occurrences: 174)
amod: great view (occurrences: 101)
amod: next time (occurrences: 96)
amod: filet mignon (occurrences: 95)
compound: water show (occurrences: 91)
compound: fountain show (occurrences: 91)
amod: great service (occurrences: 81)
amod: french soup (occurrences: 81)
compound: steak frites (occurrences: 74)
compound: goat cheese (occurrences: 71)
The second way to run this program is with the -c option, like:
sbt "run -c sandwich"
where it will try to find and rank the businesses in the Yelp database according as they provide sandwich or an hypernym of the word sandwich (e.g., snack_food). (An hypernym is the word whose meaning includes the meanings of other words, like the hypernym snack_food includes sandwich. The usefulness of hypernyms is that they offer an alternative -although with lower rank- if the main desire is not available in a geographical location. See below for more.) In general, the argument to pass to the -c option is what the customer is looking for. (In the example here, it was written that sandwich is what the customer is looking for.)
How I built it
This program has been written in Scala (and compiled for Scala version 2.10.6, Apache Spark version 1.6.2).
Apache Spark is able to import data from different sources and databases, and MongoDB is a good document database. So the Yelp academic dataset is imported into MongoDB, from which Apache Spark reads the business reviews and companies information.
This program defines a User-Defined-Function (UDF) to be run inside Apache Spark, and this UDF does a syntactic parsing of the text of the Yelp reviews using Stanford CoreNLP. It then uses the Part-Of-Speech (noun, adjective, verb, adverb, preposition, etc.) and the dependency parse tree that the syntactical analysis found, and passes some of them to the semantic analysis using the MIT Java Interface to Princeton WordNet. WordNet then finds the stems of the words and the lemmas, which then are returned by this Spark user-defined function and saved by Spark in a new dataframe.
The semantic part is used mainly for the satisfaction of a specific customer's desire,
sbt "run -c sandwiches"
because this semantic part does not do an exact string search. It takes the stem and lemma of the desire (in this case it would calculate that it is sandwich in singular), and then, using the semantical hypernyms of that word (e.g., snack_food, according to Princeton WordNet), will try to do a ranked matching of these terms in the Spark dataframe. I.e., if any semantic lemma in a Yelp review in the Spark dataframe matches the lemma of the desire requested, then it has a ranking value of 1.0. But if there is no direct match between the lemmas, then it tries to find if there is a match between the hypernyms of the business review and what the customer is currently desiring (e.g., in our example, if there is no exact match on the lemma sandwich, then it tries to find a match between the hypernyms snack_food), but if the hypernyms do intersect, then the ranking value is not 1.0, as in the case before an exact match of the real lemmas, but some ranking value between 0.0 and 1.0, and lesser than 1.0. This allows the program to say "hey, it doesn't seem that there are sandwich places around, but there is a very good snack_food place, with excellent reviews, that perhaps you are interested in visiting". Of course, as already said, the ranking value of a match on a semantic hypernym is less than 1.0, that is the ranking value of an exact match of the original, simple lemma requested.
Challenges I ran into
The first challenge was that the original version did not use CoreNLP nor WordNet, only tokenized the sentences into N-Grams of length between 1 and 6 words long, and did a topic (aspect) analysis of these N-Grams with a term frequency-inverse document frequency (TF-IDF), to see which N-Grams were more relevant, capturing more information. But a hashing Spark does in HashingTF is currently with private accessor in Scala, so it was able to calcula privately the TF-IDF of a word or N-Gram, but not to give which is the hashing value of an explicit word or N-Gram given by the user. Apache Spark is open-source, so I was able to find this hashing and incorporate in the UDF to select the most relevant words or N-Grams.
The second challenge was that, while this first version worked and gave insights, it was realized that if it knew which English words in the reviews were acting as nouns, which as adjectives, and other parts-of-the-speech, then their efficacy of their insights would increase. For this, the Stanford CoreNLP natural language processing library was introduced into this project to find the Part-Of-Speech of each word acts in a sentence. Apache Spark worked nicely with a User-Defined-Function that used Stanford CoreNLP.
A third challenge was the Apache Spark released a new version, 2.0.0, on July 26th, that it was tried to be used, but the current version of the MongoDB connector for Spark only works with Spark version 1.6.x, it hasn't been updated yet in this month to work with Spark 2.0.0.
The final challenge was the business relevance of this program. A simple English word, like soup, may give insight to a business owner, but if it is a compound word a reviewer has written, like tomato soup, or cranberry sauce, or Hawaiian BBQ, chicken avocado, etc., or with adjectives, long line, best sandwich, etc., it gives greater insight to him. For this, the dependency tree-parser of Stanford CoreNLP was introduced in the Spark User-Defined-Function, and in order that a customer could request any desire to the program without using exact matches but semantical (hypernym) matches, the MIT Interface to the Princeton WordNet Lexical Database was introduced into the Spark UDF as well.
Accomplishments that I'm proud of
The combination of Apache Spark, MongoDB, Stanford CoreNLP, and the MIT JWI Interface to Princeton WordNet worked in a User-Defined-Function inside Spark.
The program is able to give business insights given the Yelp reviews, like the ones above for the business Earl of Sandwich.
What I learned
I learned the three of them, Apache Spark, Stanford CoreNLP and MIT/Princeton WordNet. The first I knew something, but not at this level. Of the others two, I didn't know about them.
I witnessed how powerful, stable, fast and extensible Apache Spark is. How Stanford CoreNLP and MIT/Princeton WordNet advance the field of natural language processing.
What's next for SemanticWorld
Make the option of satisfying a customer's desire faster. The issue is that the it is searching the entire Yelp academic database, which is big and has businesses all over the country, to calculate the ranking of each business reviewed in Yelp and see which are the businesses that satisfy that desire -although the business be in other side of the country. This is unnecessary. To solve this issue, a geographical location query to MongoDB can be given, i.e., analyze only those businesses which are within a certain distance from a geolocation. Two command-line options can be given to the program, --latitude and --longitude, to restrict the search to this geographical neighbourhood only. (Yelp does have in its database the exact latitude and longitude of each business in the review.) This can be done with MongoDB's geospatial query, explained here https://docs.mongodb.com/manual/reference/operator/query-geospatial/.
Another enhancement is to gather a longer combination of related words because they can give greater business insight. So far it is using two words, which is good, but perhaps three could be better. (On the other hand, for summarizing information in a short time to a business owner, two words might be more efficacious than three.) But for doing three-words phrases, subtrees comprehension in the dependency parse tree given by Stanford CoreNLP are necessary. To do this is possible, but requires the analysis of more cases for their relevance, e.g., when a subtree is an adjective and a noun, and the other subtree is a verb and that same noon, then: when this longer subtree with three words is relevant and when isn't? does it matter if the position of the verb is before or after the adjective? These are cases to analyze.
Another interest is the use of custom Named Entity Taggers (NERs) in Stanford CoreNLP. These are annotations that can give insight as well, but are local domains of expertise. (I.e., NERs are like private data dimensions defined by each business for its internal use, they are not like the hypernyms in Princeton WordNet, which apply to all the usual English language.) Stanford CoreNLP NERs are useful because they can allow each business to define their own data dimensions over the text of the review.

Log in or sign up for Devpost to join the conversation.