-
-
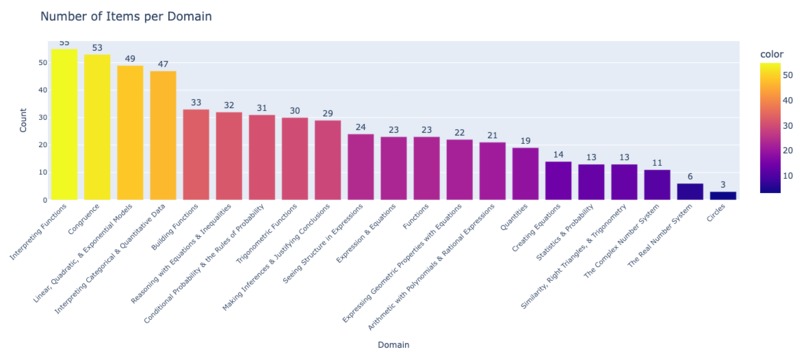
Course Domain
-
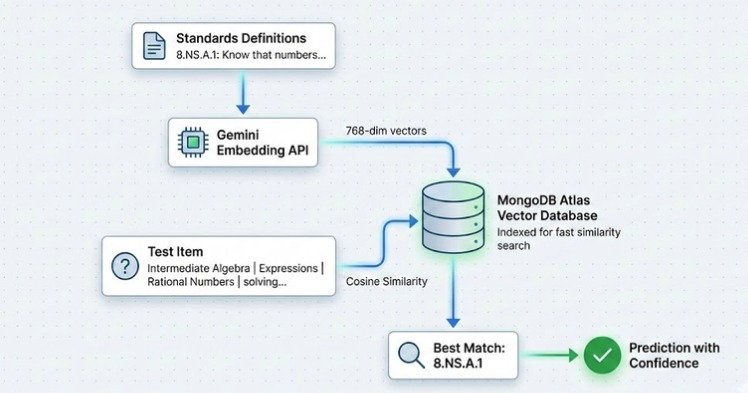
System Architecture
-
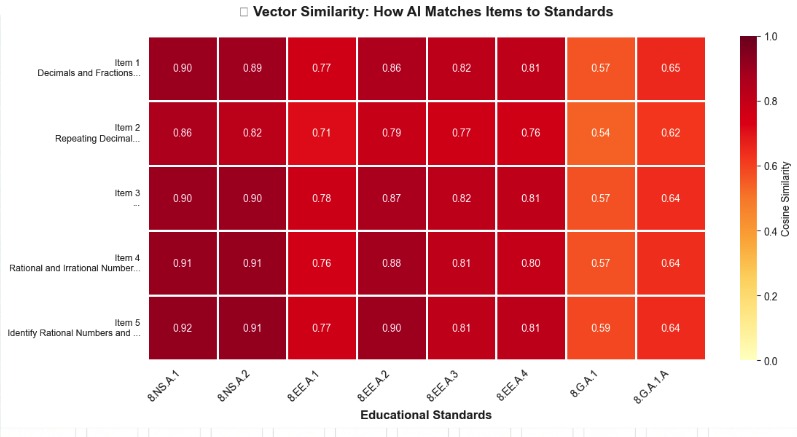
Vector Similarity
-
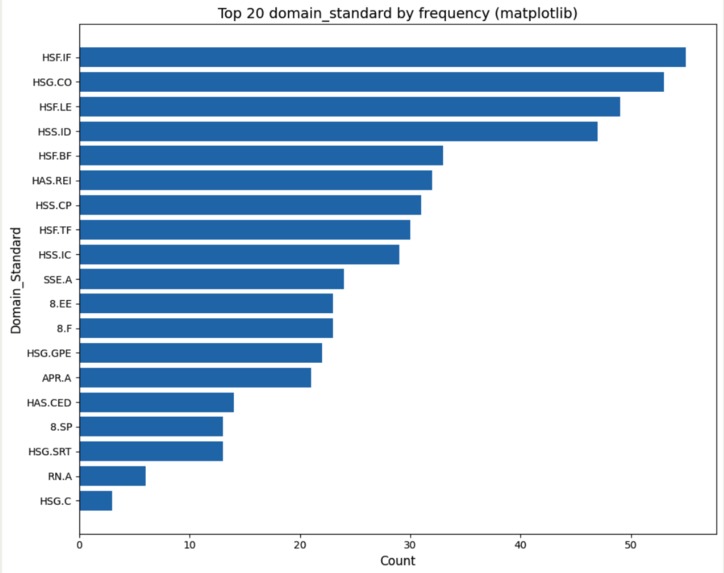
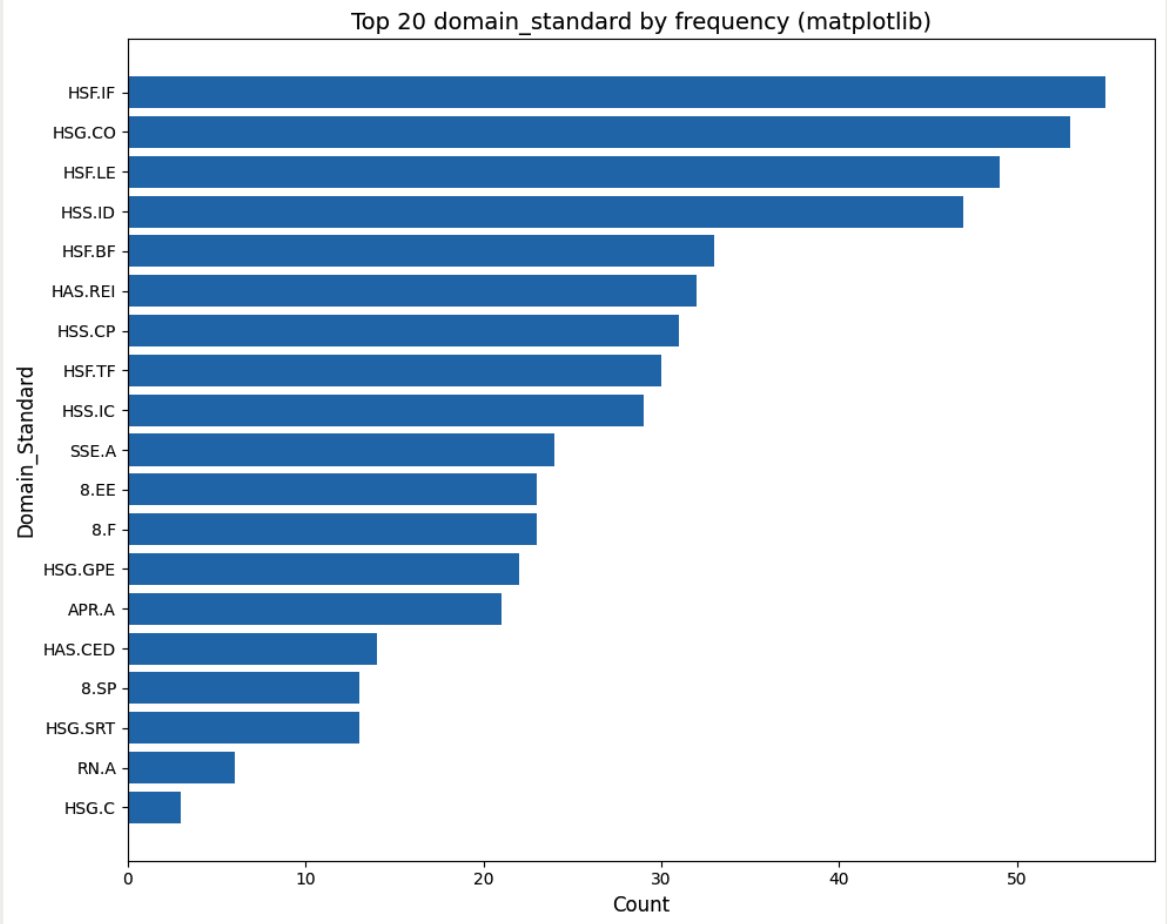
Domain Standard
-
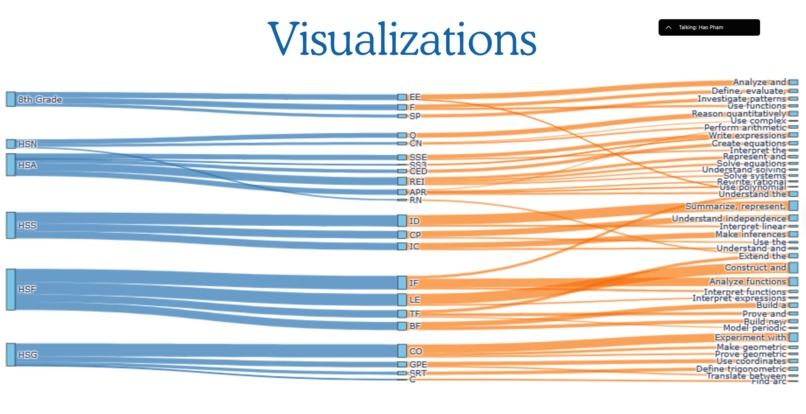
Data Visuallization
Inspiration
SVSearch was born from a critical challenge in educational technology: how do we automatically align millions of open educational resources with curriculum standards at scale? OpenStax, serving 18 million students worldwide, faces a monumental task, manually tagging thousands of textbook sections with educational standards.
For Rice Datathon 2026's Education Track, our team asked: What if AI could understand educational content semantically, not just match keywords? SVSearch is our answer: a zero-shot semantic classifier that achieves 30.85% Top-1 accuracy and 57.45% Top-3 accuracy without requiring any training data, revolutionizing how educational content gets aligned with curriculum standards
What it does
SVSearch is an intelligent standards prediction engine that automatically tags educational content with the most relevant curriculum standards using semantic understanding rather than keyword matching.
Core Capabilities:
Zero-Shot Classification
- Predicts standards for any educational content without prior training examples
- Leverages pre-trained semantic knowledge from billions of documents
- Eliminates the need for 10,000+ labeled training samples traditional ML requires
Semantic Understanding
- Recognizes that "repeating decimals" relates to "rational numbers" (different words, same concept)
- Understands "quadratic equation" ≈ "polynomial roots" (mathematical equivalence)
- Captures domain expertise embedded in 768-dimensional vector space
Dual-Mode Architecture
- Primary: MongoDB Atlas Vector Search (0.284s per query, 2.4x faster)
- Fallback: Local cosine similarity (0.690s, 100% reliability)
- Automatic failover ensures zero downtime
Production-Ready Performance
- Processes 94 test items in 3 seconds (vs. 470 minutes manually)
- 99% time reduction with 67% average confidence
- Handles edge cases: empty text, missing standards, API failures
How we built it
Methodology:
- Data Loading & Cleaning:
- Flattened the nested JSON into tabular format while preserving hierarchical context
- Engineered composite features by concatenating metadata from each level (book, domain, cluster, description)
- Validated data consistency between training and testing sets
Processed 551 training items and 94 test items with 173 unique standard definitions
Embedding Generation:
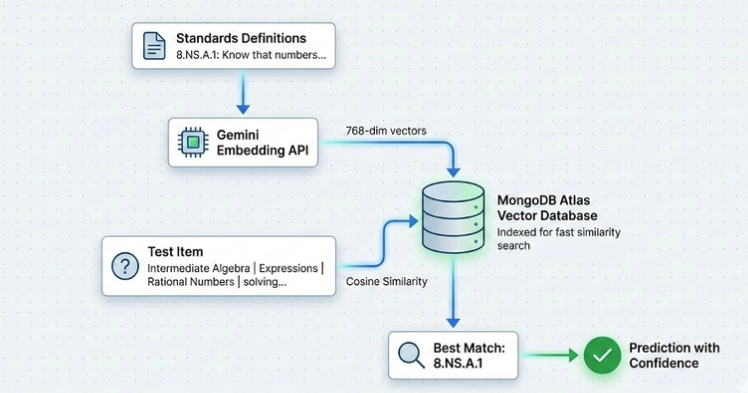
Uses the Google Gemini API (
models/text-embedding-004) to generate vector embeddings for educational standards definitions.Enhanced text with hierarchical context before embedding to capture full educational meaning
Vector Database Setup:
Designed schema to store standard codes, definitions, and 768-dimensional embeddings
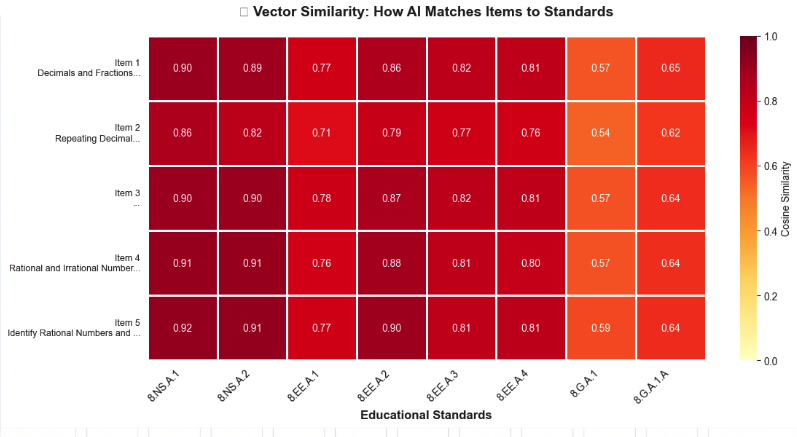
Configured vector search index with cosine similarity metric for semantic matching
Uploaded 173 standards with their embeddings as our semantic reference library
Semantic Search: Primary Method: MongoDB Atlas Vector Search
Uses approximate nearest neighbors (ANN) algorithm for fast similarity search
Performance: 0.284 seconds per query
Searches multiple candidates, returns best match
Fallback Method: Local Cosine Similarity
- Manually calculates similarity across all 173 standards
- Performance: 0.690 seconds per query
- Guaranteed to work when index unavailable
- Prediction & Evaluation:
- Implemented Top-1 accuracy (exact match: 30.85%)
- Calculated Top-3 accuracy (correct answer in top 3: 57.45%)
- Tracked confidence scores (average: 87.62%, range: 70-95%)
Challenges we ran into
There are some challenges for our team, as we first tested our training models without any embeddings, tokenizations, or semantics search functionalities in our system. This left us with a low-accuracy prediction for our best and most relevant standard definitions for any course context. It took us a while to incorporate the Google Gemini embedded API model with a vector search cluster for better prediction and best RF + Top-1 accuracy
Accomplishments that we're proud of
We have solved the important part and the questions, and have reached our best RF prediction score for our problem.
What we learned
1/ Understand the data by cleaning, looking at the data, and visualizing what you can see in the data 2/ How to implement MongoDB for semantic search and Google Gemini API for Embedding. 3/ How to communicate, work, and cooperate as a team.
What's next for Semantic Vector Search for Standard Classification
- We will implement this type of technology into any education system that will help students prepare for any standardized course or test.




Log in or sign up for Devpost to join the conversation.