Inspiration
When it comes to scaleable reseach, I think a lot of inspiration can be borrowed from the open source research community. Organziations like EleutherAI have a track record of producing high quality work which scales.
Some examples of projects which have worked include:
- The Pile: A massive corpus of text which was compiled by EleutherAI
- BOINC from UCB: Allowing participants to share the compute on their personal machines to power compute heavy research
- The Llama Community: A community surrounding the Llama models which drives major improvements in the models
- 200 Open Problems in Mechanistic Interpretability: A list of open problems poseted by a major researcher in the field
Prob/Soln.
- One big problem with open source research is that there are a lot of people eager to participate, but not enough bandwidth or scaffolding in the community to onboard those people. Even once those people are onboarded, it can be hard to integrate their work into the larger corpus of work.
- Solution: Thats right... you know it, you hate it. An LLM wrapper
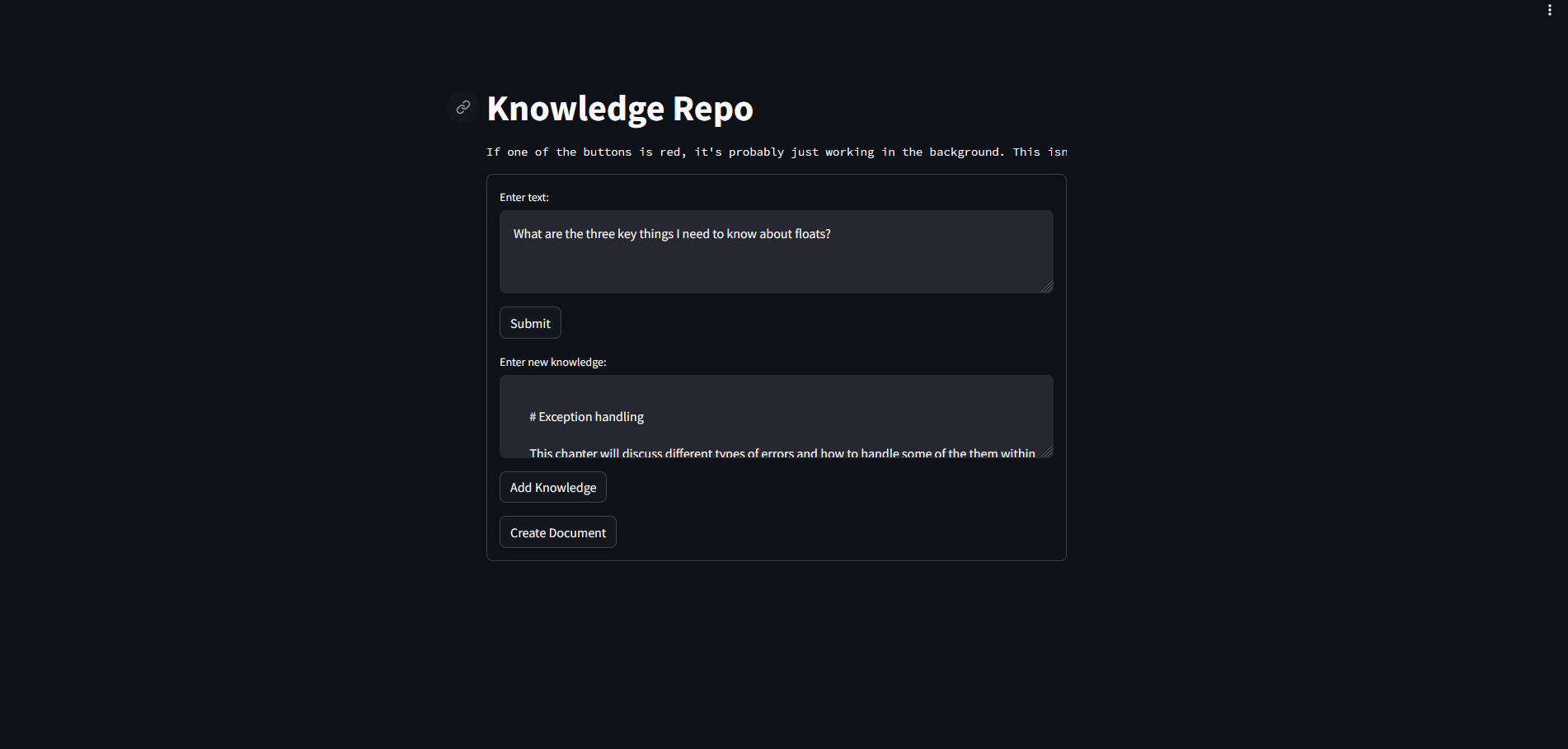
What it does
In a perfect world it allows a knowledge repo to automatically update itself with new info from users and allow the users to query that info.
In actuality... it tries to do those things but tosses out deranged ramblings
How we built it
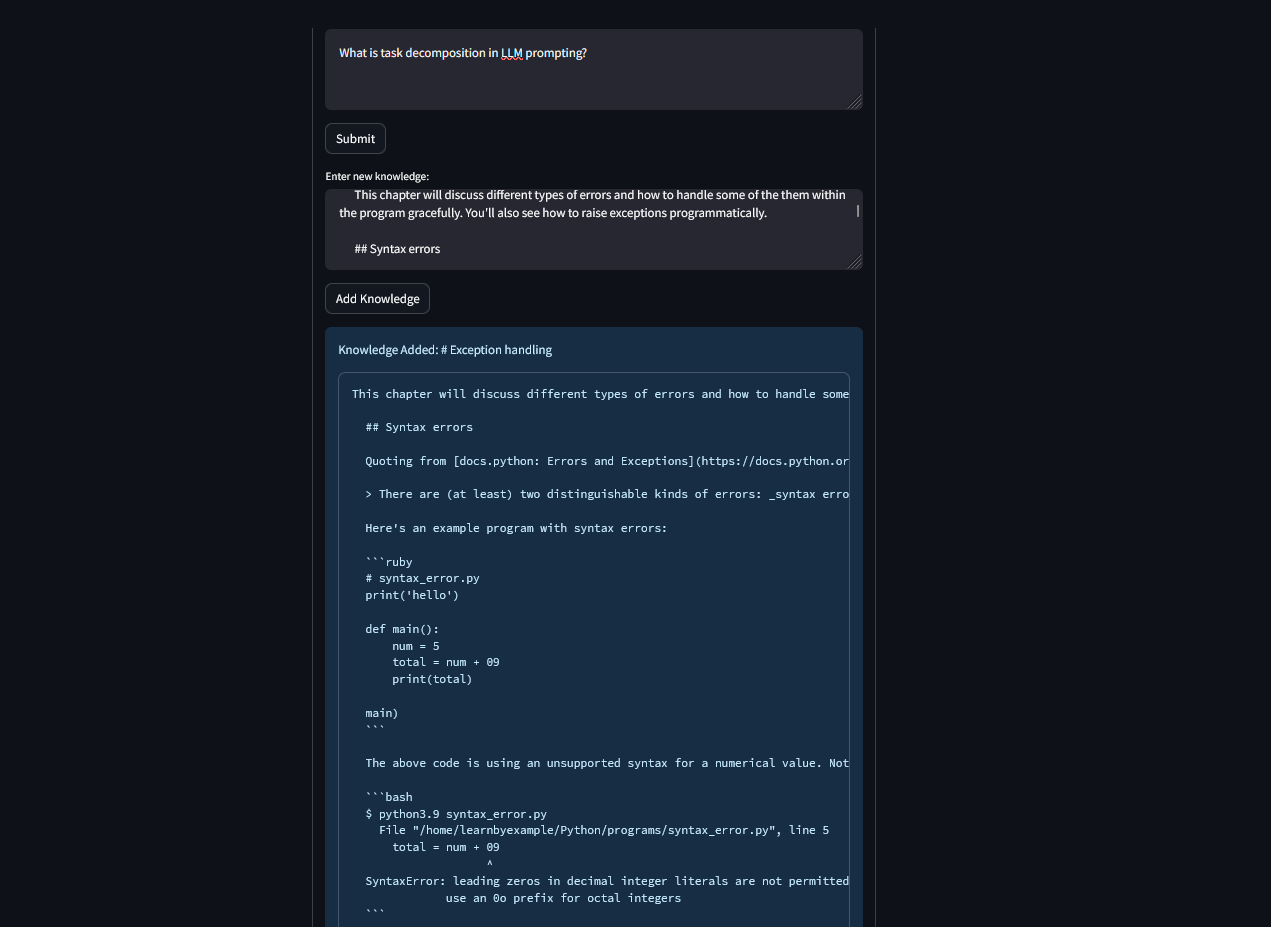
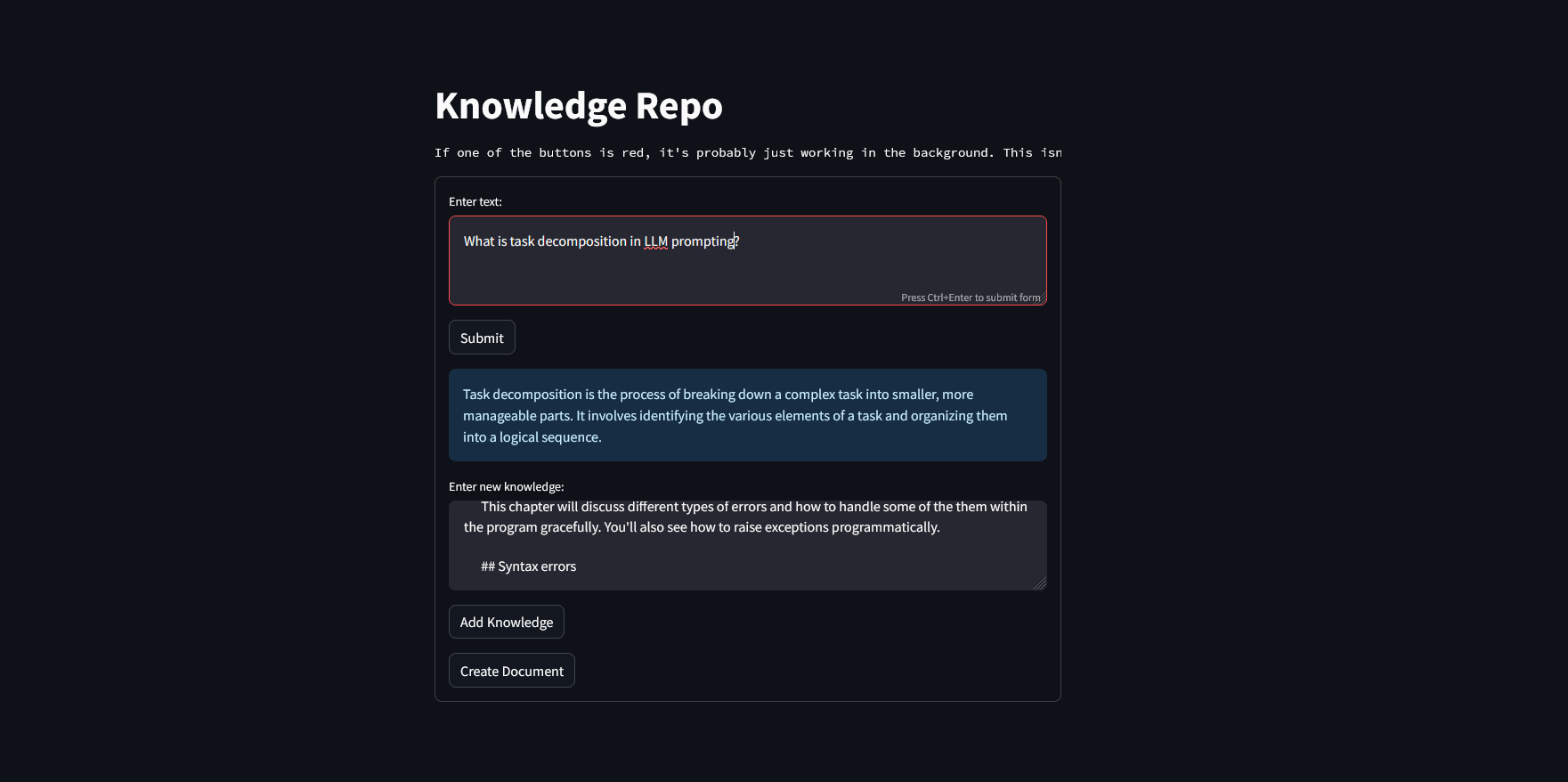
Built using langchain, huggingface transformers, colab, and streamlit to make a RAG agent -Given a markdown file, it breaks that file out into chunks. Those chunks are then embedded and added into a vectordb.
- That info can be retrieved by embedding a query and using that to find relevant chunks. That relevant info is then passed through an LLM.
- New info is compared against existing chunks & either added as a new chunk or appended to an existing one.
- If prompted, it grabs all chunks and formats them into a single file output.
Challenges we ran into
- LangChain has had numerous refactors so that made the documentation ab it hard to follow
- Lack of compute
Accomplishments that we're proud of
- Got to read some neat papers like the one introducing RAG, Chain of Thought, Tree of Thought, etc
- Got a pseudo-working solution put together
What we learned
- Got to learn some interesting task adaptation techniques like RAG & it's different flavors (i.e. RAPTOR and HyDE)
- Learned more about some buzzwords that are thrown around quite a bit!
- Learned about some new packages like LangChain and HuggingFace Transformers
What's next for Self Updating Knowledge Repo
Could be neat to continue to explore how models do with information from really recent research since that wouldn't be in their training set. Could further explore some of the things I tried out like different sub-techniques of RAG or finetuning
Built With
- colab
- huggingface
- langchain
- python
- streamlit

Log in or sign up for Devpost to join the conversation.