





Inspiration
The United Nations 2030 Agenda for Sustainable Development provides a "shared blueprint for peace and prosperity for people and the planet, now and into the future."
Leading this Agenda are 17 Sustainable Development Goals (SDGs) intended to be achieved by 2030.
The Sustainable Development Goals are highly interconnected: for example, goals targeting resilience of the poor and sustainable food production are linked to adverse impacts of climate change and improving food production by combating desertification and improving soil quality.
At a small scale it’s easy to visually identify these links and interconnected themes, but at a large scale this can be exceedingly difficult. Researchers and domain experts typically publish their findings in lengthy books, scientific papers and institutional reports.
A researcher, development analyst or project coordinator looking for findings that link SDG 2.4 "sustainable and resilient agricultural practices" and SDG 15.3 "combating desertification and soil restoration" in Central America with topics-or-themes of "property rights of indigenous communities" has to search through hundreds or thousands of pages of PDFs from organizations like:
- UNICEF
- The World Bank Open Data Repository
- The International Union for Conservation of Nature
- Intergovernmental Platform for Biodiversity and Ecosystem Services
- IPCC The Intergovernmental Panel on Climate Change
- Millennium Ecosystem Assessment
Natural Language Processing and TigerGraph to the Rescue!
The concept of applying Natural Language Processing techniques to extract and construct knowledge graphs from unstructured text is not new. I personally began working on projects in this technical domain more than ten years ago. However, what once took years of R&D by a team of researchers and engineers, is now achievable by a proficient solo-developer in a few weeks on commodity hardware. What has changed recently is:
- The availability of powerful, pre-trained NLP Language Models
- SaaS graph database platforms, like TigerGraph, with great community support and a low barrier to entry
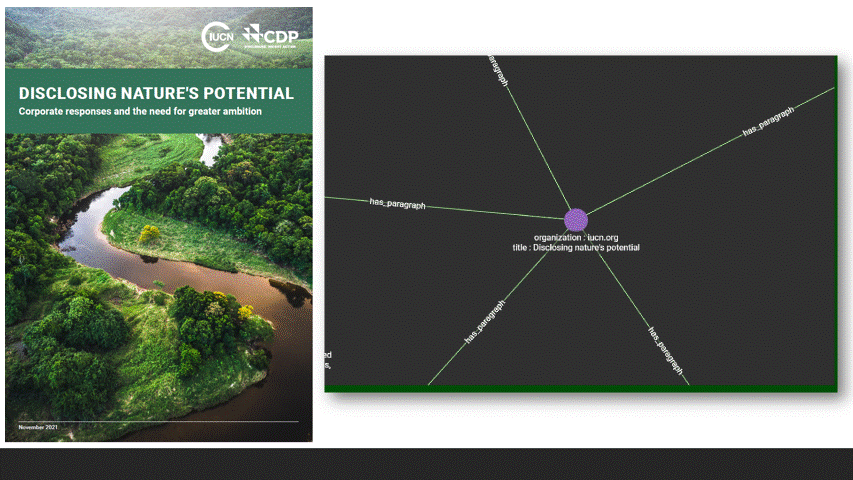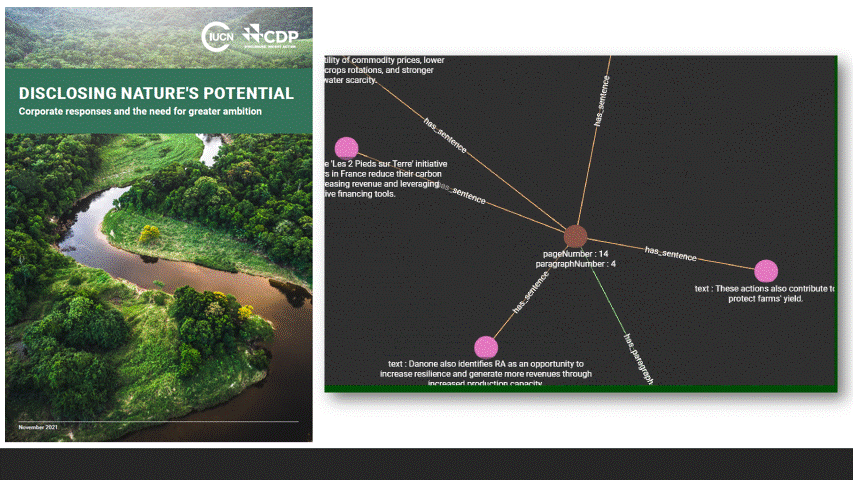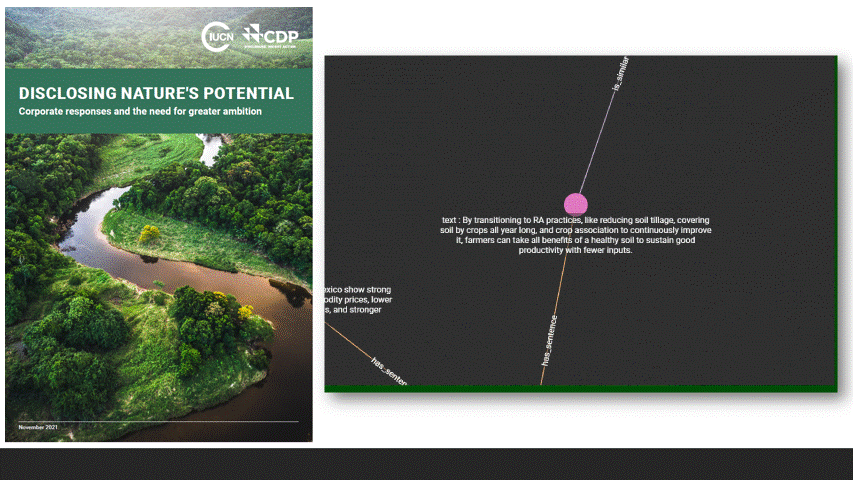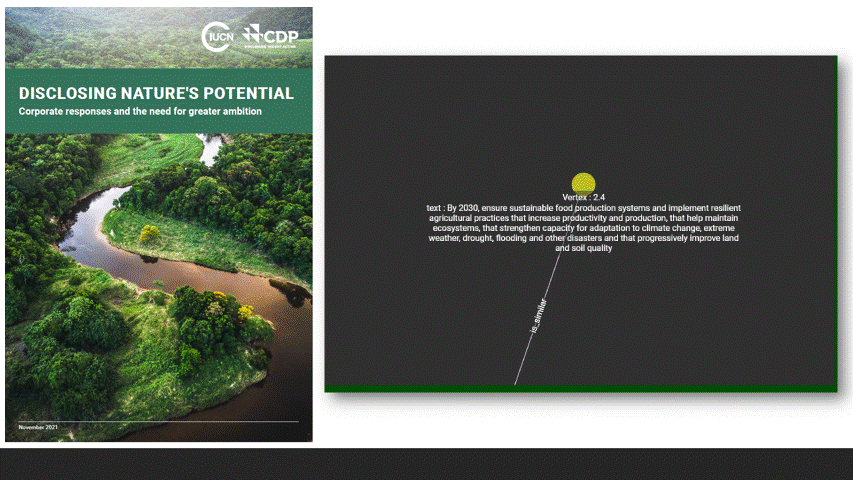
The goal of this project was to build a solution that empowered non-technical (about programming, web-crawling, machine learning or graph databases) users to easily discover links between Documents, SDGs, Entities (people, places and organizations) and Topics, while always retaining the link back to a source document or paragraph.
This final aspect significantly increased the technical complexity of the solution. Many described and published approaches focus only on extracting and building a Knowledge Graph, stopping at presenting their results as a traditional node-linked diagram (such as the screenshot above), which is great for conveying the results to other graph professionals, but difficult to navigate for non-technical users. A user-friendly Web Application front-end would need to be built backed by TigerGraph as the data engine.
How we built it
Everything necessary to reproduce this solution is available in the Github repo: mikewillekes/unsdgftw
The end-to-end pipeline is as follows:
- Install Python prerequisites via
pipenv - Raw Data Acquisition and Preprocessing
- This is the only manual step as some of the source PDFs were manually download and converted to XHTML using Apache Tika
- These PDFs can quite large so are not included in the Git repo, however the outputs of Clean Text are included in the repo so the entire graph solution can be recreated
- Clean Text
- Extract Paragraphs
- Extract Sentences
- Extract Entities
- NLP
- Semantic Similarity
- Topic Modelling
- Graph
- Create TigerGraph Schema from empty Solution
- Install GSQL Queries
- Build CSV files for loading
- Load CSV files to TigerGraph
- Augment Graph by building co_mention edges between SDGs, Entities and Topics
- Community detection via label propagation (result stored in
lidattribute) - Closeness Centrality calculation (result stored in
centattribute)
- Streamlit Application UI
- Launch Streamlit app to view UI
Challenges we ran into
- Semantic similarity (cosine distance) was calculated between each sentence and each SDG sub-goal using a pre-trained transformer model. This simple unsupervised ML approach often had difficulties distinguishing between multiple but similar SGS. Likely a supervised multi-class classifier approach could achieve better results.
- Research documents themselves contains numerous references to other publications. These were not taken into account when building the Knowledge Graph.
- Topics, extracted as a collection of words, are weird for displaying to non-NLP enthusiasts. We understand what "fgm|girls|practice|women|undergone|aged|who|prevalence|years|15" is about, but it's not a user-friendly way to display data.
- SDGs, Entities and Topics were considered 'related' if they co-occurred in the same Paragraph. This is a naive rule that doesn't always hold true (i.e. for very long paragraphs).
- More Data! About 200 PDFs (~21K Paragraphs of text) were crawled across 5 organizations. The focus of this project was on the NLP, graph algorithms and UI development instead. However with a bit more work, this approach could easily scale to 1000s of documents.
- The TigerGraph CSV API is clunky to use as schema changes. Late in the project, a few new fields were added to nodes and edges to explore capabilities of the TigerGraph data science library; but this broke all the existing loading scripts as positional CSV column designations match anymore.
Accomplishments that we're Proud of
- From early-on, a priority was placed on scripts to automate the end-to-end flow: regenerating datasets from raw PDFs, to dropping-and-recreating the TigerGraph schema and installing queries, loading data and enriching the graphs with augmented edges, centrality and community detection; This enabled fast, frequent iteration as all of the moving parts started coming together
- The graph schema worked very well from inception to delivery
- The TigerGraph and GSQL tools were easy get started, well documented and performed extremely well; however it did take a while to adjust to thinking in terms of GSQL and Accumulators vs. relational SQL
What's next for Semantic Graph Explorer for Sustainable Development
- It was out of scope to build a semantic search interface, only exploration; a future improvement would be to include a semantic search solution via vector similarity
- It could be compelling to explore a proof-of-concept using this Knowledge Graph to generate graph embedding that could be shared to enrich other downstream machine learning tasks
Built With
- apache-tika
- beautiful-soup
- bertopic
- hugging-face
- plotly
- python
- pytigergraph
- spacy
- streamlit
- transformers
- zyte



Log in or sign up for Devpost to join the conversation.