SemaDepth
Inspiration
Built solo in 5 hours at the Ironsite Spatial Intelligence Hackathon.
LiDAR sensors cost thousands of dollars. But a phone camera is already in a billion pockets. I wanted to know if geometry, a vision model, and some semantic reasoning about the real world could bridge that gap — turning any commodity camera into a practical spatial sensor. This project is my attempt at that answer.
What it does
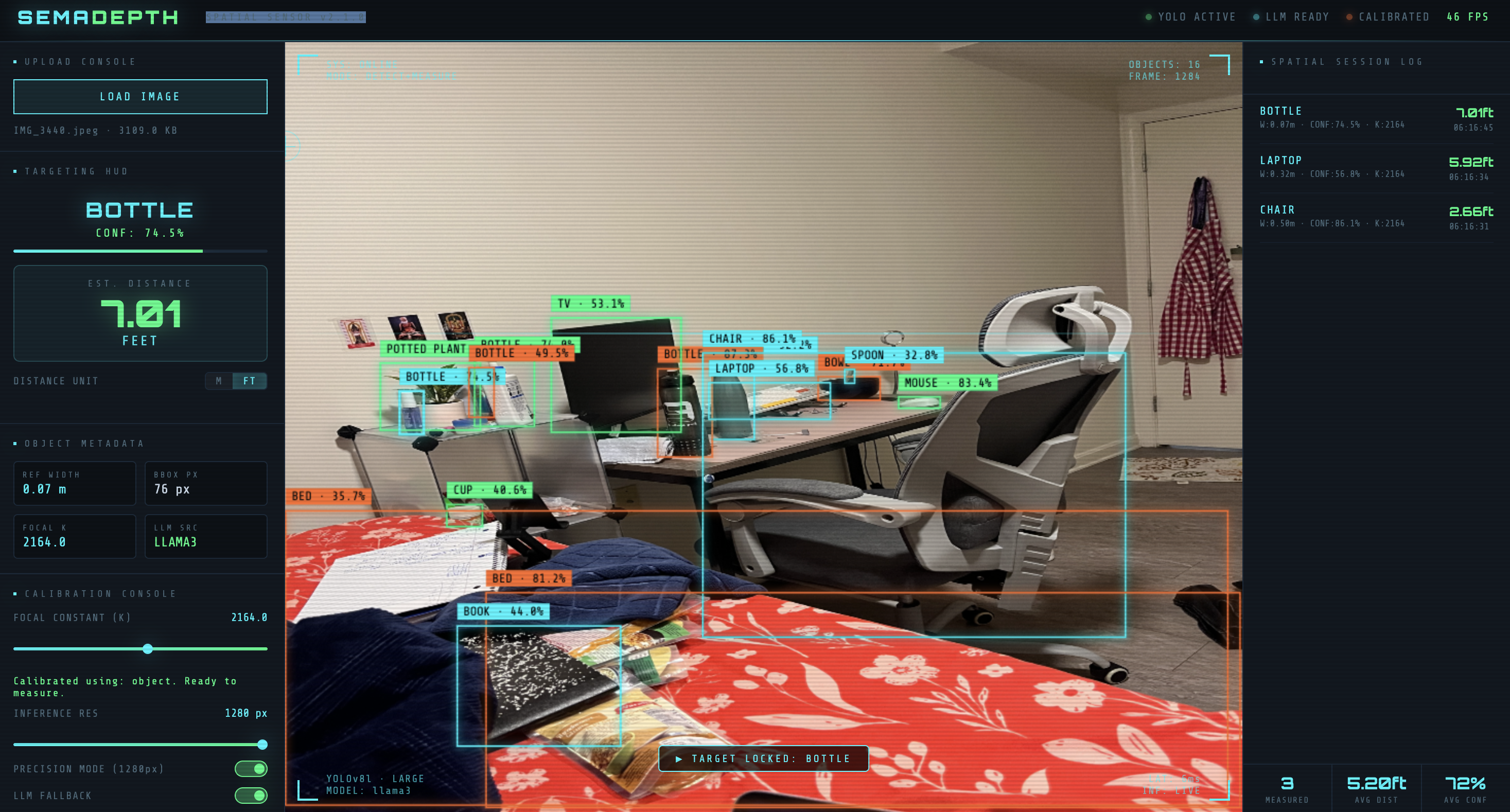
SemaDepth estimates real-world distances from a single 2D image. Upload any photo, click any detected object, get a distance estimate. No special hardware required.
- Detection: YOLOv8l identifies objects and bounding boxes at 1280px resolution
- Calibration: A guided one-shot flow locks in your camera's focal constant before measuring
- Semantic Sizing: LLaMA3 reasons the real-world dimensions of detected objects
- Interaction: Single-click distance estimation with a session log
- Output: Meters or feet, with confidence scores throughout
How I built it
- Backend: FastAPI with
/detect,/dimensions,/measure,/depthmapendpoints - Detection: Ultralytics YOLOv8l — large model for broader object recognition
- Semantic Sizing: Ollama (llama3) for real-world dimension lookup
- Depth Visualization: MiDaS for full-scene depth heatmap overlay
- Frontend: Custom HTML/CSS/JS interface with interactive canvas, targeting HUD, session log, and calibration console
Challenges I ran into
- Calibration Stability: Auto-calibrating from scene objects led to drift when anchor objects were partially visible or non-standard sizes
- Target Selection: Overlapping bounding boxes in cluttered scenes made click targeting unreliable
- Dimension Uncertainty: Semantic object widths vary significantly across object classes
- UI Density: Fitting all controls into one screen without overwhelming the user
- Confidence Handling: Low-confidence detections that looked plausible but produced poor distance estimates
Accomplishments I'm proud of
- Shipped a working monocular distance pipeline in under 6 hours, solo
- Designed a guided "forearm calibration" flow — hold any object approximately one foot away, SemaDepth calculates the rest
- Built a custom frontend from scratch with real-time interaction and session logging
- Implemented anchor-first measurement with semantic fallback for unknown objects
What I learned
Calibration quality dominates everything else in monocular estimation. A great model with bad calibration produces useless results. The geometry itself is simple — the assumptions underneath it are where things break.
UX matters as much as model quality. Users need to trust the number before they'll act on it.
Real-World Applications
- Construction Site Surveys: Estimate distances without carrying specialized equipment
- Accessibility: Help visually impaired users understand spatial distances using any standard camera
- E-Commerce & Logistics: Verify if furniture fits before delivery
- Robotics: Lightweight monocular depth fallback for robots without heavy sensor arrays
How it differs from Apple's "Measure" App
Apple Measure is a great tool — but its most accurate mode requires LiDAR, found only on iPhone Pro models. SemaDepth works on any camera, including laptops and budget smartphones.
The deeper difference is architectural. Apple Measure tracks surfaces. SemaDepth understands objects — it recognizes a keyboard and knows a keyboard is approximately 450mm wide. That semantic layer is what makes monocular estimation possible without depth hardware.
What's next
- Calibration profiles saved per device
- Confidence intervals on every measurement
- Temporal smoothing for video and live stream mode
- Expanded anchor library with construction-specific objects
- Optional depth-model fusion for non-anchor accuracy
Built With
YOLOv8 · LLaMA3 · Ollama · FastAPI · MiDaS · Python · HTML · CSS · JS

Log in or sign up for Devpost to join the conversation.