-
-
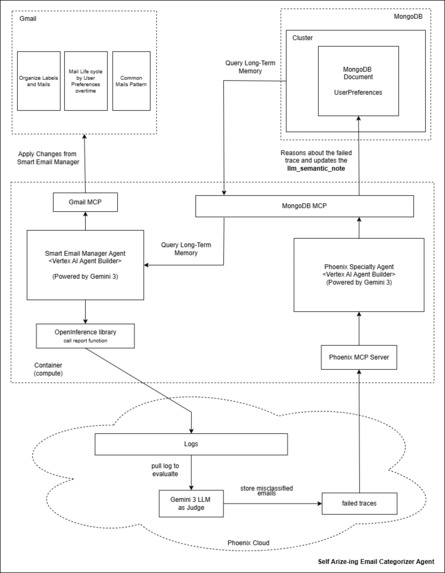
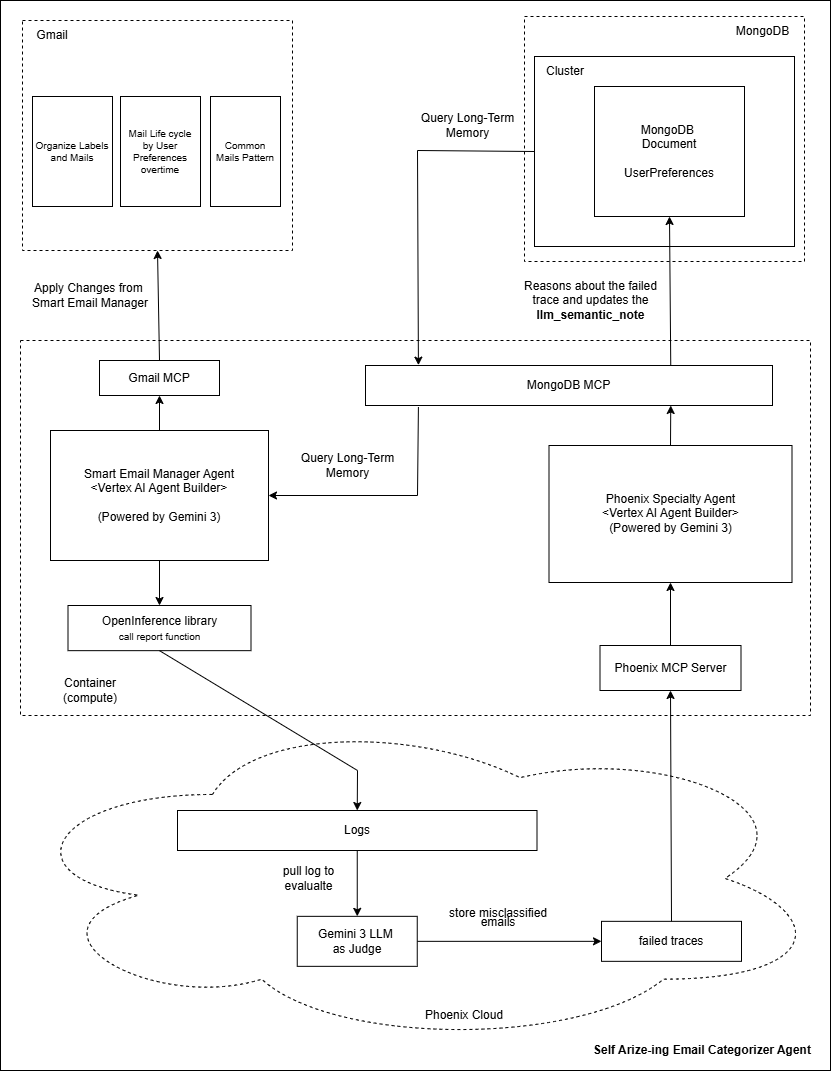
Self Arize-ing Email Categorizer Agent Architecture
-
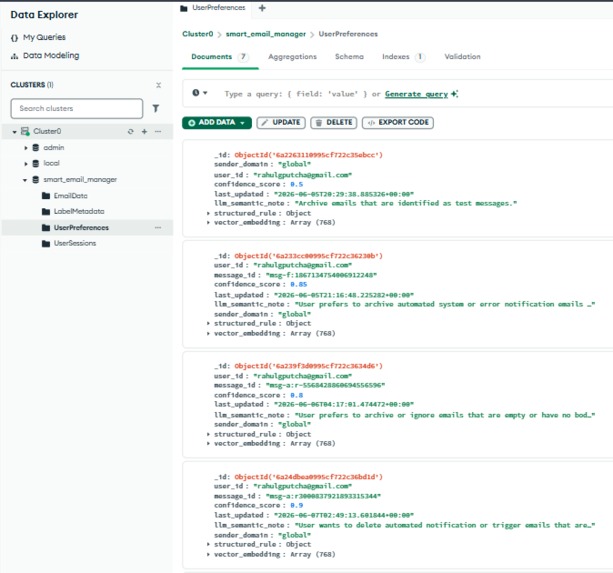
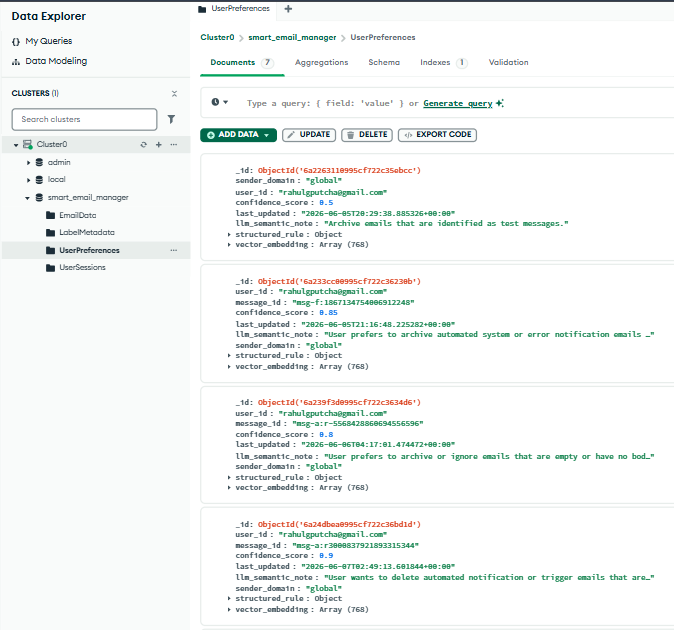
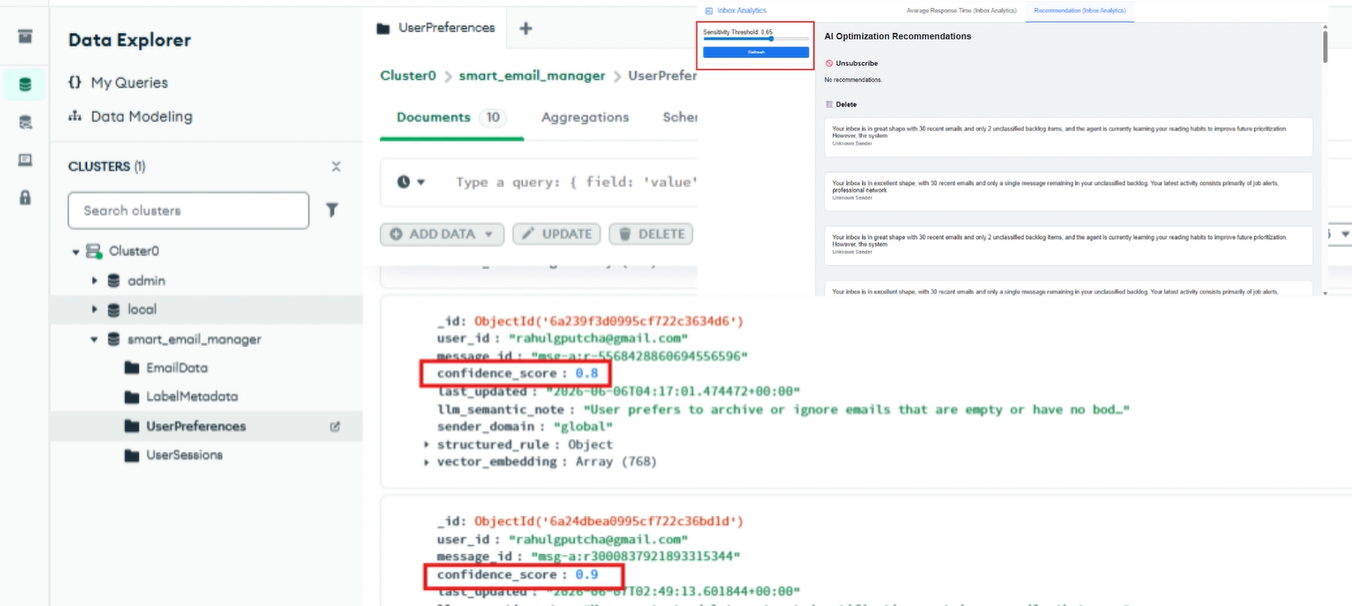
Self Arize-ing Manager - Learning Notes (User Preferences)
-
-
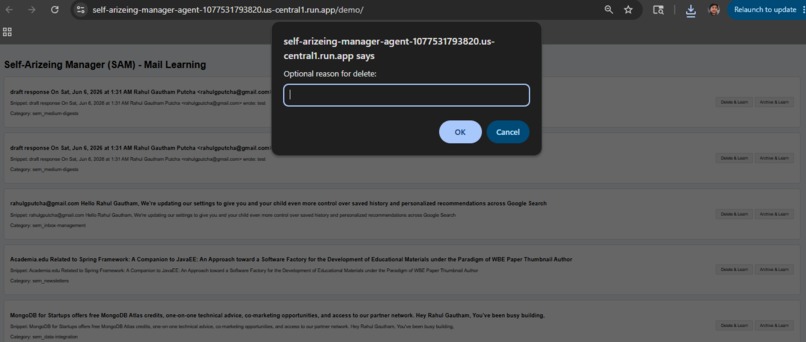
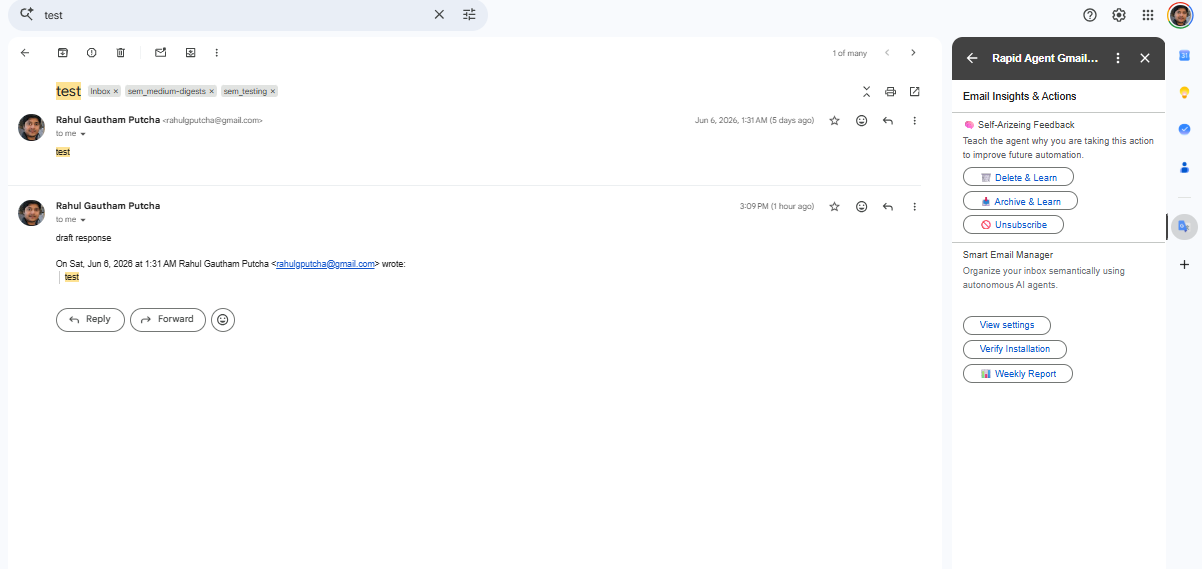
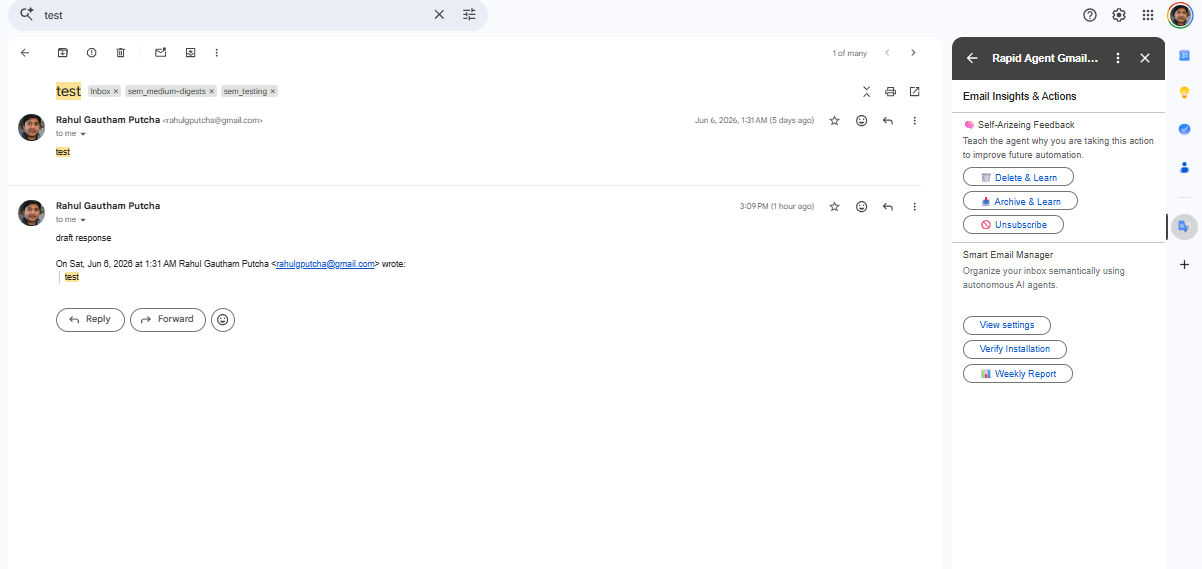
SAM UI
-
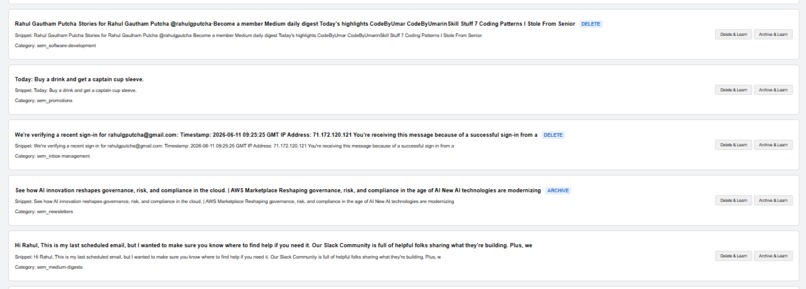
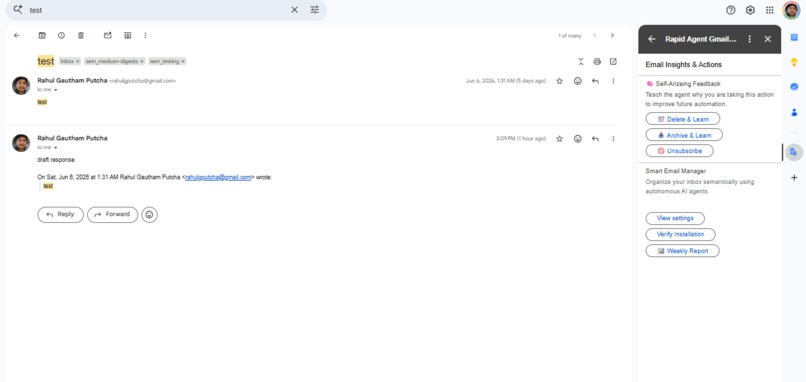
SAM UI
-
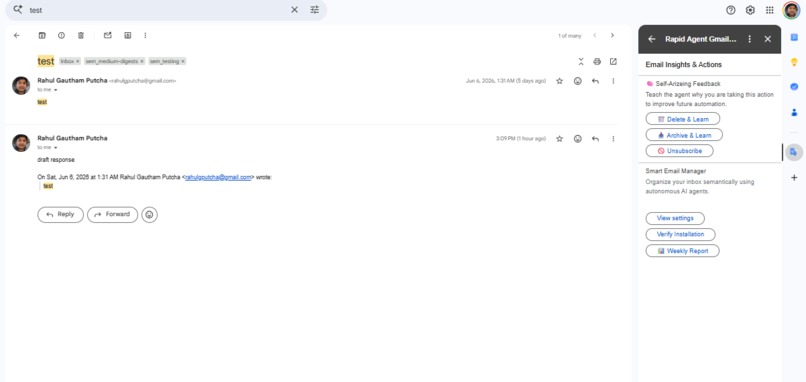
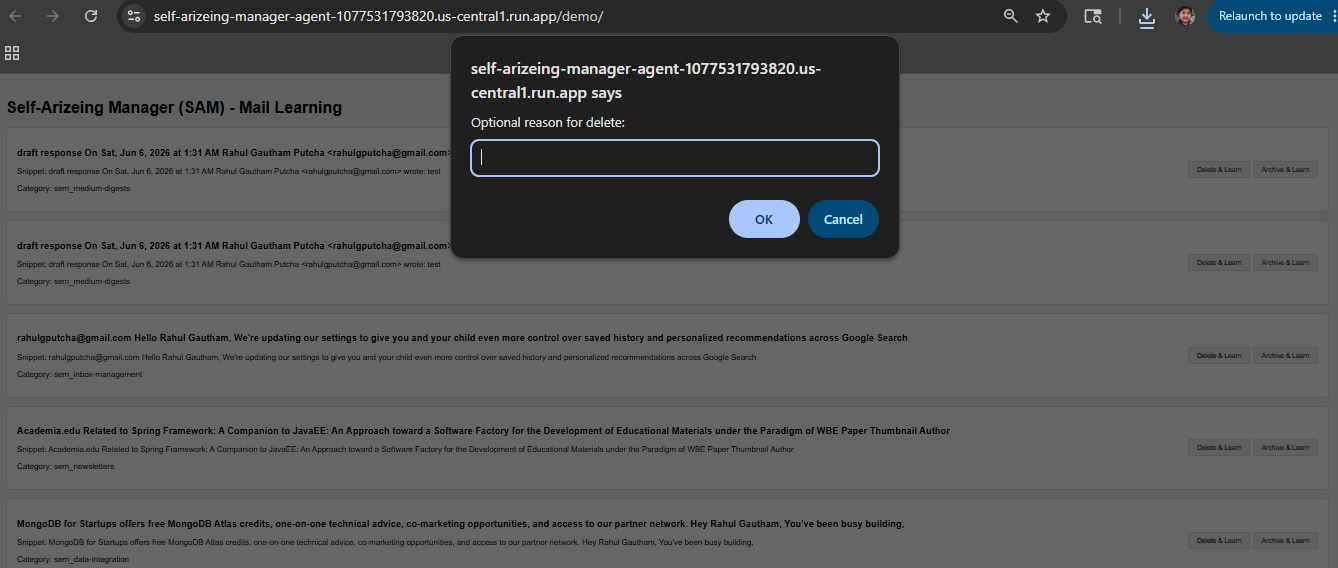
Google Plugin (SAM)
-
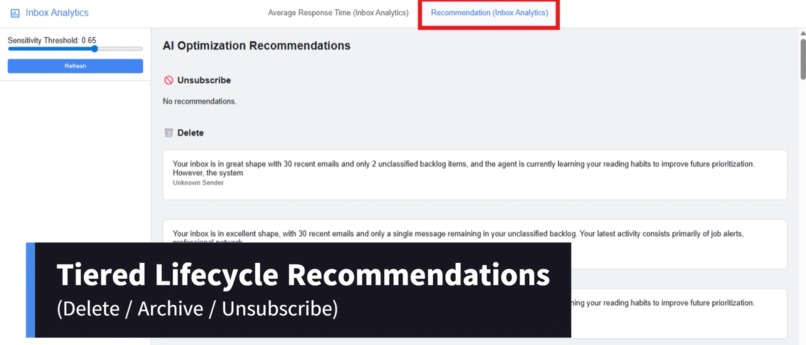
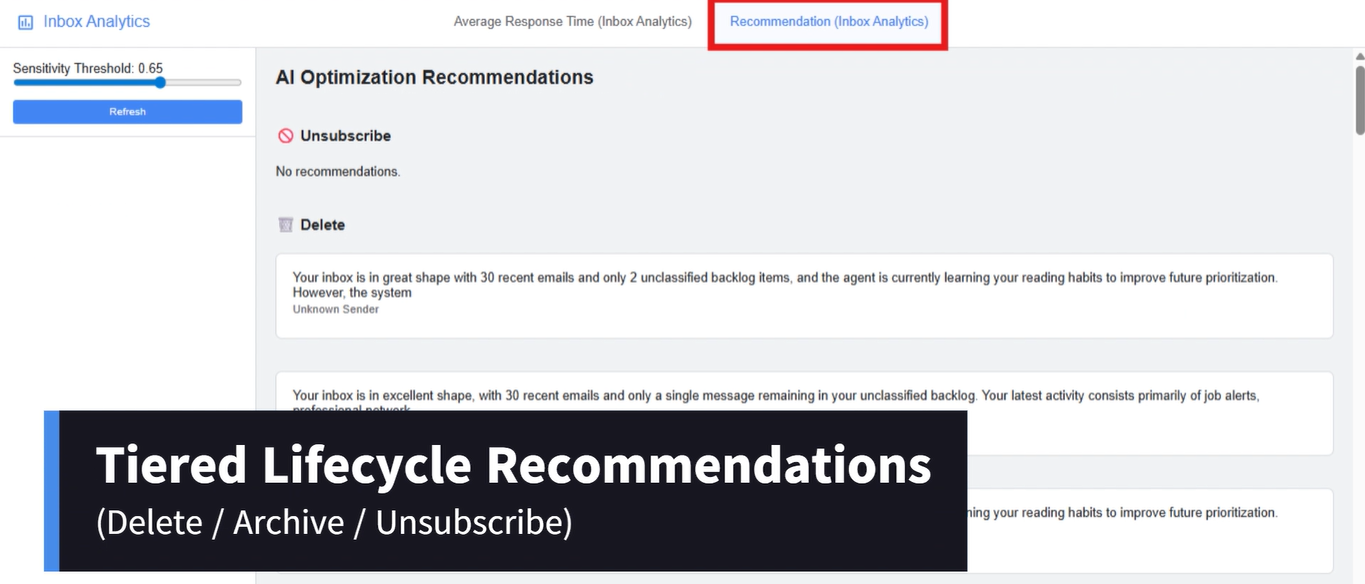
Recommendation (Inbox Analytics)
-
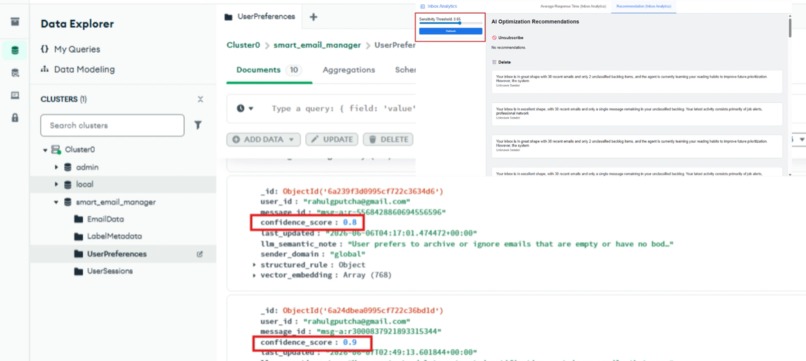
Recommendation (confidence score)
Self Arize-ing Manager (SAM)
A self-observing, autonomous "Agent-for-the-Agents" that monitors LLM performance and creates a self-improving feedback loop for smarter email management.
Inspiration
Even the best LLMs can occasionally misinterpret user intent or fail to categorize complex emails correctly. We were inspired to build a system that doesn't just work, but watches itself work. We wanted to create a "Self-Healing" architecture where the agent identifies its own mistakes, learns from them, and automatically updates the system's logic to prevent them from happening again.
What it does
SAM acts as the "Judge" and "Optimizer" for the entire multi-agent suite:
- Trace Monitoring: It continuously analyzes execution traces from other agents via Arize Phoenix.
- Failure Diagnosis: When a categorization fails or a user manually overrides an action (HITL), SAM evaluates the "Failed Trace" to understand the gap between the agent's logic and the user's intent.
- Autonomous Preference Learning: It generates structured "Semantic Preference Notes" based on these failures and stores them in MongoDB.
- Self-Improvement: These learned notes are then used by the Smart Email Manager and Inbox Analytics agents to refine future decisions, effectively allowing the system to "self-arize" and improve over time without manual code changes.
How we built it
SAM was built using a cutting-edge observability and orchestration stack:
- Observability: Integrated Arize Phoenix to capture deep execution traces, including retrieval context and prompt tokens.
- Intelligence: Leveraged Gemini 3.5 Flash as an "LLM-as-a-Judge" to evaluate trace quality and synthesize new user rules.
- Operational Store: Used MongoDB Atlas to store the evolving set of user preferences and semantic notes.
- Orchestration: Built on Google Cloud Run using FastAPI and the Model Context Protocol (MCP) to interact with telemetry and database tools.
- Standardization: Implemented a unified Vertex AI (
text-embedding-004) pipeline to ensure SAM's learned preferences are immediately searchable by other agents.
Challenges we ran into
The primary challenge was "Extracting Signal from Noise." Execution traces can be incredibly verbose. We had to design a highly specific evaluation prompt to ensure SAM only learned from meaningful failures rather than transient errors. We also navigated complex "Schema Drift" when transitioning from legacy Voyage embeddings to the unified Vertex AI standard, necessitating a manual migration of all past "learned memories" to keep them compatible with the latest analytics engine.
Accomplishments that we're proud of
We are proud of our Autonomous Feedback Loop. It’s one thing for an agent to perform a task, but it’s another for it to realize it failed and teach itself how to succeed next time. Seeing SAM successfully identify a manual "Delete" action, diagnose why the classifier missed it, and generate a new preference rule that fixed future sorting felt like watching the system truly "come alive."
What we learned
We learned that Observability is not just for debugging; it’s a Data Source. By treating trace logs as a stream of learning opportunities, we transformed a standard monitoring tool into the heart of our system's intelligence. We also learned the importance of transactional integrity when an agent is responsible for writing its own future logic.
What's next for Self Arize-ing Email Categorizer
Our roadmap includes:
- Proactive Conflict Resolution: Identifying when two learned rules contradict each other and autonomously merging them into a more nuanced instruction.
- Confidence-Based HITL: SAM will eventually "flag" low-confidence decisions before they are executed, asking the user for guidance and learning from the resulting interaction.
- Performance Benchmarking: Implementing automated A/B testing where SAM compares different prompt versions and autonomously promotes the one that results in fewer user overrides.
Built With
- arize
- docker
- gcloud
- gcp
- gmail
- google-apps-script
- google-cloud
- google-cloud-run
- google-gmail-oauth
- mcp
- mongodb
- phoenix-cloud
- python




Log in or sign up for Devpost to join the conversation.