-
-
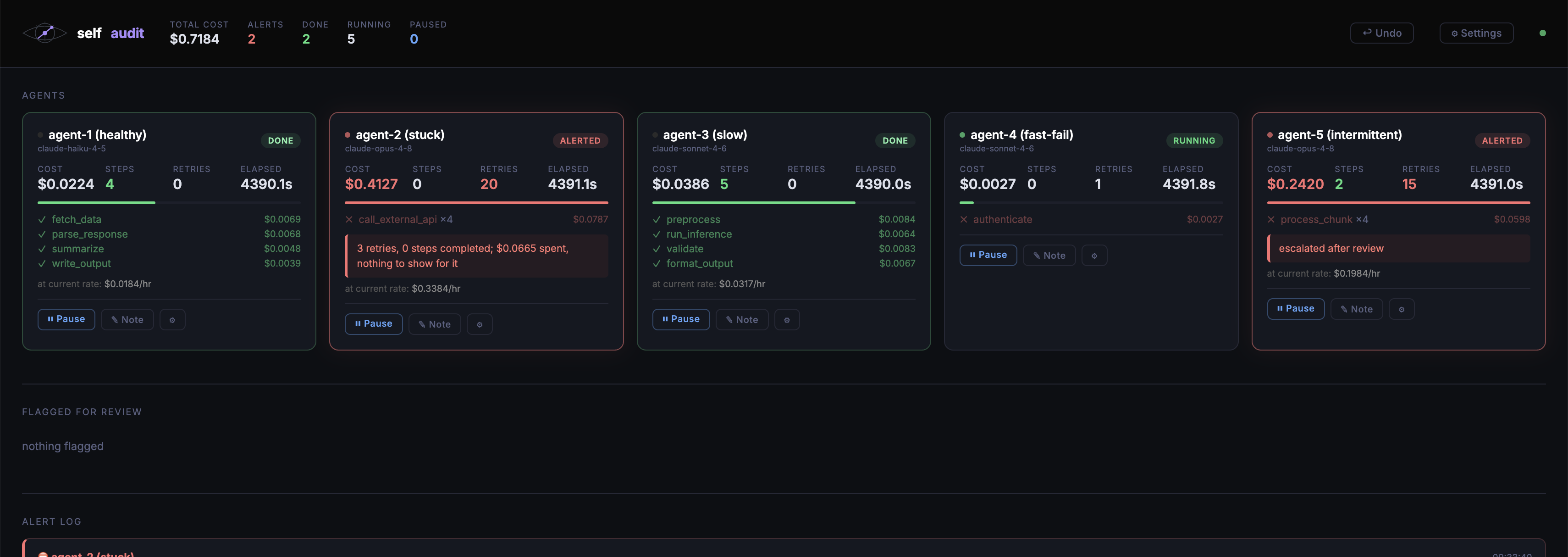
the dashboard
Inspiration
We kept hearing the same story: an AI agent gets stuck not crashed, just looping on a failing step and nobody notices because each API call looks normal. The FinOps community now has a name for it: "agentic resource exhaustion." The problem: cost dashboards tell you how much an agent spent, not whether it bought anything an agent can stay under budget and still be a total waste.
What It Does
SelfAudit tracks cost and progress in parallel, measuring progress only by objective signals completed steps, retries, elapsed time vs. baseline never by letting the agent self-report. When cost climbs but progress stalls, it flags the issue with recommendations (e.g. cheaper models) and waits for human approval in this human in the loop process, rather than auto-killing the agent; ambiguous cases go to a separate review queue instead of triggering false alarms. Past alerts are stored in Redis as embeddings so new flags get compared against similar prior cases, and dashboard state syncs across machines via Redis.
What We Built
The core is a small Python SDK a Watcher class you wrap around an existing agent loop with a context manager (with watcher.trace(agent_id, action) as t:), so dropping it into a real project takes about three lines. Behind that sits a Flask dashboard streaming live updates over Server-Sent Events, five simulated agent behaviors (healthy, stuck, slow, fast-failing, and an "ambiguous" agent that makes some progress before stalling) to demo every code path, and two Redis integrations: one for cross-session alert memory using simple vector similarity, and one for cross-machine state sync via pub/sub.
Challenges
One of our challenges was the dashboard's timer freezing it looked like agents had stalled, but really the screen just stopped updating because our live updates only fired when something happened, not on a steady clock. We fixed it by sending a regular "still alive" signal even when nothing new was happening.
What We Learned
The most useful design decision we made was the one that removed complexity: refusing to let the system grade its own value, and instead anchoring everything to numbers that don't require judgment completed steps, retries, elapsed time. It made the whole system more defensible, easier to demo, and harder to argue with.

Log in or sign up for Devpost to join the conversation.