-
-
Sign Up
-
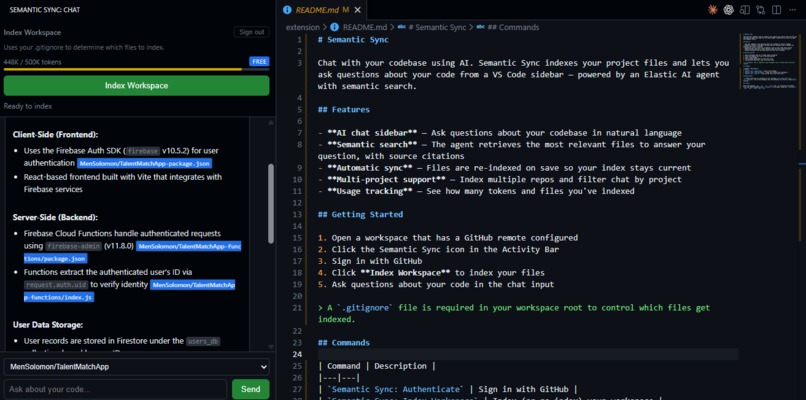
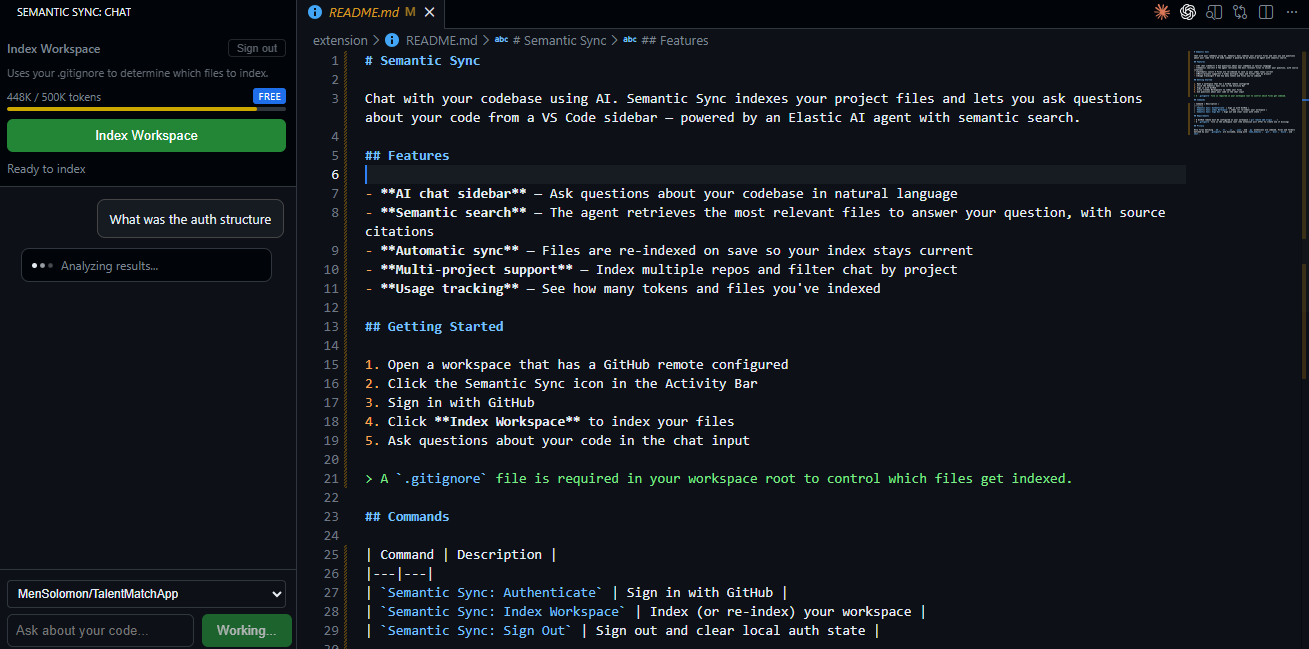
Agent Response with citation
-
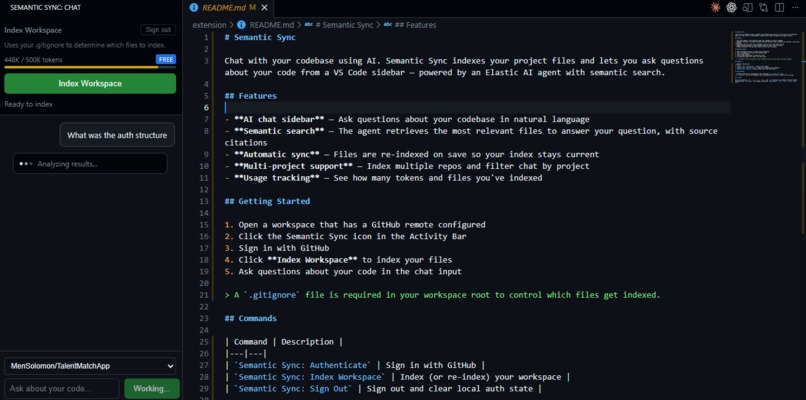
-
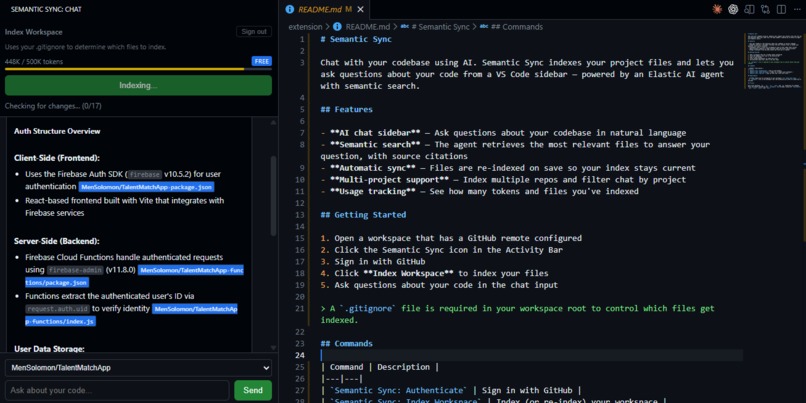
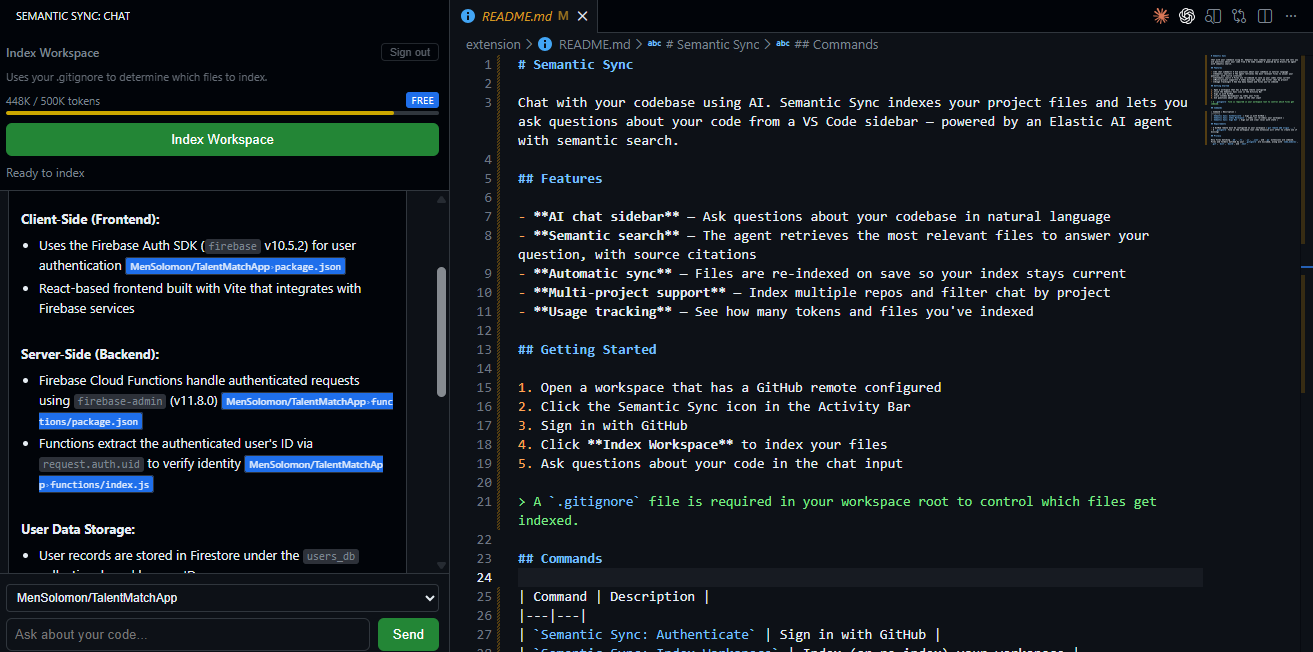
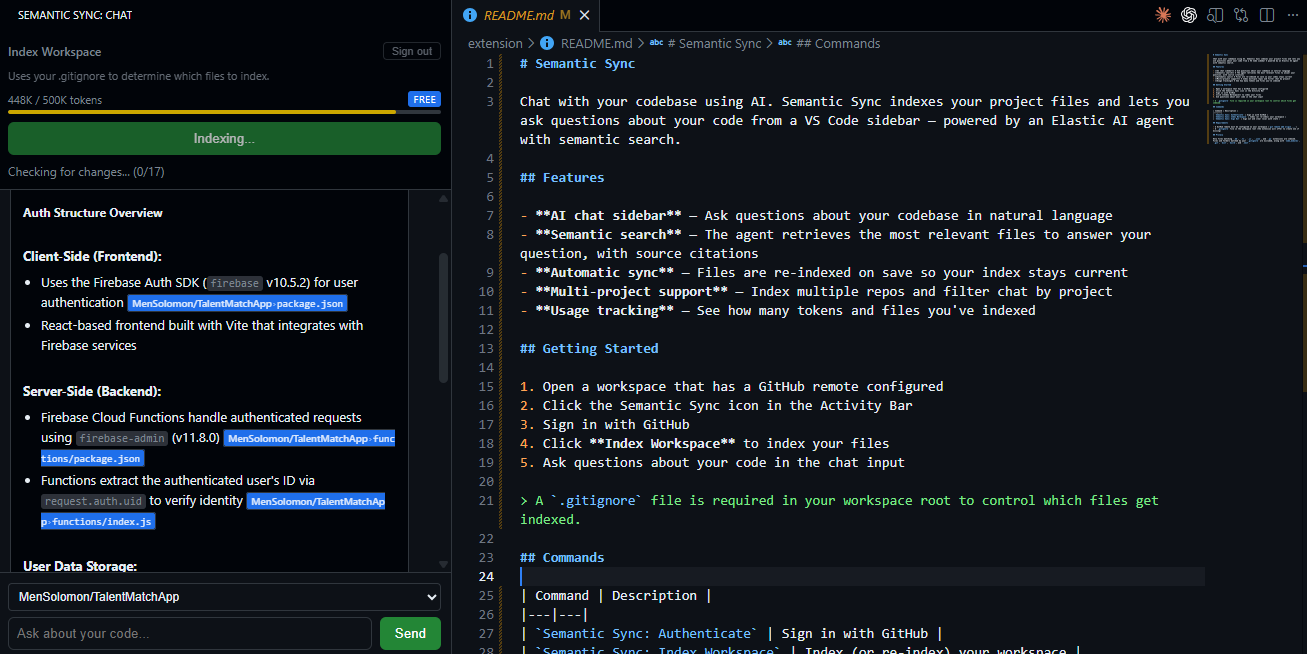
Indexing a workspace (repo)
Semantic Sync
Chat with any codebase. Never leave your editor.
The Problem
Developers constantly lose their flow switching between editor, terminal, GitHub, and docs just to answer basic questions about their own code — "where does this logic live?", "how does auth work here?". The larger the codebase, the worse it gets.
I wanted a solution that lives inside the editor, knows your project, and cites exactly where its answers come from.
What It Does
Semantic Sync is a VS Code extension that lets you index your workspace and chat with an AI that knows your code.
- Index your workspace — one command scans your source files, respects
.gitignore, and pushes only changed files to Elasticsearch. Each file gets a plain-English AI summary stored alongside the raw code. - Ask questions in the sidebar — type a question and the Kibana AI Agent searches your personal index and replies with inline citations like
[Project: owner/repo | File: src/auth.ts]. - Stay in sync automatically — every file save triggers a silent background update so the agent's knowledge never goes stale.
- Open cited files instantly — click any citation chip and the referenced file opens on GitHub directly.
How I Built It
VS Code Extension (TypeScript)
↕ HTTP / Server-Sent Events
FastAPI Backend (Python)
↕ Elasticsearch + Kibana AI Agent
Elastic Cloud (Serverless)
The backend verifies a Firebase ID token on every request to keep each user's data completely isolated. On ingest, it checks content hashes to skip unchanged files, then calls Claude Haiku concurrently to generate semantic summaries before indexing into Elasticsearch.
Token usage is tracked in Firestore against tiered subscription limits. Re-indexing only charges the difference in size — so editing a small function doesn't count against your quota as if you re-uploaded the whole file:
$$\Delta_{\text{tokens}} = \sum_{f \in \text{changed}} \left( \text{tokens}(f_{\text{new}}) - \text{tokens}(f_{\text{old}}) \right)$$
Elastic Features Used
- Elasticsearch Serverless for per-user document indexing with strict workspace isolation
- Semantic / vector search on both raw code and AI-generated summaries for intent-aware retrieval
- Kibana AI Agent for orchestrating retrieval and generating grounded, cited responses streamed back via SSE
Two Things I Loved
Semantic search over AI summaries. Storing a Claude-generated summary alongside raw code and searching both fields dramatically improved retrieval quality. Conceptual questions like "where do we handle token expiry?" surface the right files even when those words never appear literally in the code.
The Kibana Agent as a retrieval orchestrator. Rather than building a retrieval pipeline from scratch, the Agent handled document lookup, workspace scoping, and citation generation — letting me focus on the streaming layer and workspace identity design instead.
Hardest Challenge
Making a blocking API feel live.
The Kibana Agent returns one big response after thinking — there's no native streaming. I worked around this by firing status messages on a loop while awaiting the response in the background:
async def stream_status(messages, delay=1.5):
for msg in cycle(messages):
yield f"data: {json.dumps({'status': msg})}\n\n"
await asyncio.sleep(delay)
Then I streamed the final answer word-by-word over SSE, giving users a typewriter effect with no perceived wait.
What's Next
- Team indexes — workspace IDs are already tied to GitHub slugs (
owner/repo), so the foundation for shared team indexes is in place - More languages — Go, Rust, Java, and Ruby with language-aware summary prompts
- Local LLM support — swap Claude Haiku for a local model for air-gapped environments
Built With
- elasticsearch
- fastapi
- firebase
- kibana
- python
- railway
- react
- typescript
- uvicorn

Log in or sign up for Devpost to join the conversation.