-
-
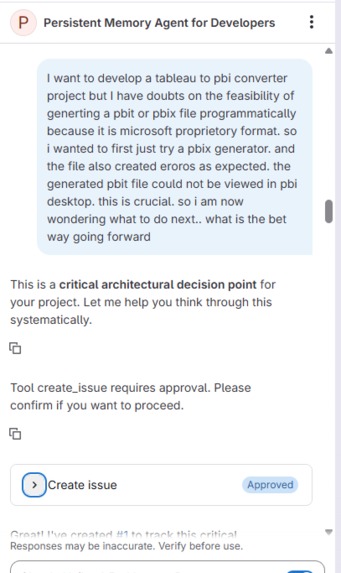
Chat Sample with Persistent Memory Agent
-

Chat Sample with Persistent Memory Agent
-

Persistent Memory Agent - Definitions
-

Decisions documented in JSON file
-
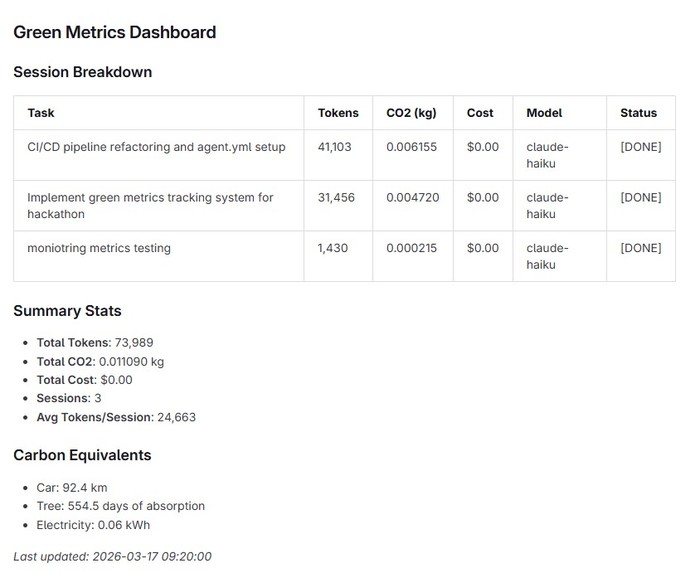
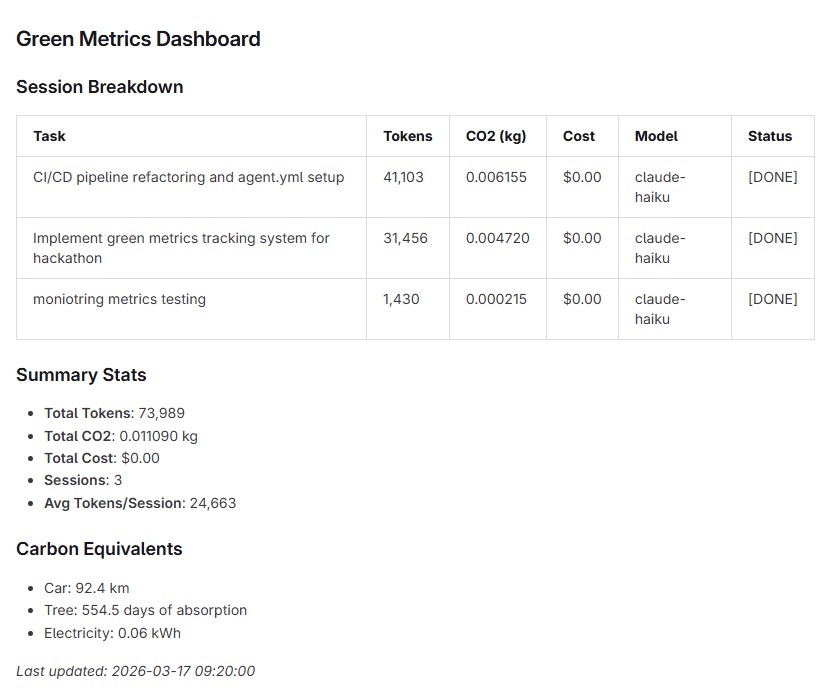
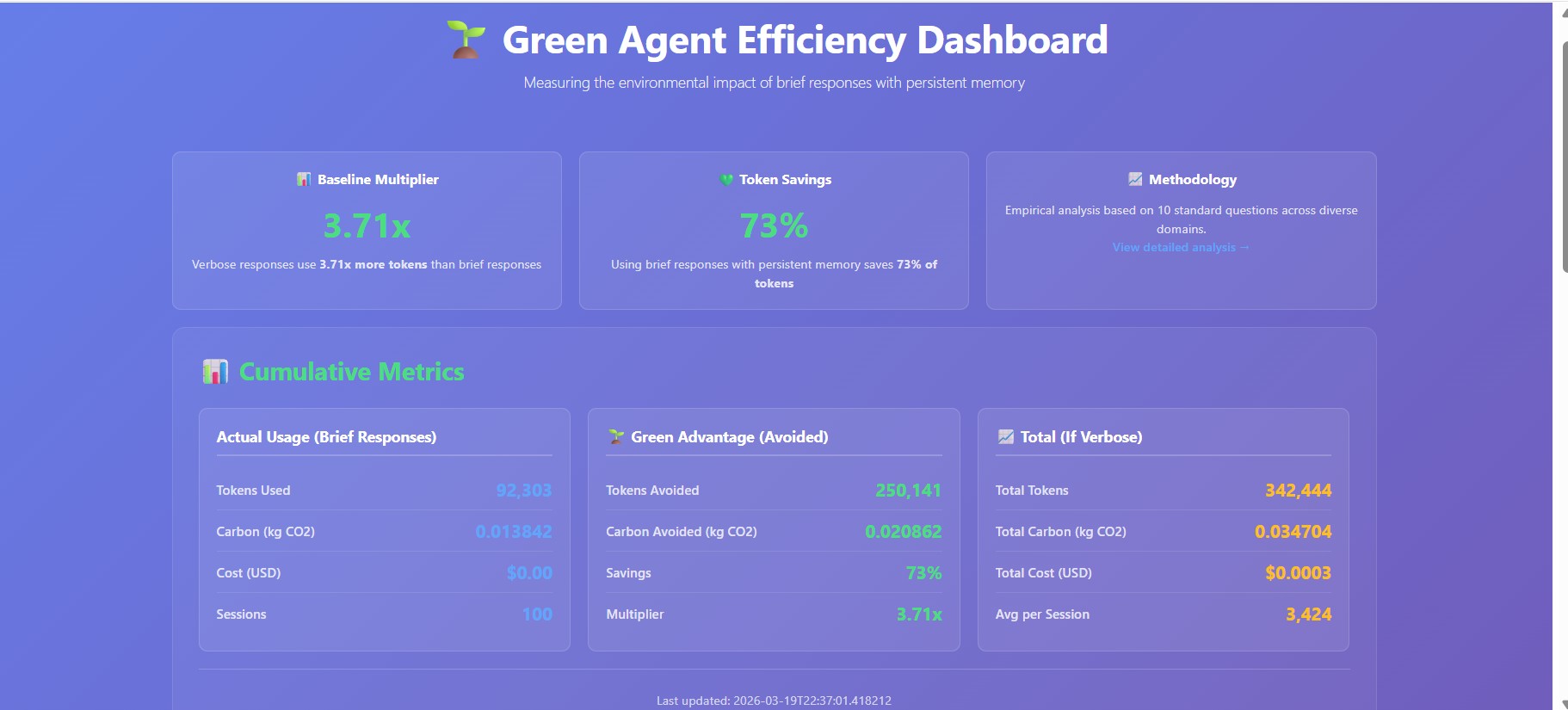
Green Metrics Dashboard on README file
-
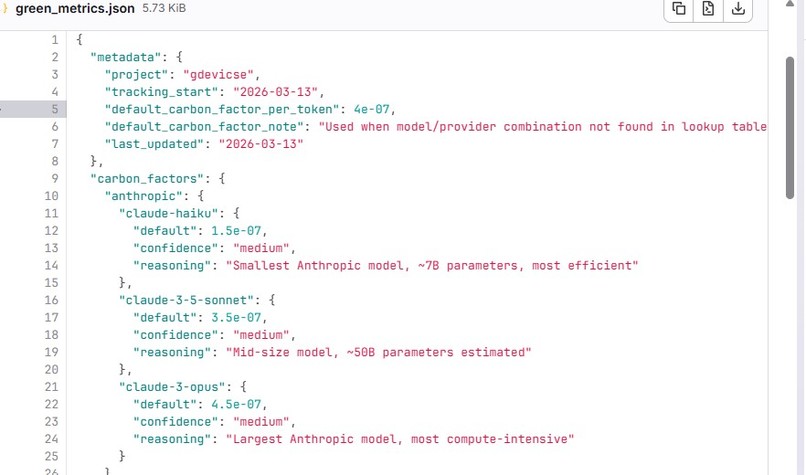
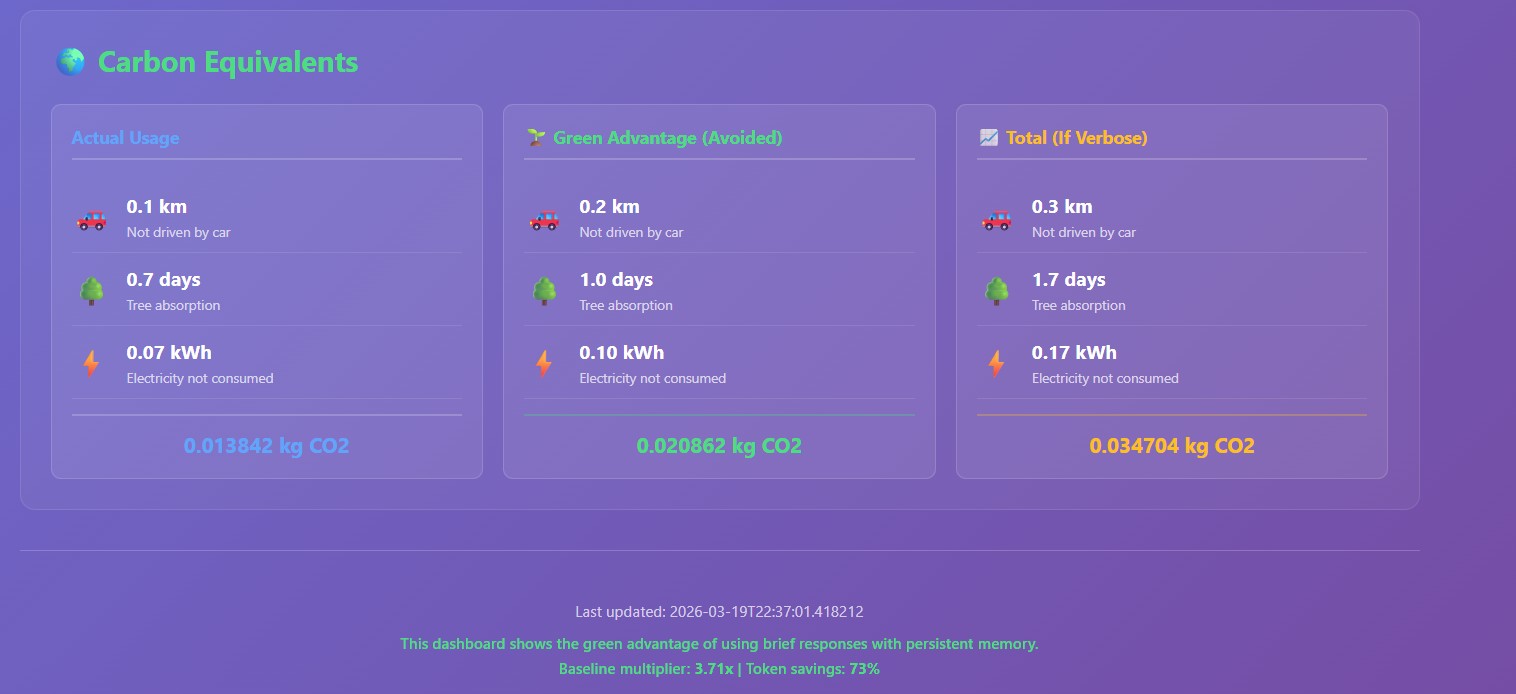
A look up table for Carbon Factors
-
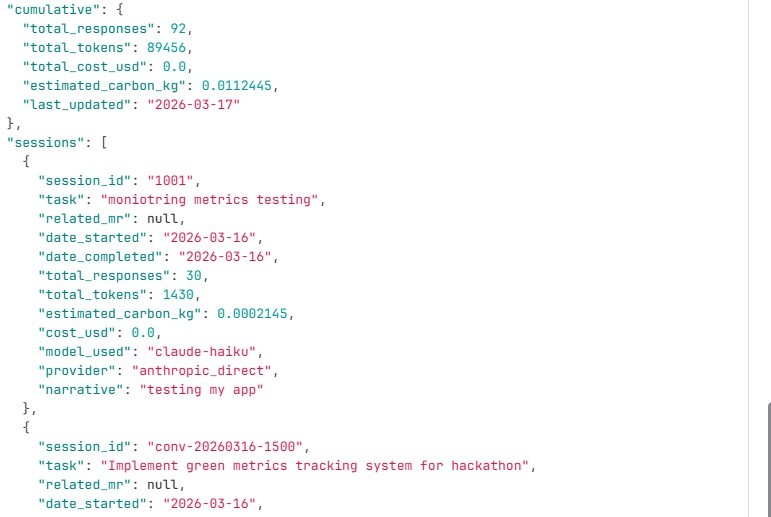
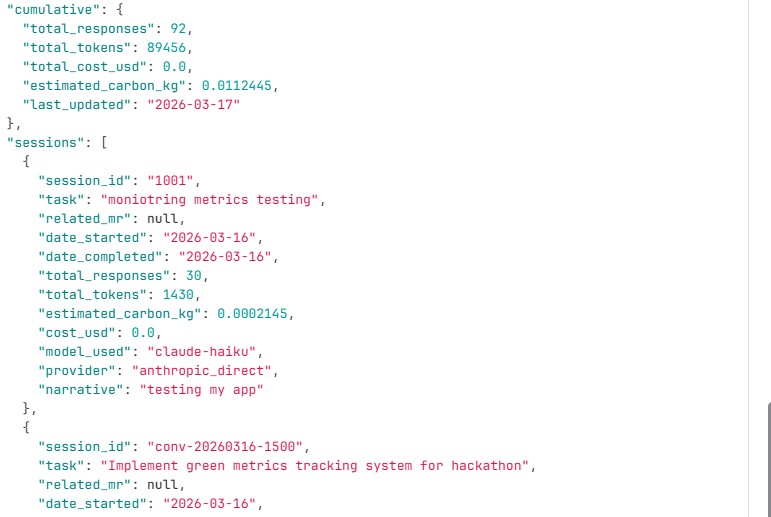
Snapshot of sessions monitored for green metrics
-

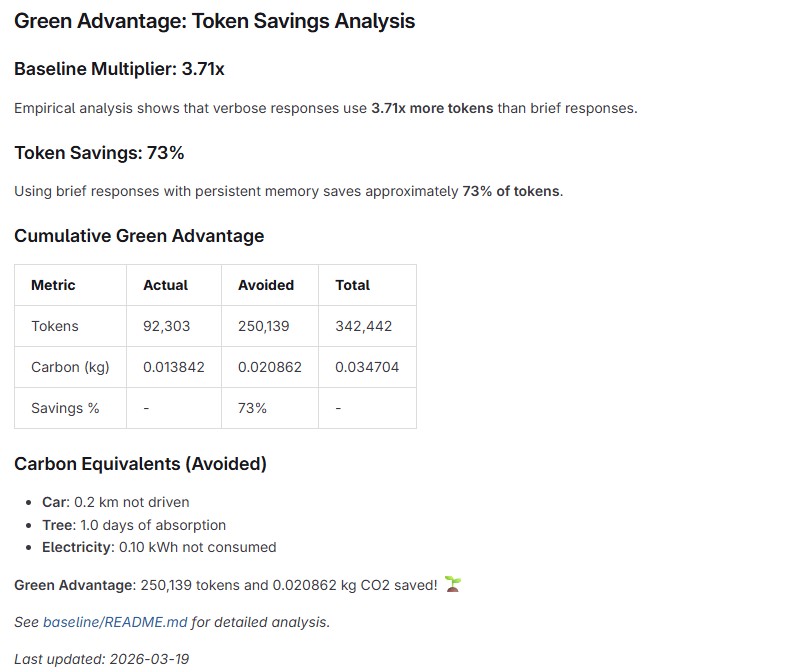
Empirical Analysis for Green Advantage Baseline
-
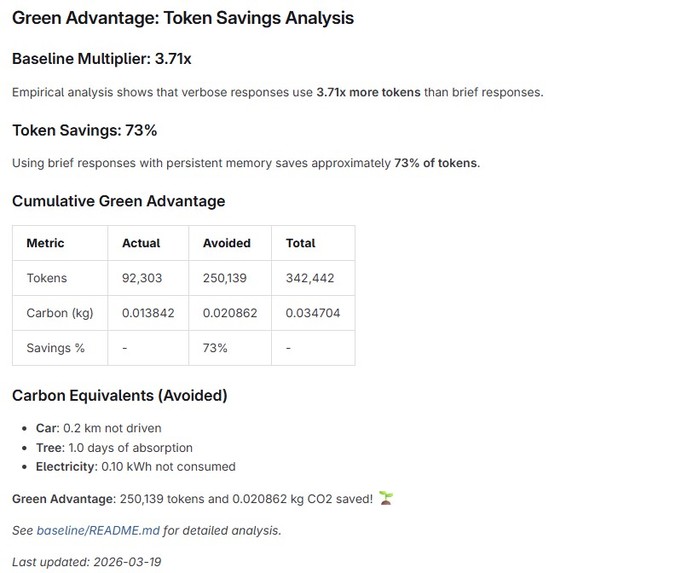
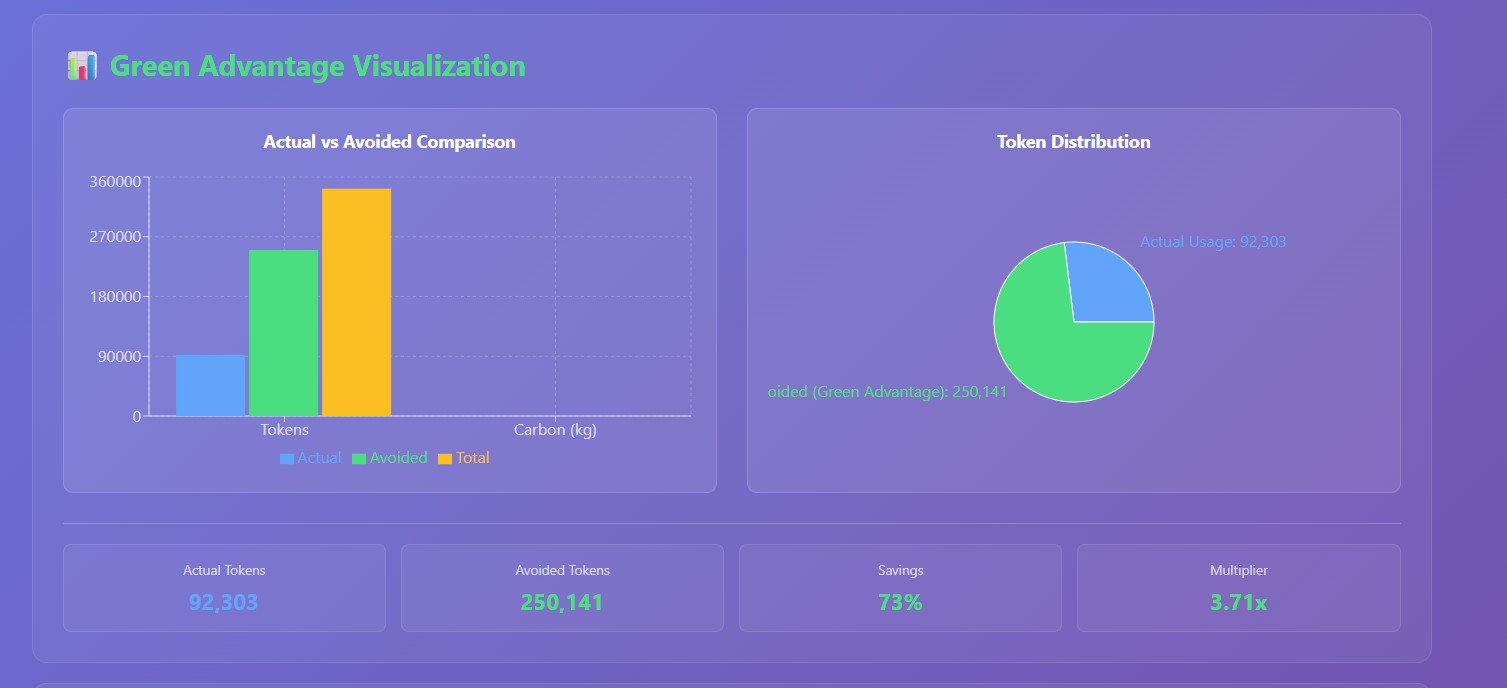
Green Advantage Measure
-

Green Advantage Dashboard
-
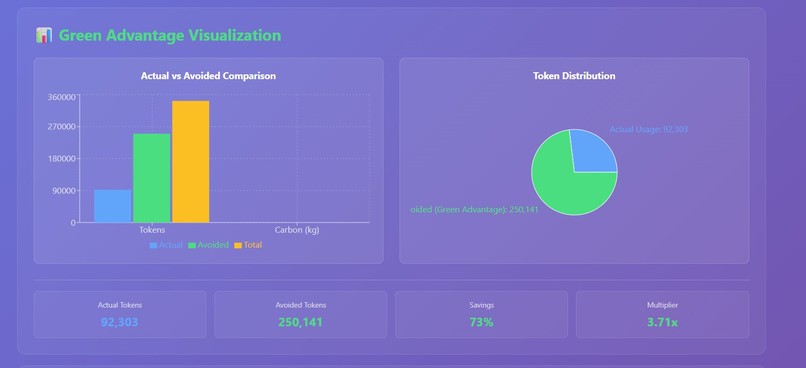
Green Advantage Dashboard
-
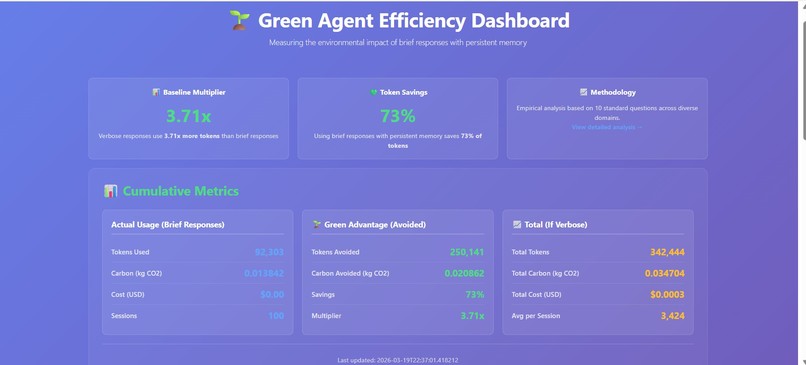
Green Advantage Dashboard
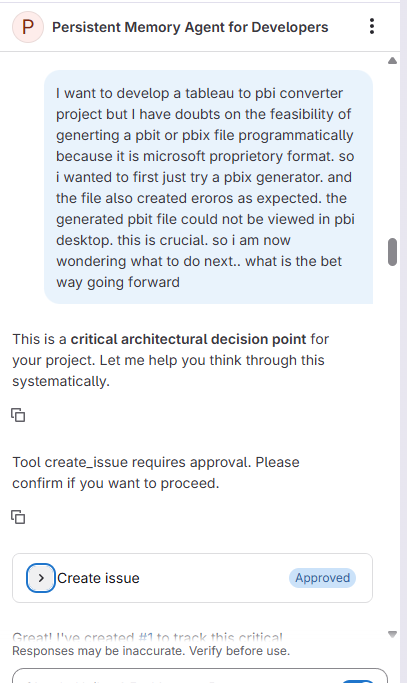





Inspiration
As an end-to-end AI engineer, I’ve enjoyed building with agents, but one limitation consistently stands out: their lack of long-term memory. When I explore a problem through a chain of thought and return to it later, I remember where I left off—but the agent doesn’t. It feels like starting over with a new collaborator, having to re-explain prior context and reasoning.
What if the agent could retain a snapshot of the project’s evolving thought process and resume from where we left off? That would transform the experience into working with a consistent co-developer—one that understands not just the current state, but how the project got there.
At the same time, as someone who values sustainability, I wanted to extend this idea further: can we make developers more aware of the environmental impact of AI usage? This led to combining persistent memory with “green awareness”—encouraging teams to track and reduce their carbon footprint through measurable goals (e.g., reducing footprint by 5% per sprint or rewarding low-impact usage).
What it does
Persistent Memory Agent
- Automatically captures and stores key design decisions, discussions, and pain points from developer interactions
- Maintains institutional memory as a versioned JSON file (
project_memory.json) within the repository - Enables developers to revisit past decisions, understand their context, and evaluate their impact
- Preserves expert knowledge and significantly improves onboarding for new team members
Green Agent
- Encourages concise, high-signal responses with optional expandable detail
- Optimizes token usage for both cost efficiency and environmental sustainability
- Tracks per session:
- Total tokens used
- Number of responses
- Model and provider
- Estimated carbon footprint
- One-line summary of the interaction
- Total tokens used
How we built it
The project is a Python-based toolkit that makes AI energy usage measurable and actionable. It tracks token consumption, API calls, computational overhead, and estimated carbon footprint for LLM-powered workflows.
- Backend: FastAPI
- Frontend: React
Dashboards
- Web UI deployed via GitLab CI/CD to Google Cloud Build
- Auto-updating README dashboard driven by GitLab commits
Challenges we ran into
CI/CD with Google Cloud Build:
Faced permission issues while configuring GCP keys as CI/CD variables
→ Workaround: implemented a live dashboard directly in the READMEAgent communication limitations:
Agents couldn’t push metrics to external endpoints
→ Solution: store tracking data locally in JSON and sync it to dashboards via scheduled updates
Accomplishments that we're proud of
- Built a persistent memory system that captures the evolution of project decisions—making implicit knowledge explicit and shareable
- Created a green metrics dashboard that quantifies the environmental impact of AI usage, promoting more responsible development practices
What we learned
- Setting up CI/CD pipelines from scratch (including YAML configuration)
- Working with Google Cloud Build
- Designing a more effective agentic co-developer experience
- Using Git more efficiently in a collaborative, iterative workflow
What’s next
- Improve the accuracy and granularity of carbon footprint estimation
- Expand integrations with more LLM providers and development tools
- Introduce team-level sustainability goals and benchmarking
- Enhance memory retrieval with smarter context summarization and search

Log in or sign up for Devpost to join the conversation.