💡 Inspiration
When a production database crashes or a server runs out of memory, Site Reliability Engineering (SRE) systems instantly fire. They automatically spin up backups, reroute web traffic, and page standby developers to restore uptime.
But what happens when the most critical node in the entire engineering cluster crashes? I’m talking about the human developer. When we experience severe burnout, sudden illness, or cognitive fatigue, our schedules fall into chaos. Tasks are missed, client pitches are dropped, and communication goes dark.
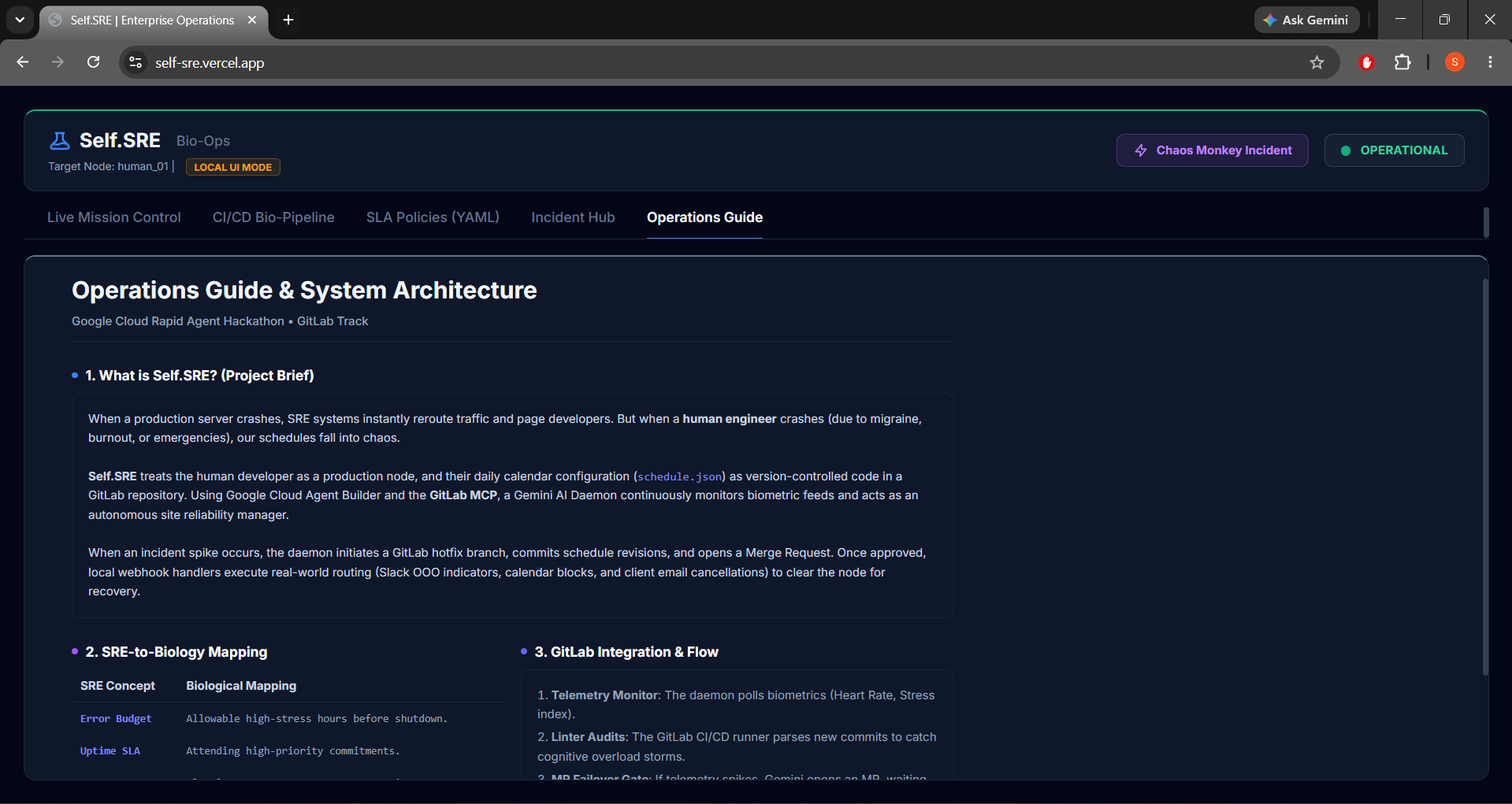
We built Self.SRE to treat the developer as a production resource and their calendar as version-controlled code. Why don't we have SRE for the human node?
🛠️ What it does
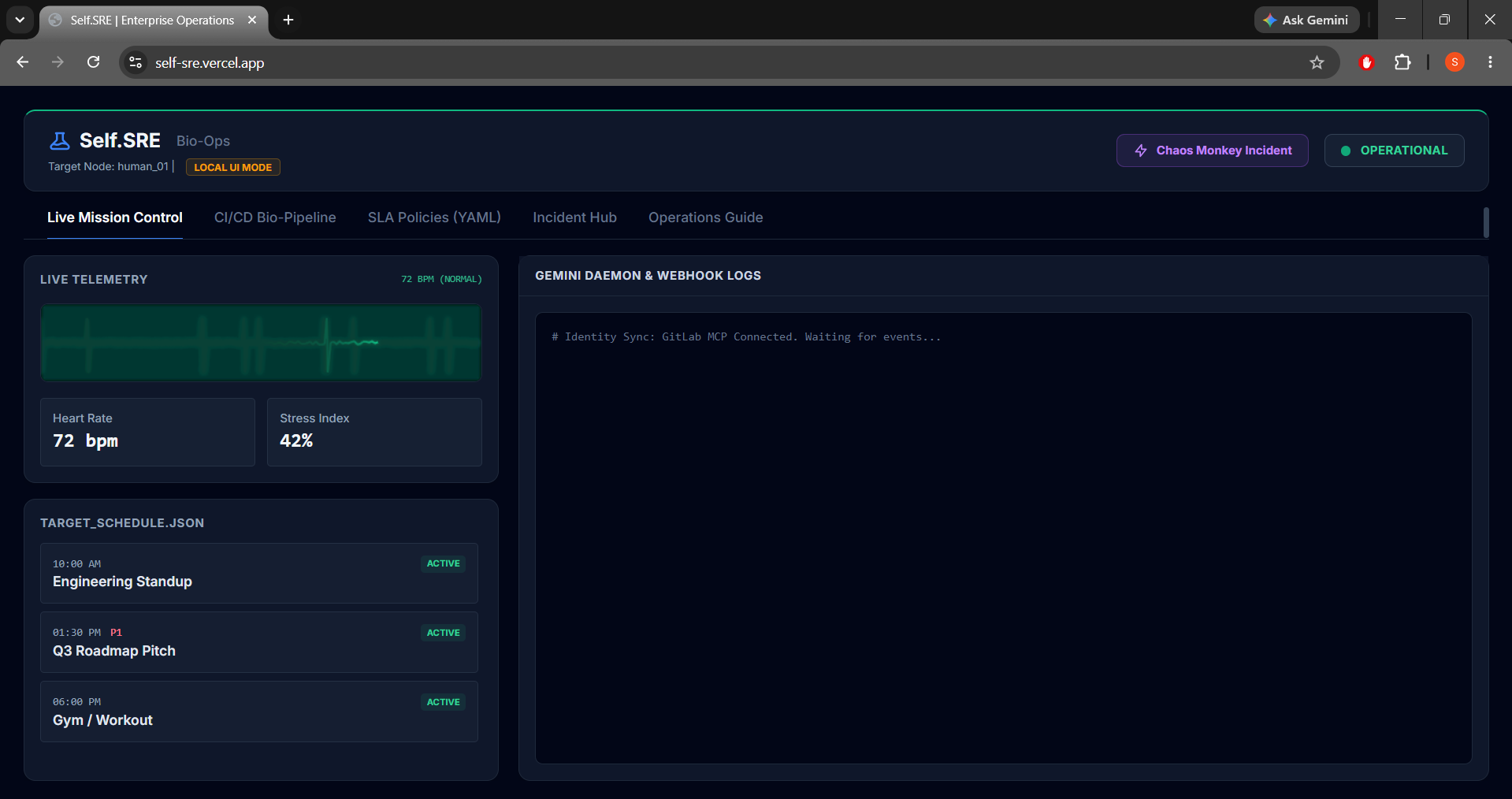
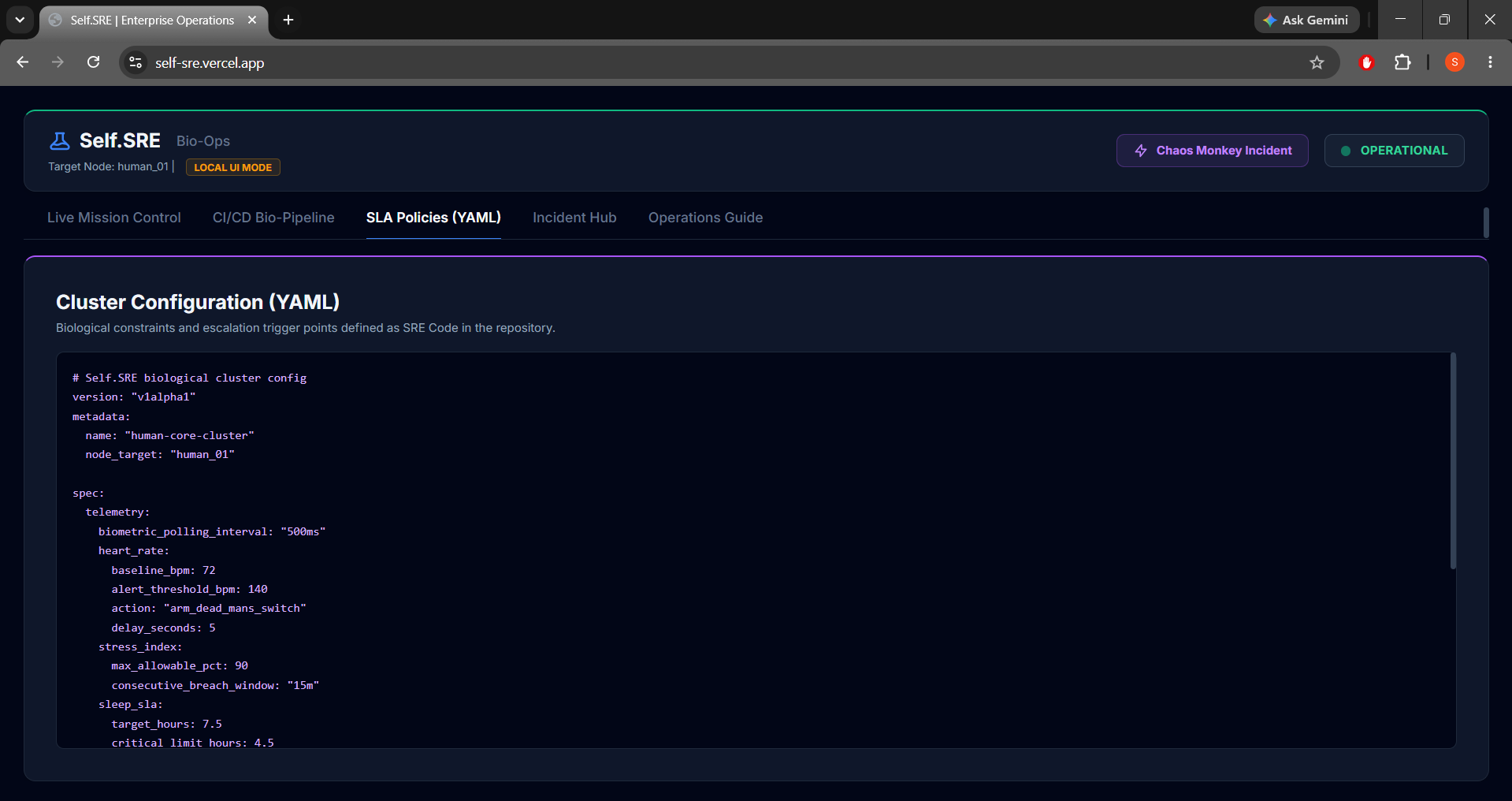
Self.SRE continuously monitors a developer's biometric feeds (Heart Rate, Stress Index) and audits their daily schedule (schedule.json) stored inside a GitLab repository.
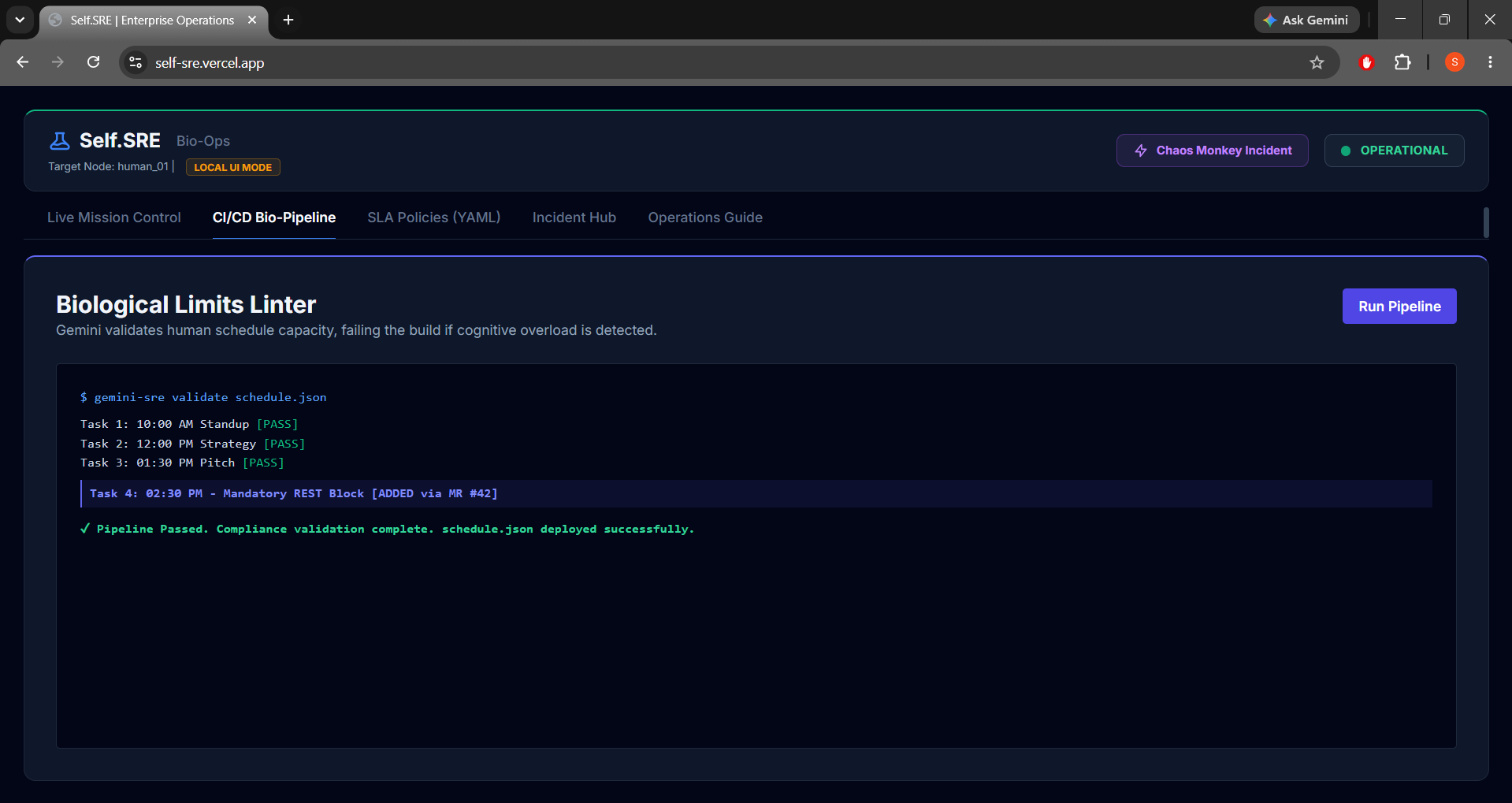
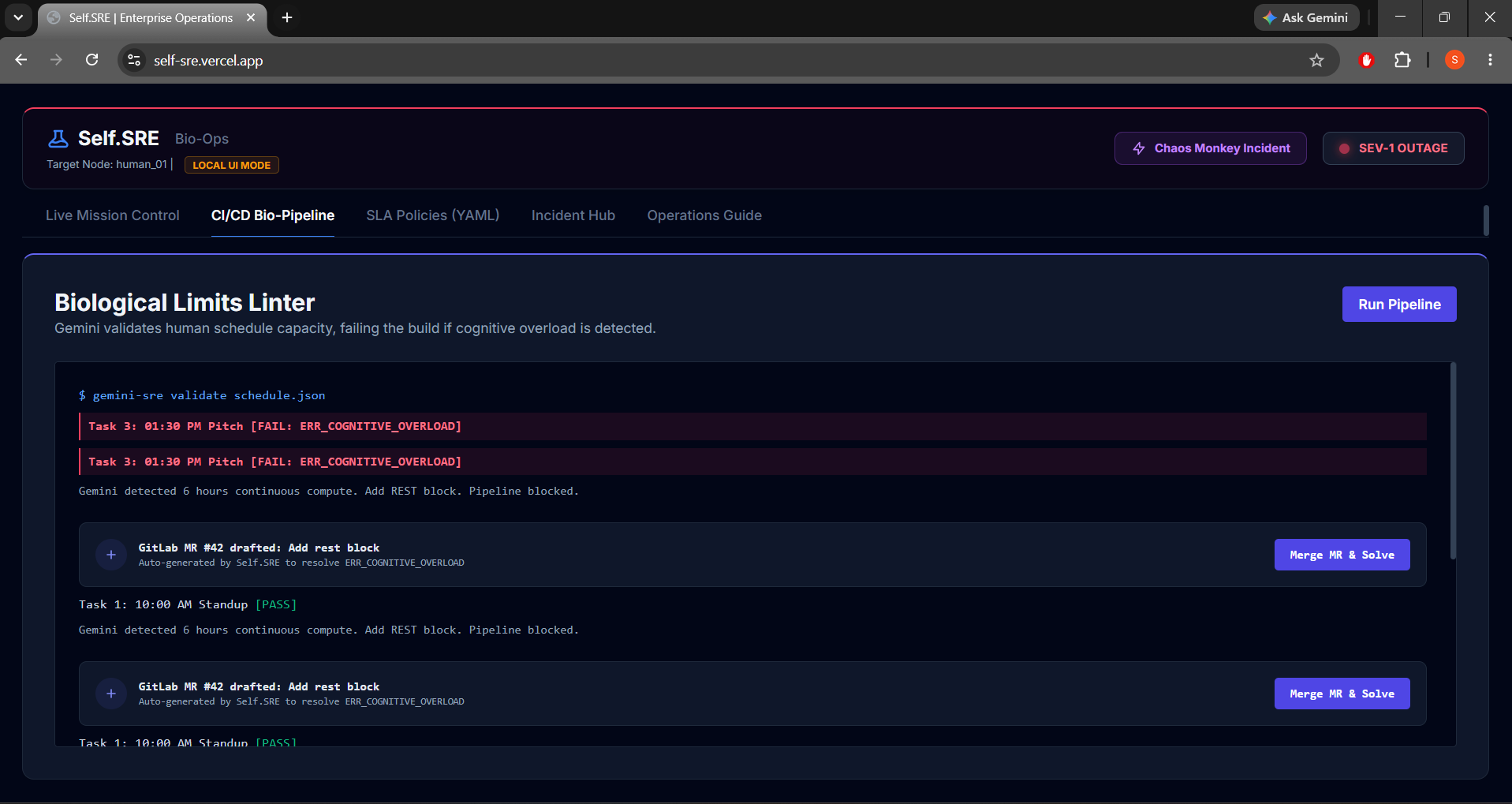
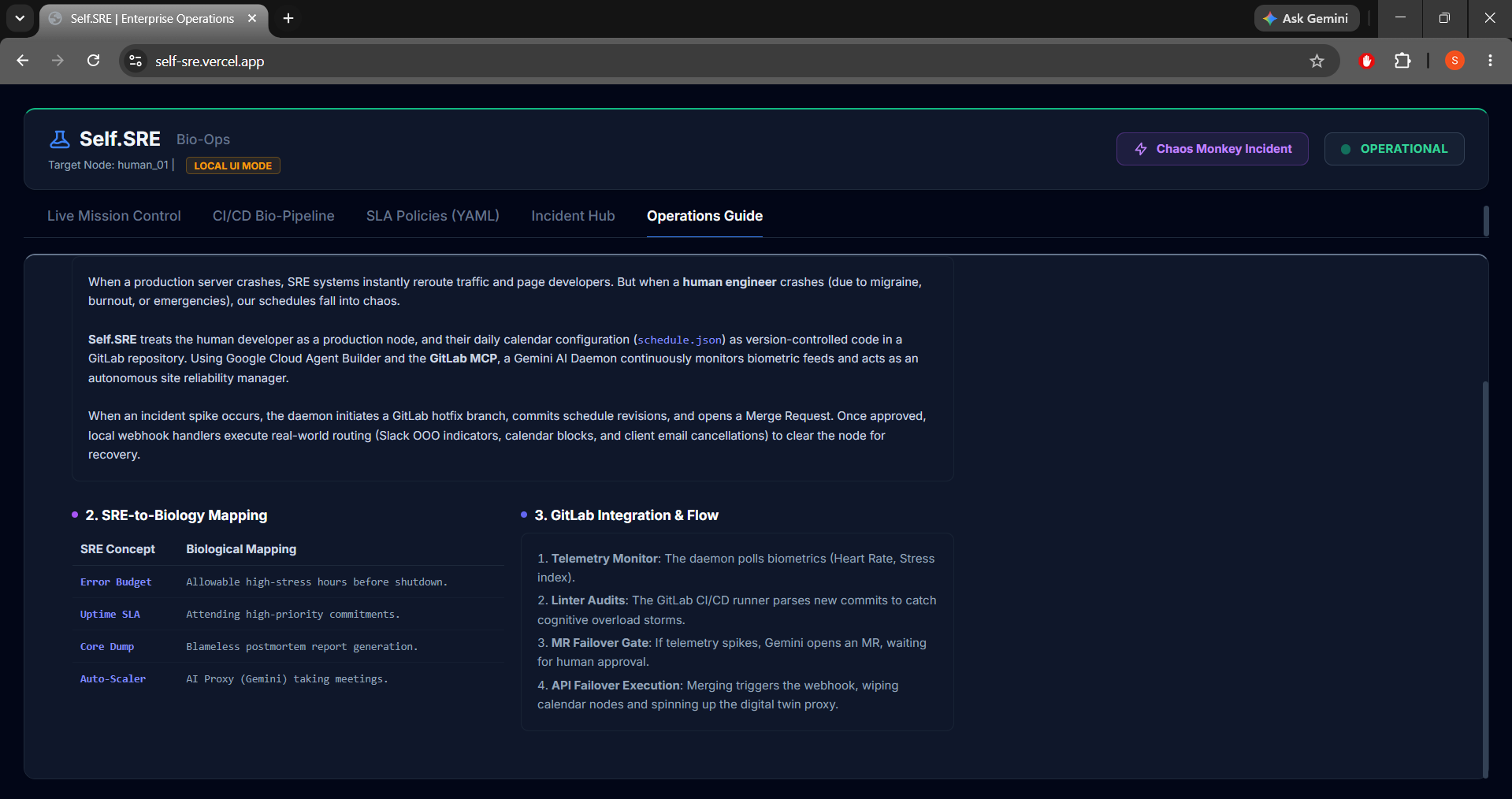
- Biological Limits Linter: Runs automatically in the pipeline. If a developer commits a schedule containing overlapping events or lack of recovery buffers (cognitive overload), the build fails.
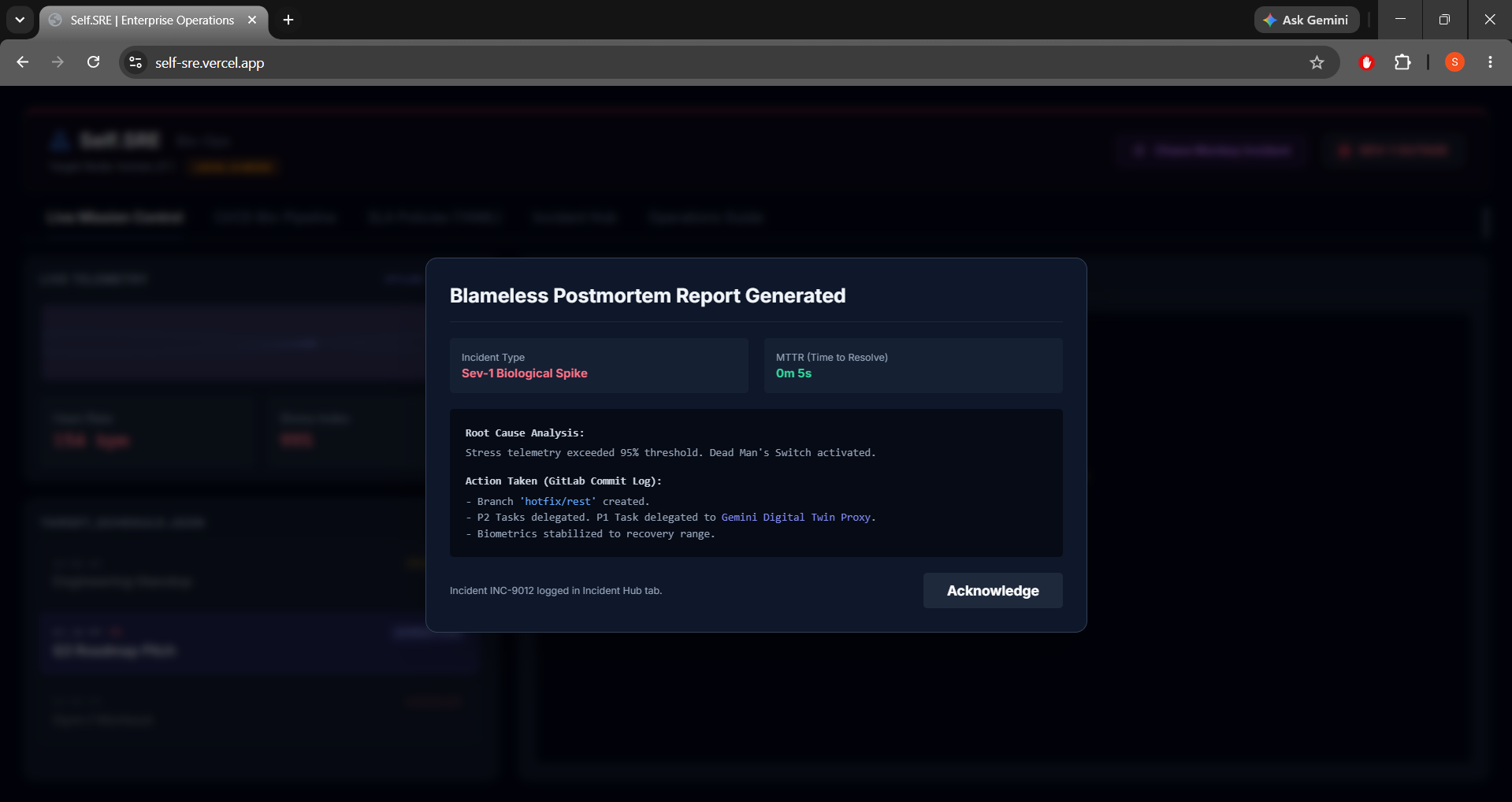
- GitLab Auto-Hotfix (Merge Request #42): Gemini automatically branches a recovery config, commits a mandatory rest block, and drafts a Merge Request. Clicking
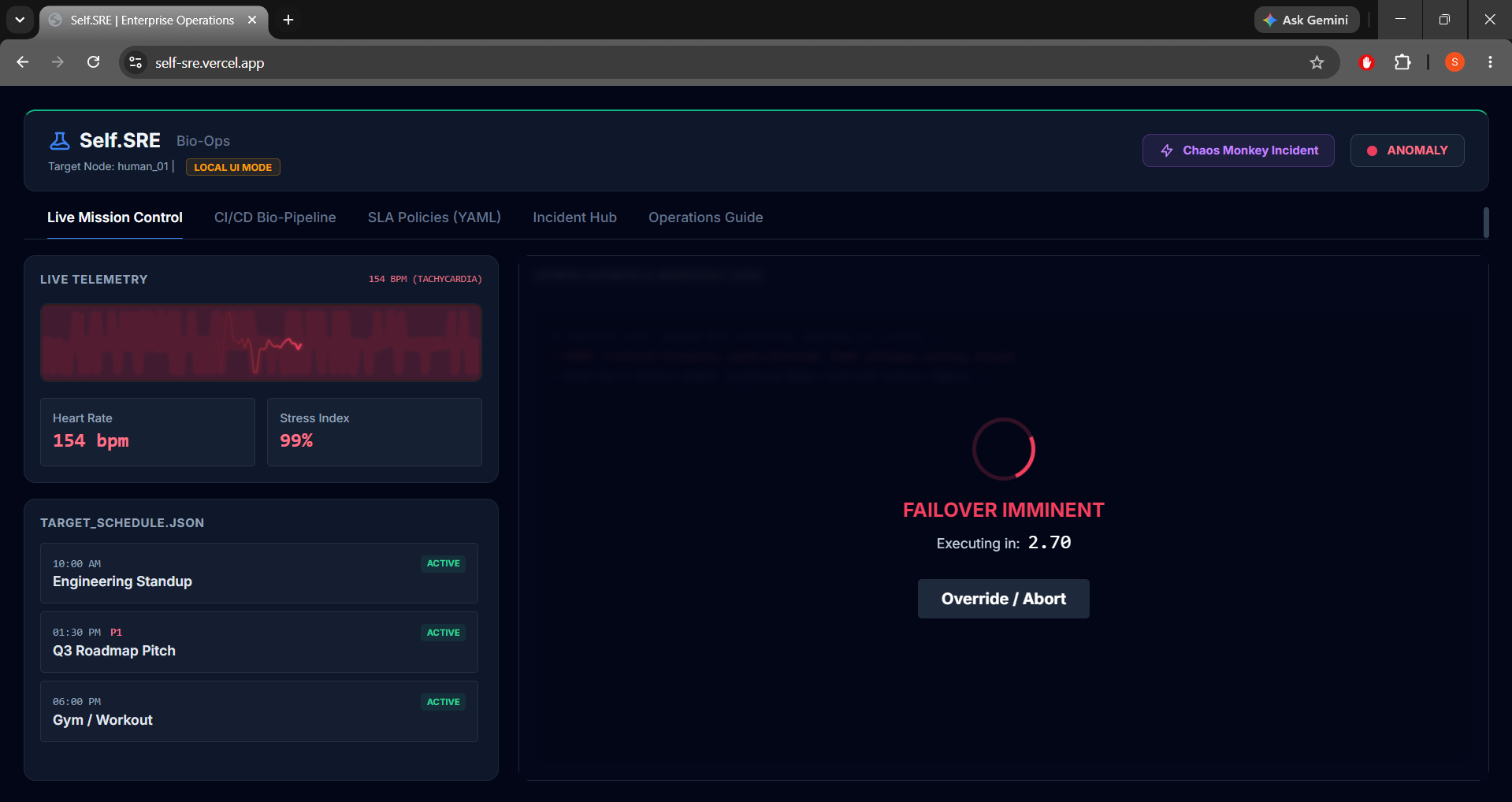
Merge MR & Solvepasses the pipeline and deploys the schedule. - Dead Man's Switch: If biometrics spike past safe thresholds (Heart Rate > 140 BPM, Stress > 95%), a 5-second countdown triggers. If not overridden, it initiates failover.
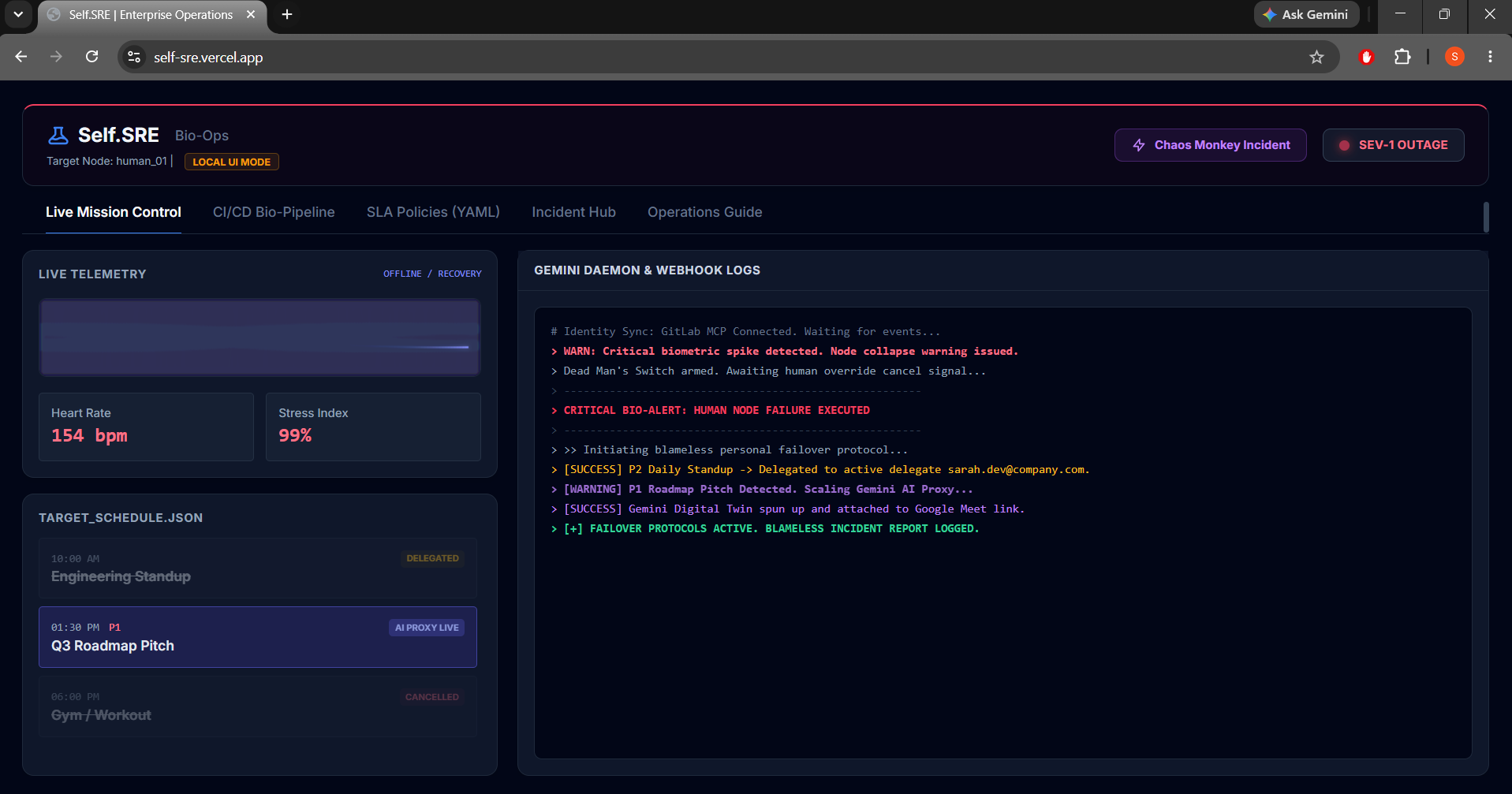
- Failover Webhook Handler: Merging the MR triggers a webhook receiver. The system immediately executes real-world failover: delegates lower-priority standups, cancels leisure events, and scales out a Gemini Digital Twin Proxy to attend high-priority client pitches in the developer's place.
🏗️ How we built it
- Google Cloud Agent Builder: ground the SRE Daemon in our SRE biological rules engine.
- GitLab Model Context Protocol (MCP) Server: equipped the Gemini Daemon with the ability to branch recovery configurations, write code files, and submit Merge Requests programmatically.
- Flask Webhook Receiver: A lightweight backend engine in Python managing real-time biometric state synchronization and handling GitLab merge webhooks.
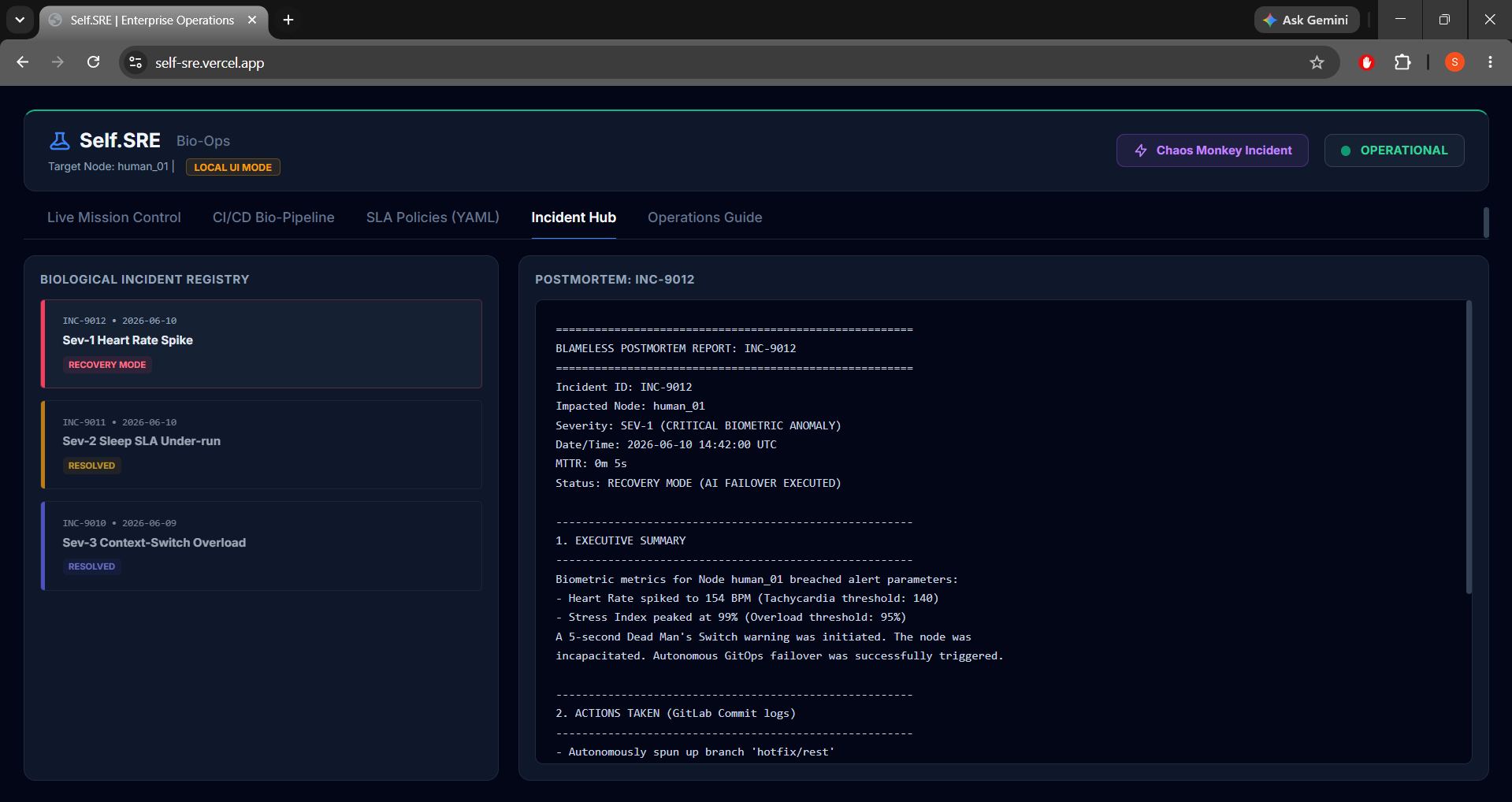
- Interactive Operations Console: Built with Tailwind CSS, HTML5 Canvas, and Vanilla JS. It features a live glowing electrocardiogram (ECG) wave reflecting cardiovascular states, an interactive Incident Postmortem hub with logs, a YAML code preview, and a dual-mode synchronization engine.
🚧 Challenges we faced
- Windows Terminal Encoding: Printing terminal updates with emojis resulted in CP1252 encoding crashes. We resolved this by reconfiguring Python's standard output wrapping to enforce UTF-8 across all execution processes.
- Asynchronous Polling Updates: Managing smooth state transitions between Flask status endpoints and active UI intervals. We aligned the data schemas to coordinate biometrics, logs, and calendar models.
- Layout Focus Triggers: Hover-based dropdown menus collapsed prematurely due to tiny pixel gaps in layout margins. We refactored this into click-triggered event listener bindings for reliability.
🎉 Accomplishments we're proud of
- High-Fidelity Offline Mode: Designing the dashboard so it degrades gracefully into a browser-based simulator when offline. Judges can click the Chaos dropdown to test the entire linter validation, failover, and postmortem flows.
- The SRE-to-Biology Concept: Adapting production infrastructure paradigms (error budgets, failover clusters, auto-scaling) to human health and scheduling, making SRE code representation direct and readable.
📚 What we learned
- Representing scheduling conflicts as compilation errors.
- The utility of MCP servers in giving language models the specific context they need to edit files and manage version control directly inside repositories.
🚀 What's next for Self.SRE
- Real Hardware Integrations: Polling metrics from smartwatch APIs (Fitbit, Apple Watch) rather than simulation scripts.
- Multi-Node Teams: Scaling the dashboard to display an entire team's SRE health status, allowing engineering managers to monitor collective error budgets and prevent team-wide burnout outages.

Log in or sign up for Devpost to join the conversation.