Inspiration
This is a Computer Vision project aimed at understanding the contents of images. This has numerous applications, such as in robotics, driverless cars, medical diagnosis and image editing. In all this cases, machines need to perceive and understand their environment in a manner similar to humans.
There are now cloud services, such as the Microsoft Cognitive Services API. However, these do not offer a detailed, per-pixel understanding of images, which is what my system does.
What it does
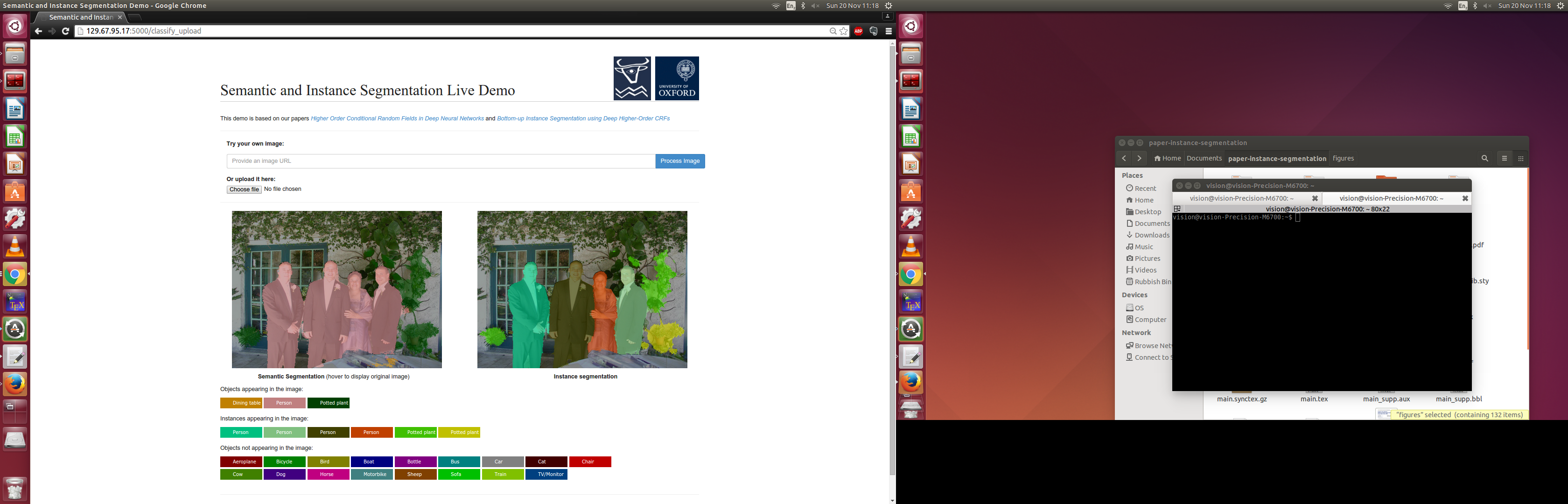
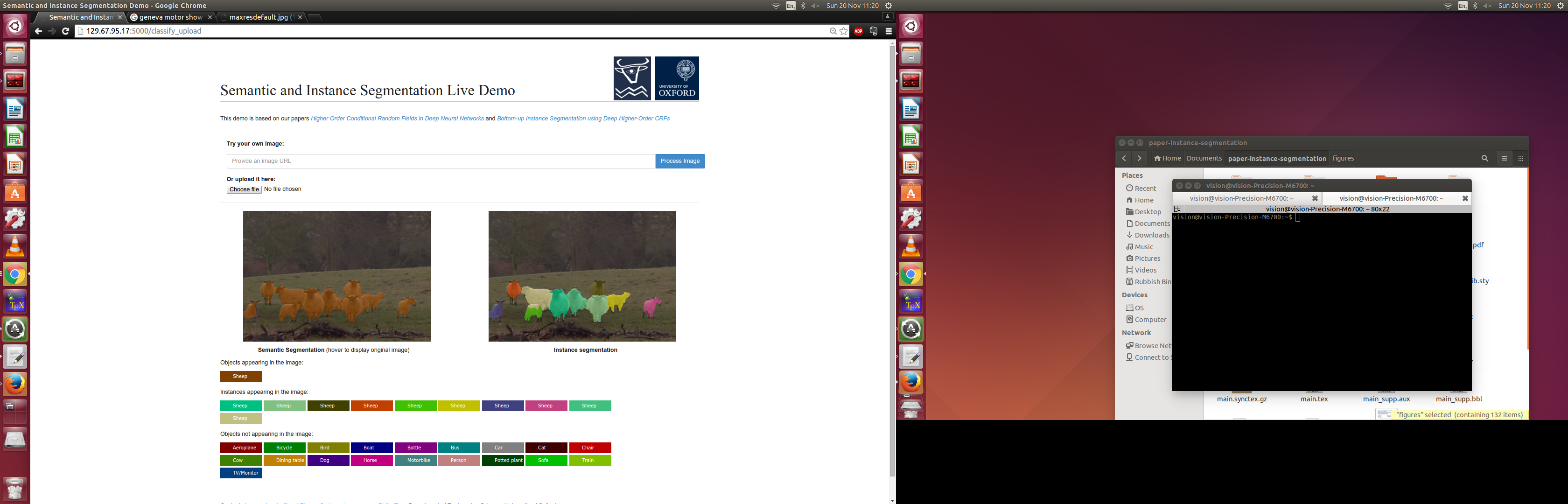
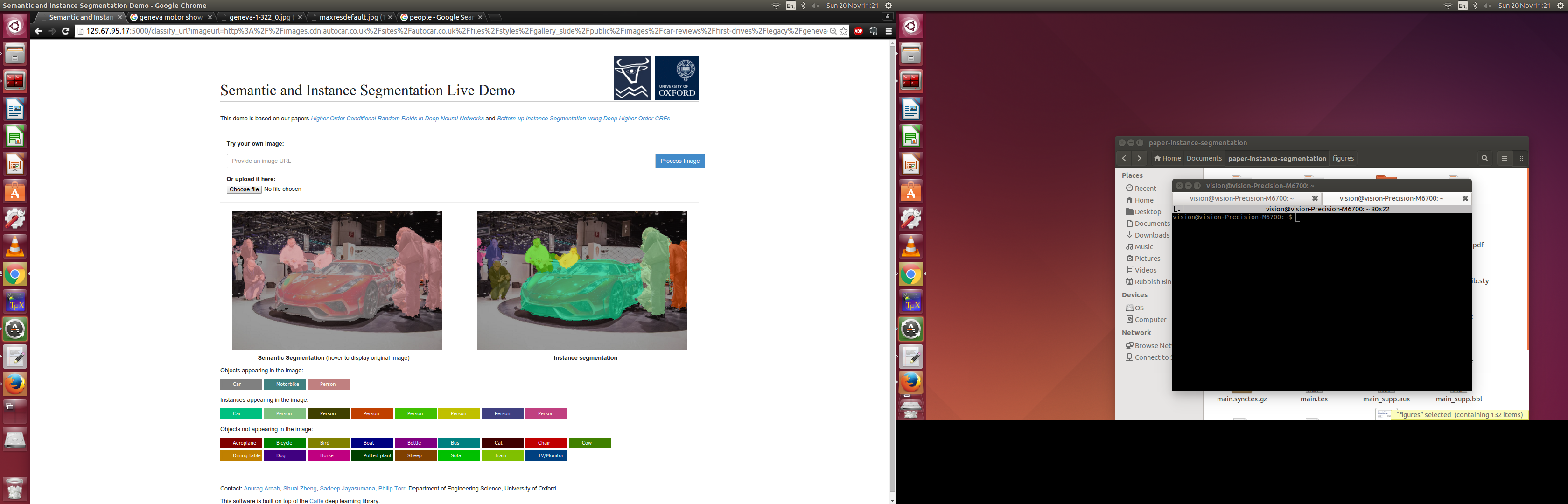
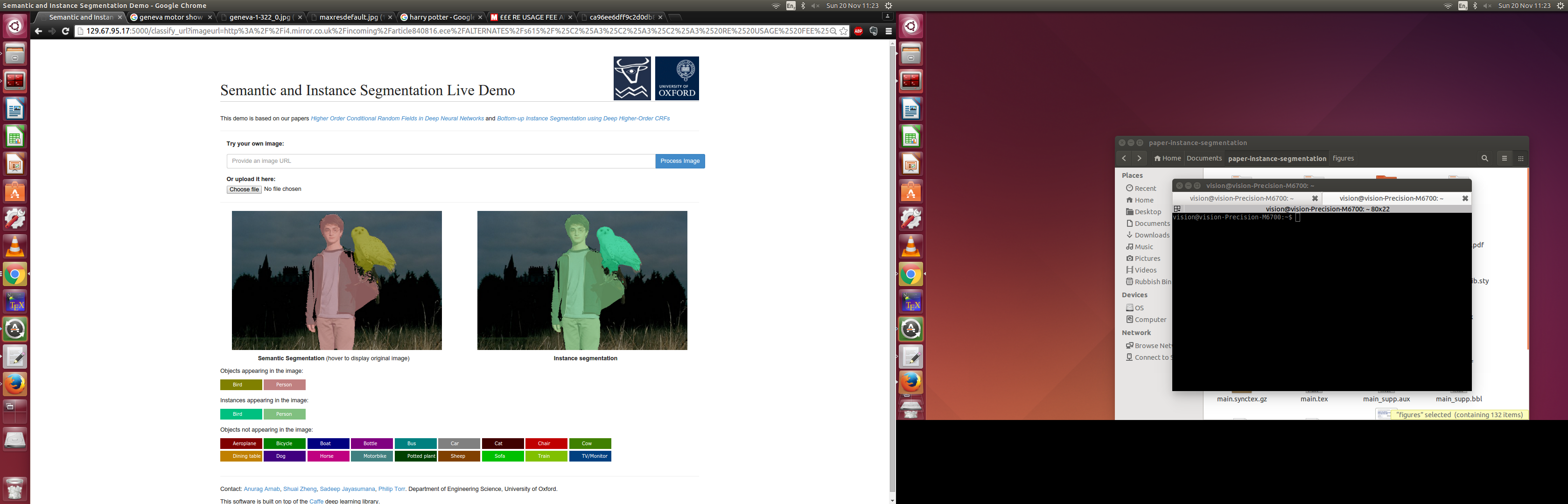
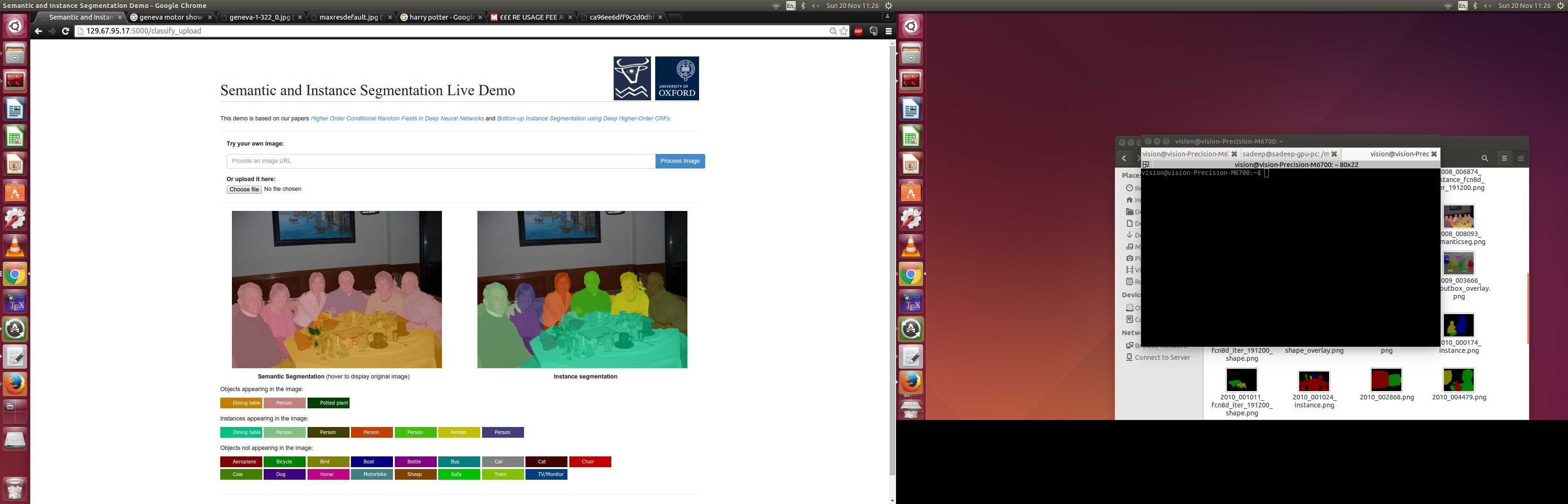
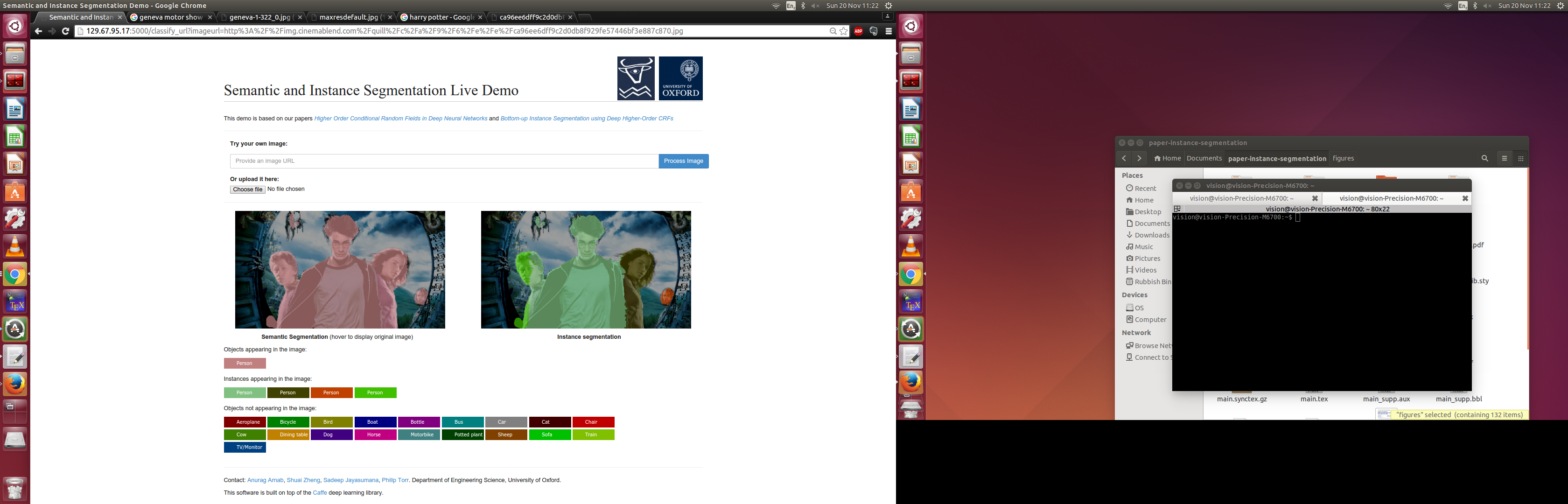
The algorithm identifies the object class of every single pixel in the image. For example, it labels certain pixels as "person", and others as "car" and so on. Furthermore, it identifies unique instances of objects as well: So if there are multiple people, then it should identify each person separately.
How I built it
The core of the system is implemented using deep neural networks, and described in my research papers (I am a PhD student). I had already trained a model to perform Semantic and Instance Segmentation as part of my research and conference paper submission.
In the hackathon, I built a web interface to it, so that a user could upload images, or specify links to images on the internet, and see their result on unconstrained images.
This runs on the cloud, on a Titan X GPU using Cuda.
Challenges I ran into
I don't really know much about building websites.
Accomplishments that I'm proud of
It seems to work! The algorithm had previously only been evaluated on academic datasets. Now it is being tested on random images from the internet.
What I learned
I learnt a bit about Flask and building websites in Python.
What's next for Semantic and Instance Segmentation
There will be some improvements to the core recognition algorithm. Also, the "Instance Segmentation" part needs to deal better with occluding objects.

Log in or sign up for Devpost to join the conversation.