-
-
Selene cover image
-
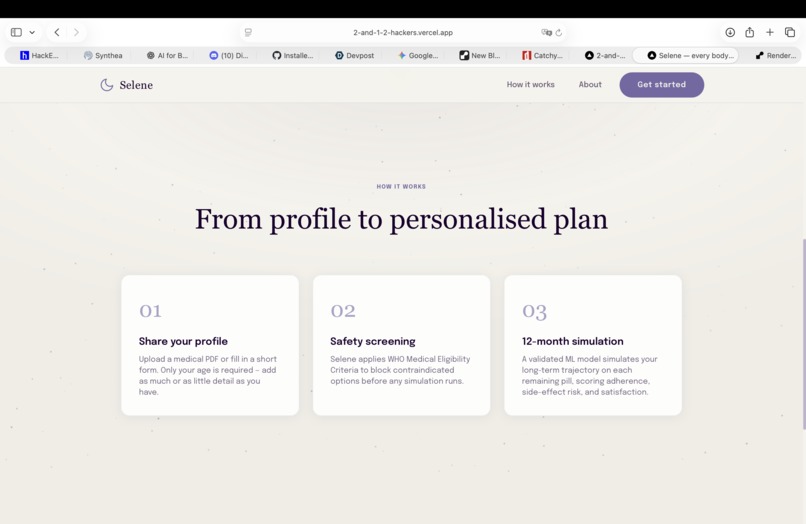
How it works: from profile to personalized plan
-
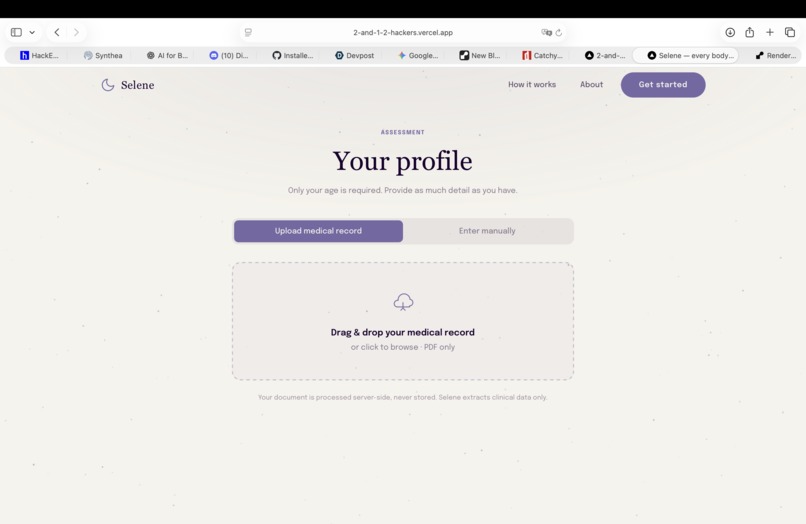
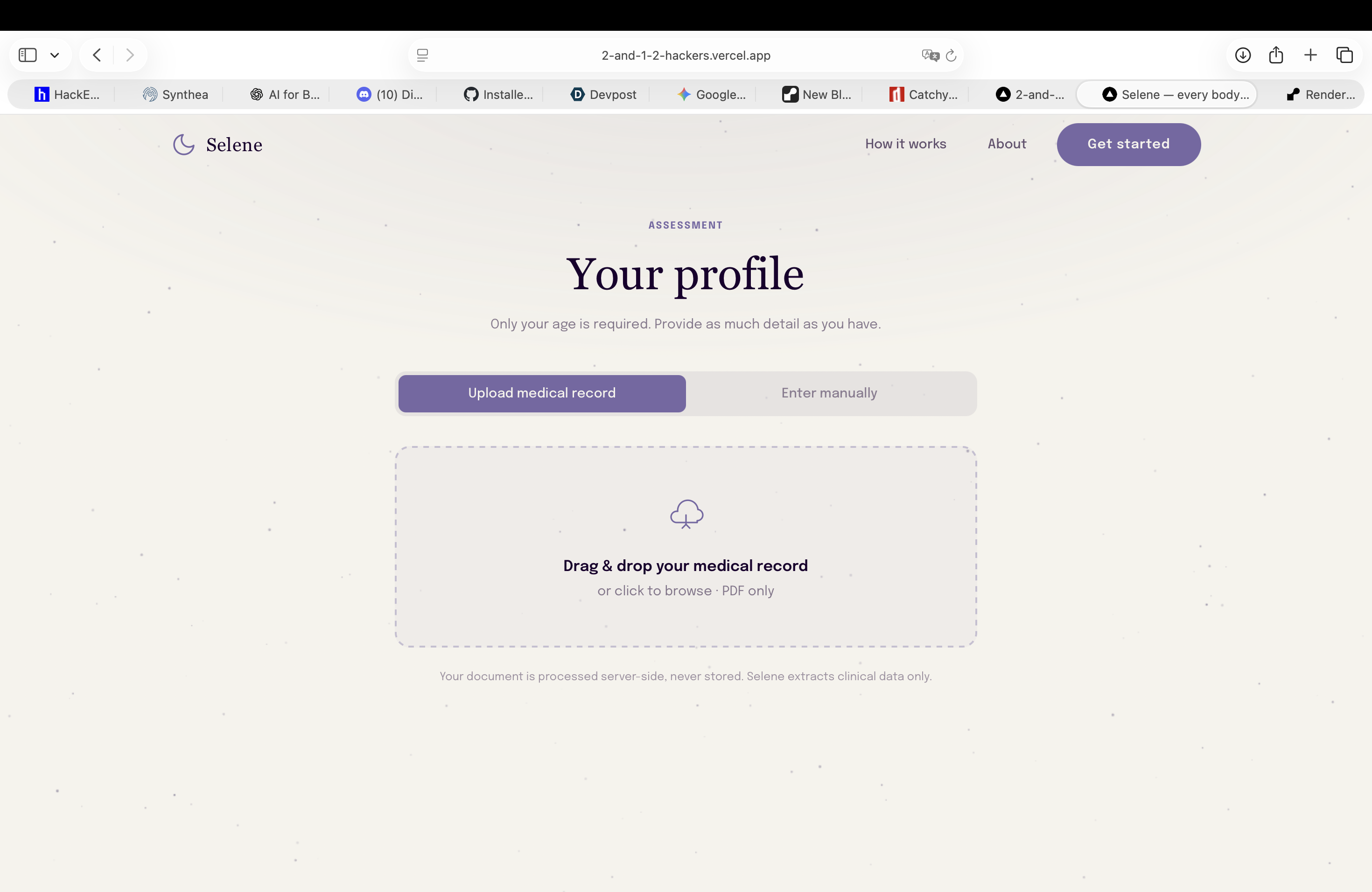
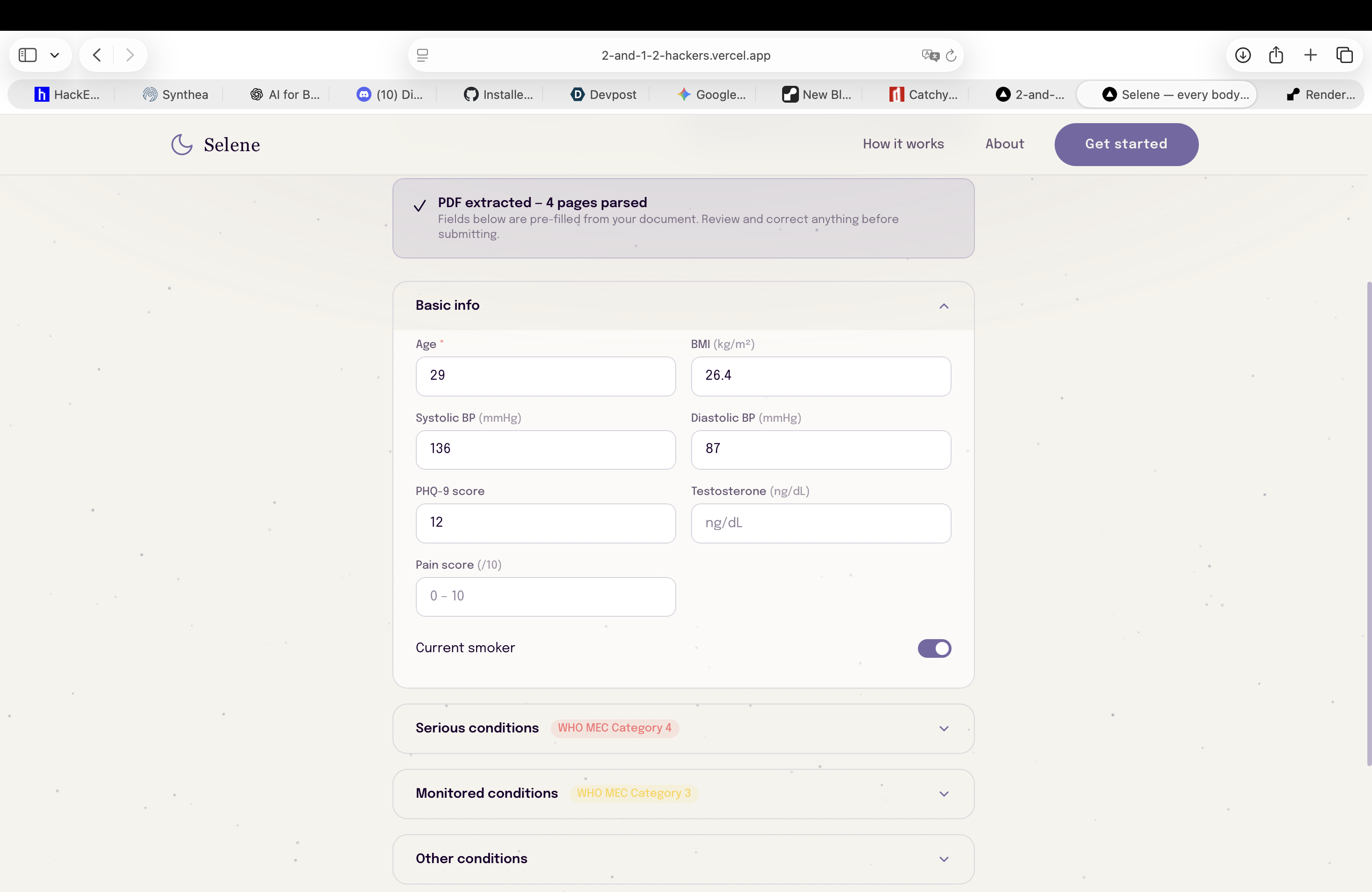
Start session: add your medical info, either manually or by uploading a a pdf of your medical record
-
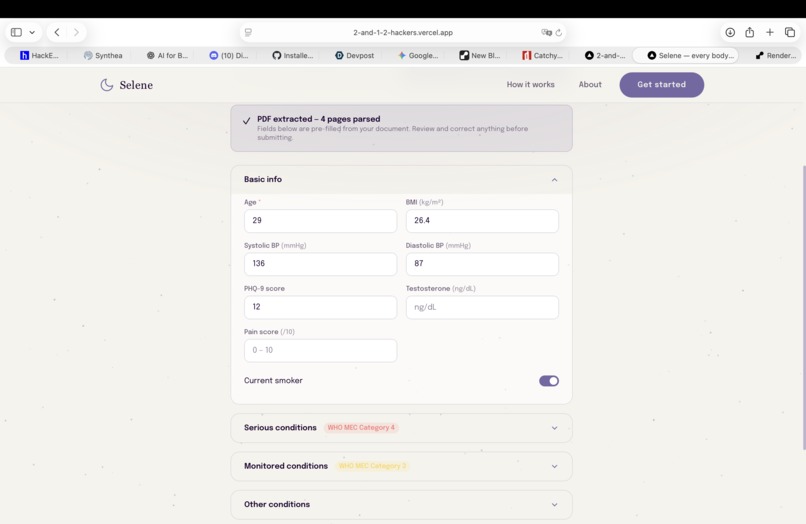
Modify your data
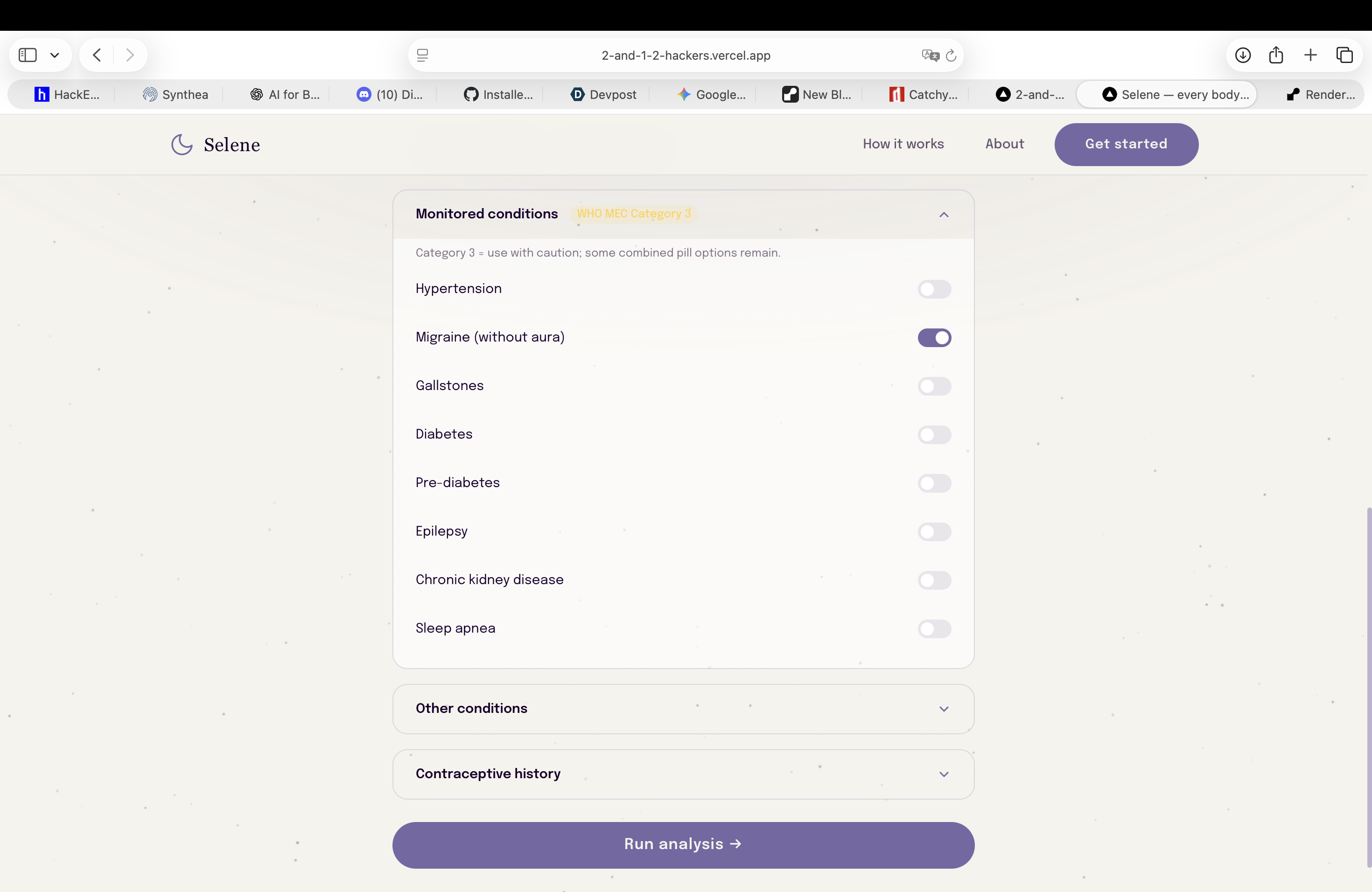
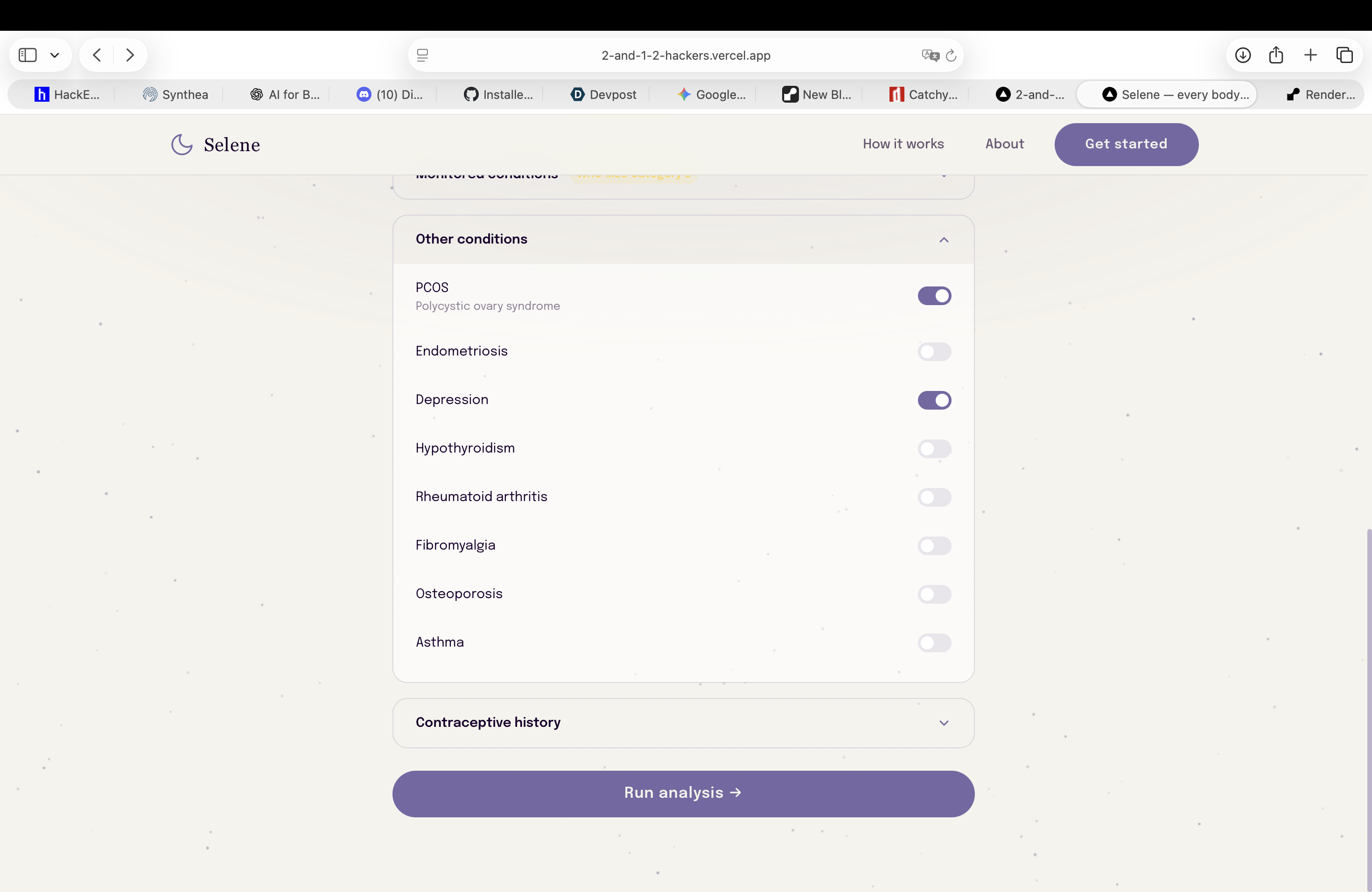
-
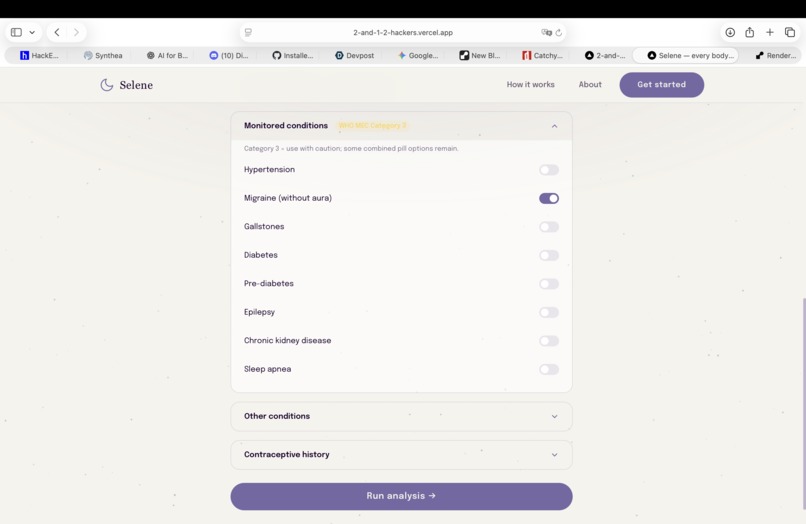
Modify your data
-

Submit your data
-
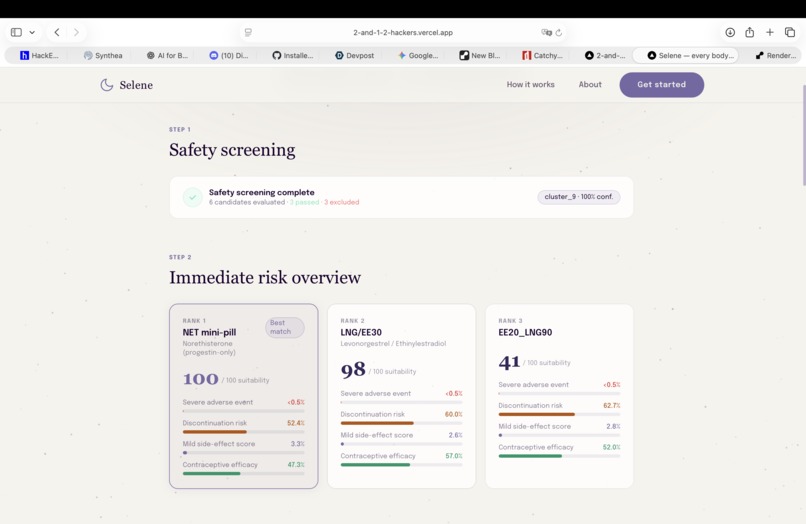
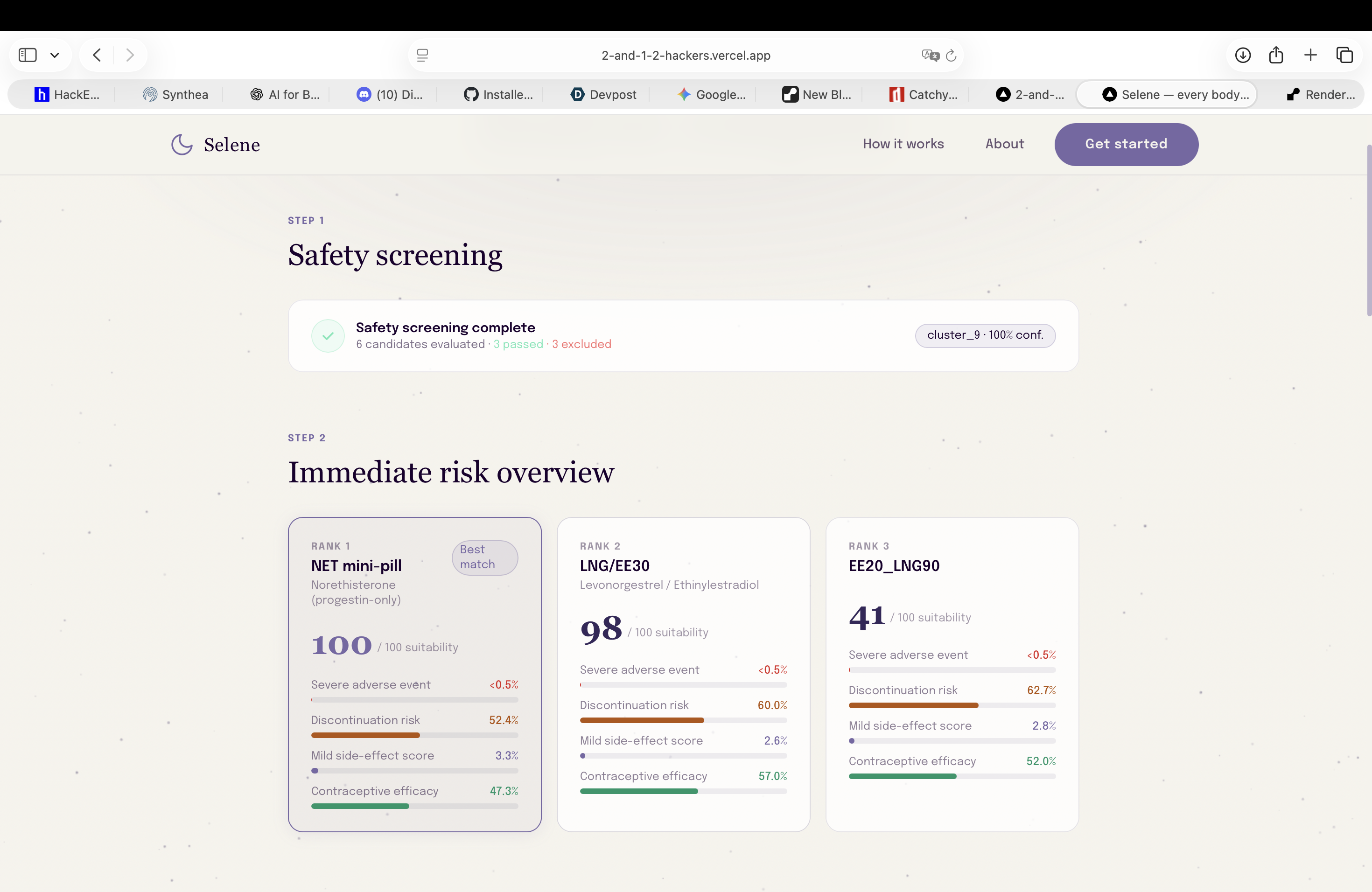
First step prediction: risk assessment of pills against clustered user profile (first agent prediction using Clustering ML model)
-
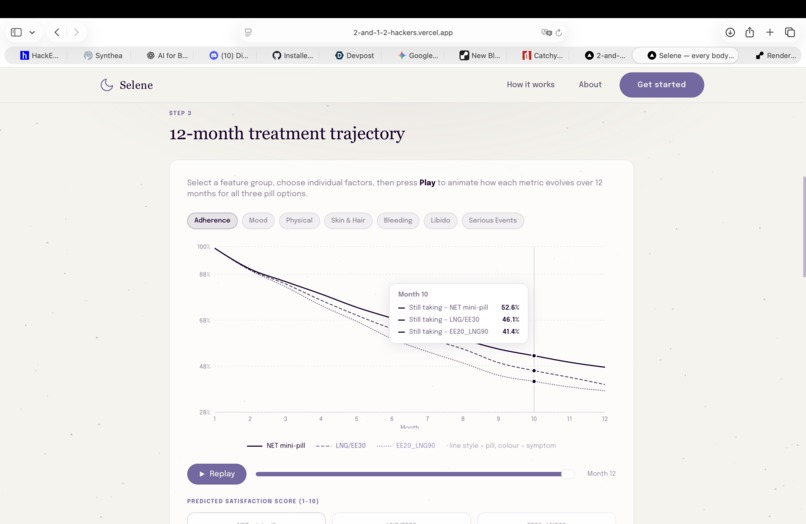
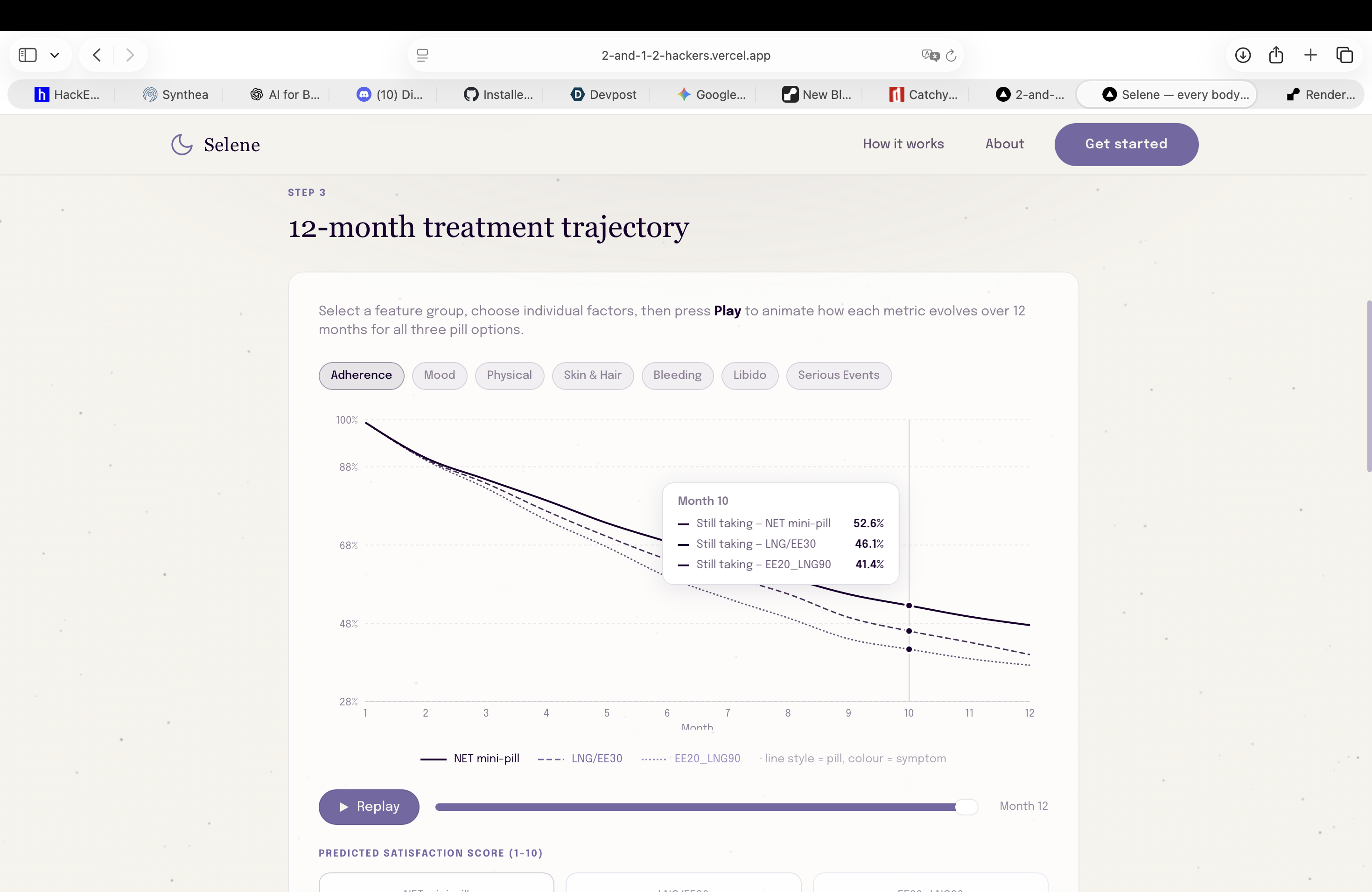
Second step prediction: realistic long time simulations (12 months) of low-risk pills against actual patient data (treatment adherence)
-
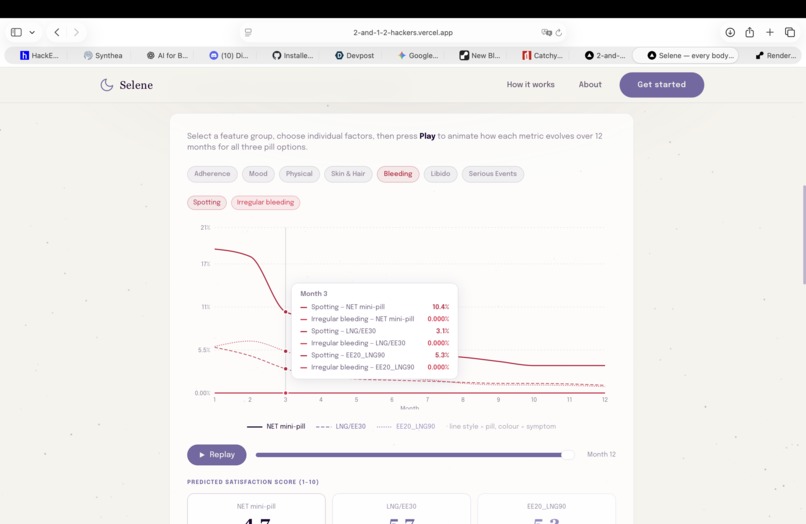
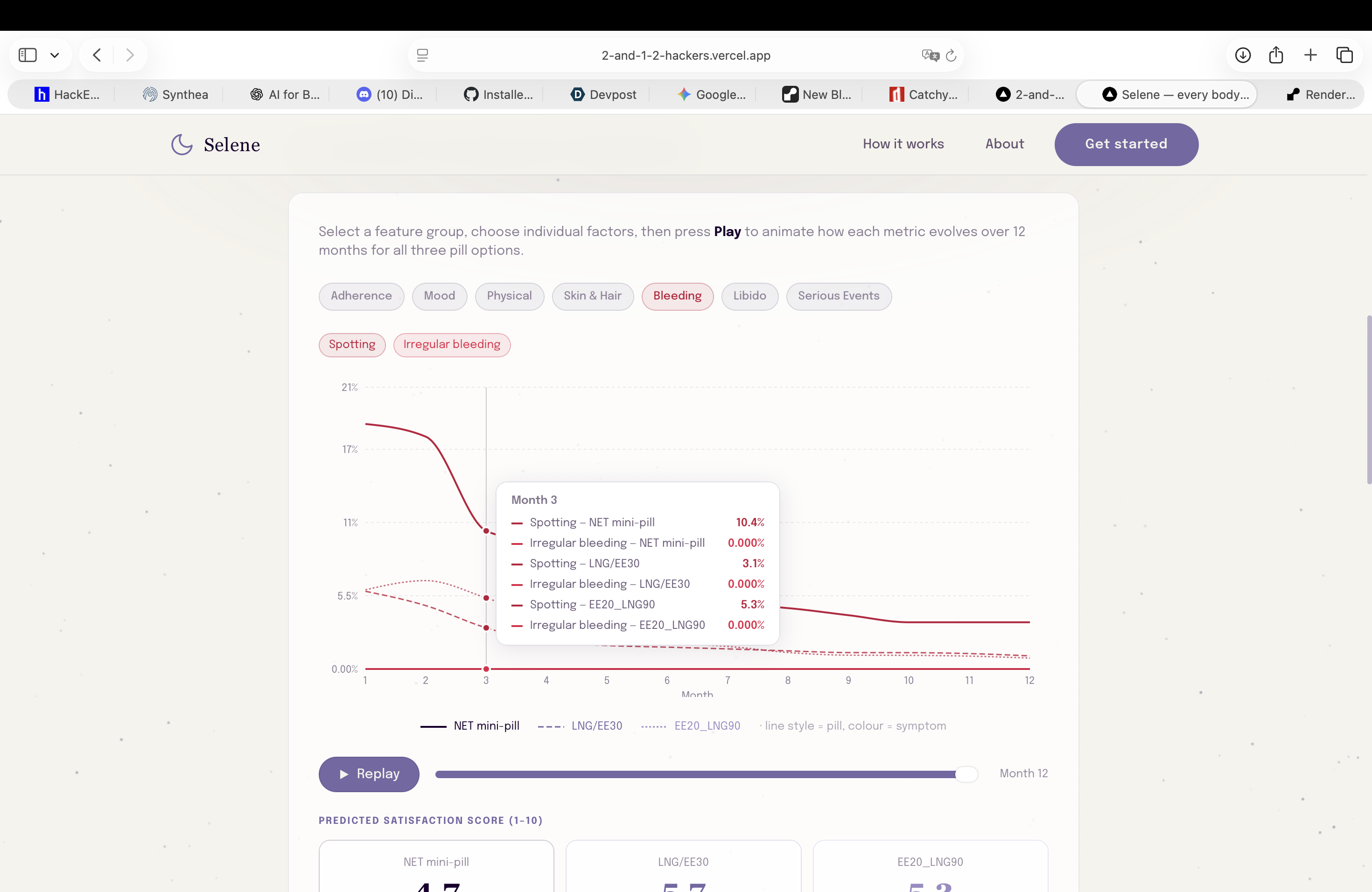
Second step prediction: realistic long time simulations (12 months) of low-risk pills against actual patient data (bleeding)
-
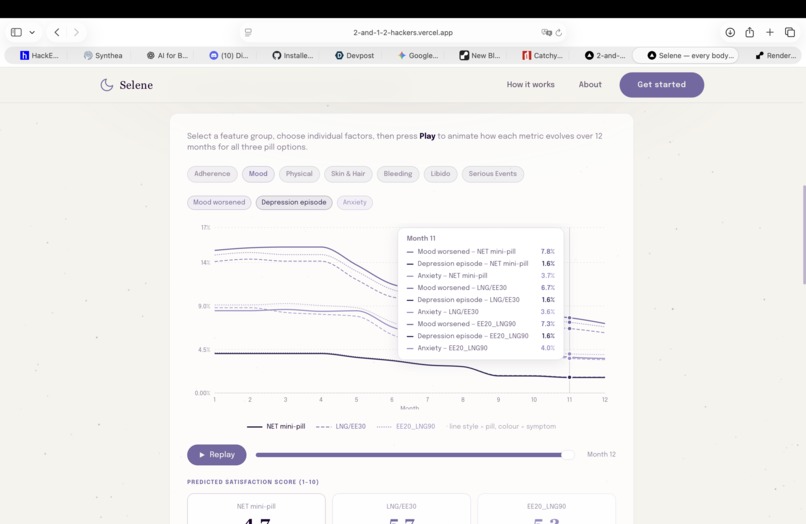
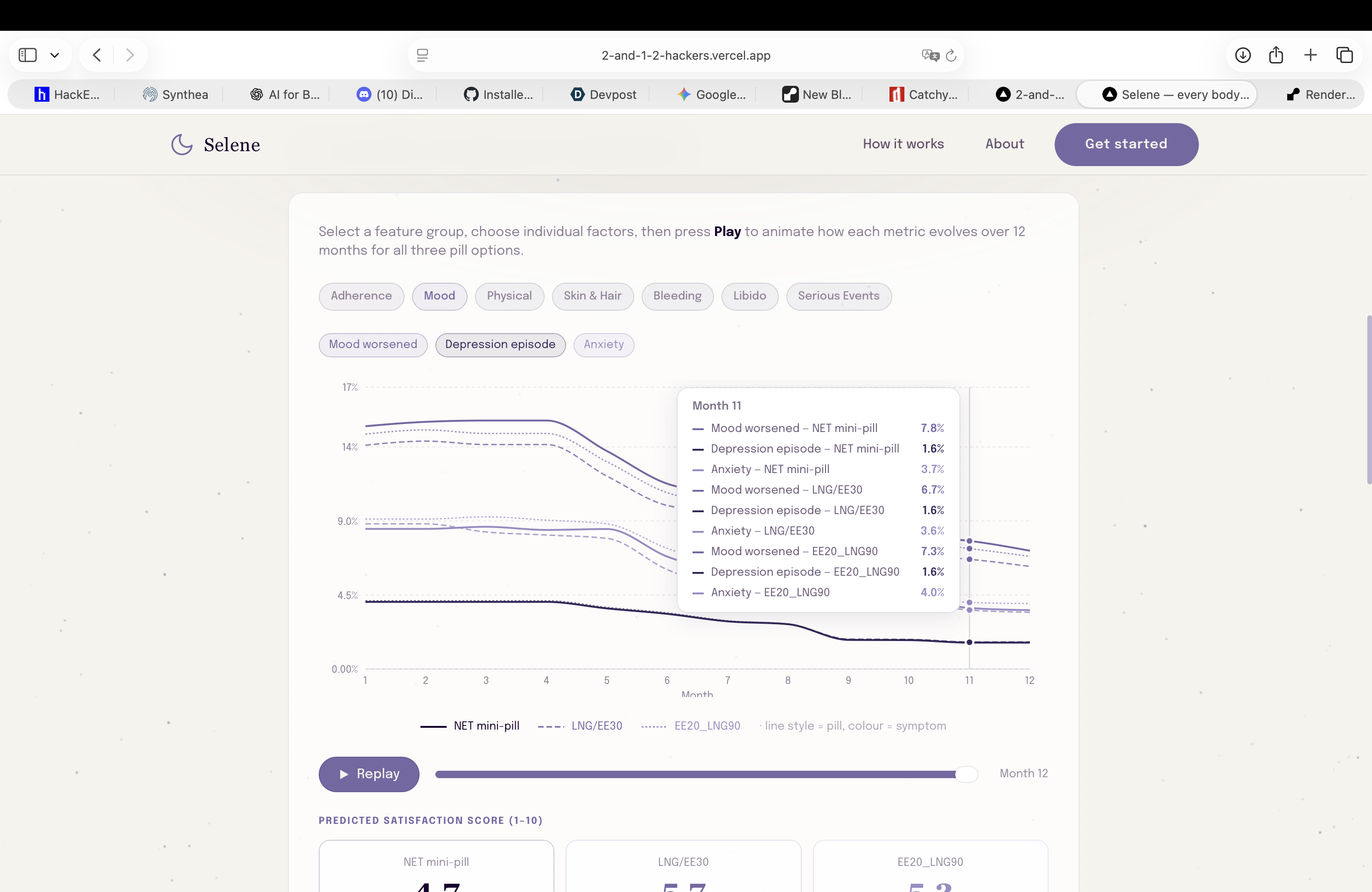
Second step prediction: realistic long time simulations (12 months) of low-risk pills against actual patient data (mood)
-
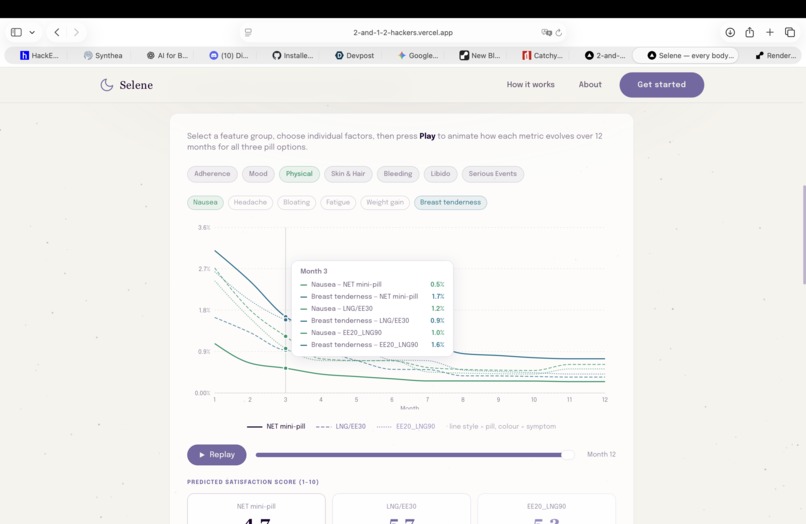
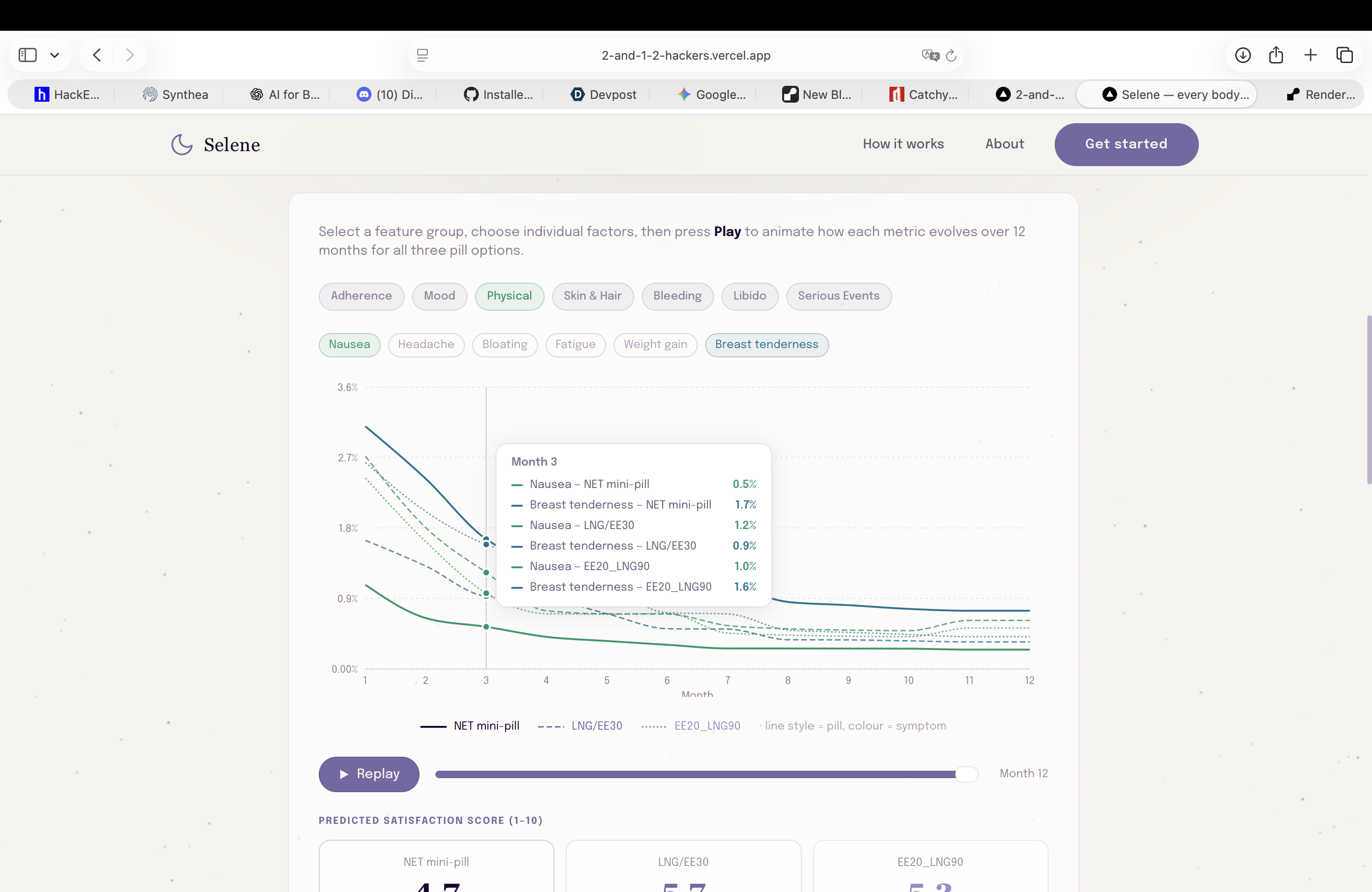
Second step prediction: realistic long time simulations (12 months) of low-risk pills against actual patient data (physical effects)
-
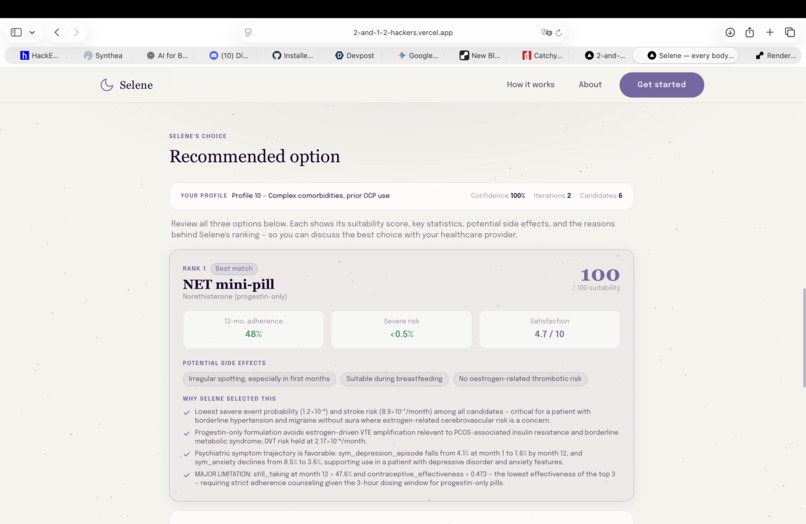
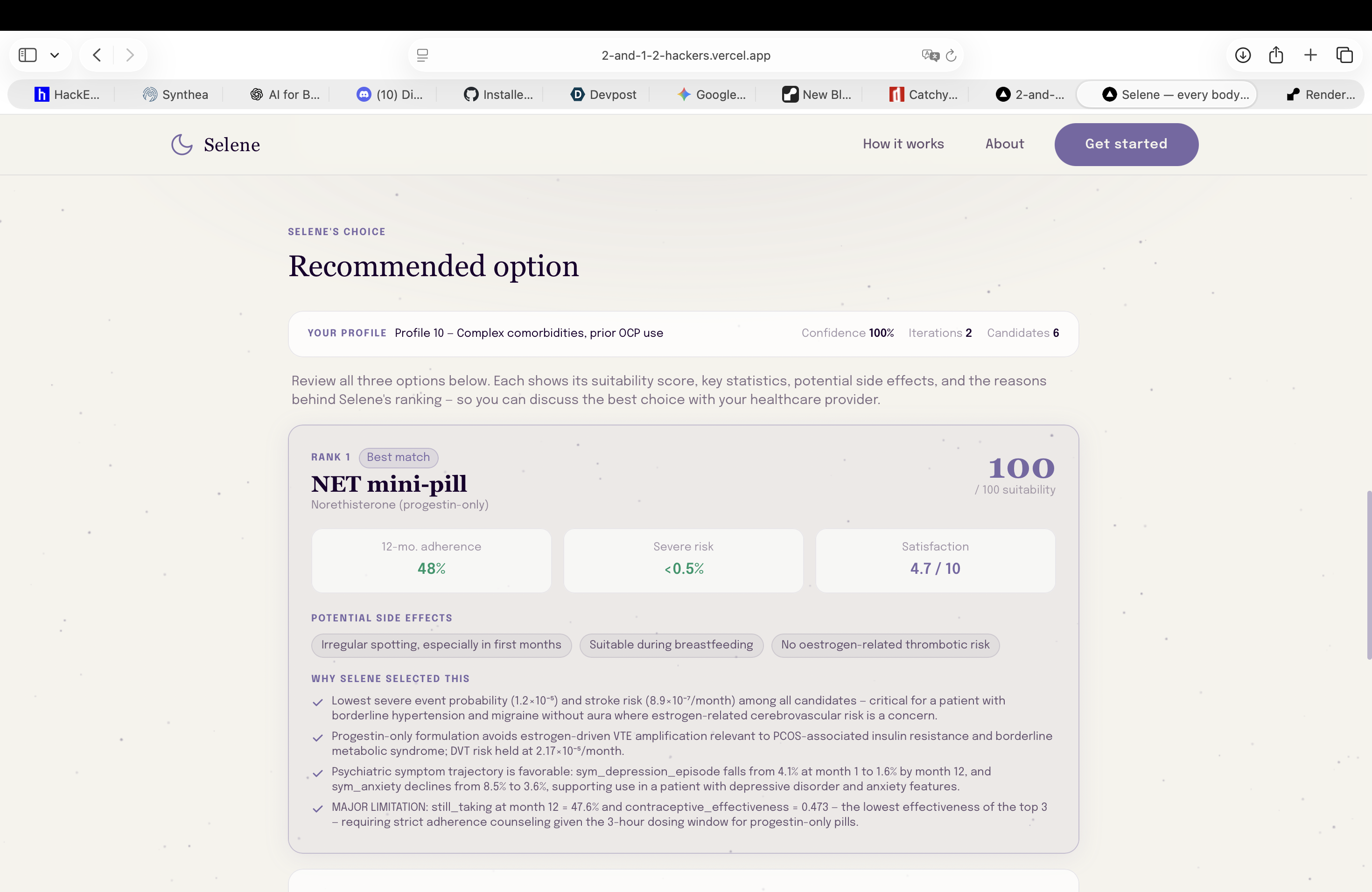
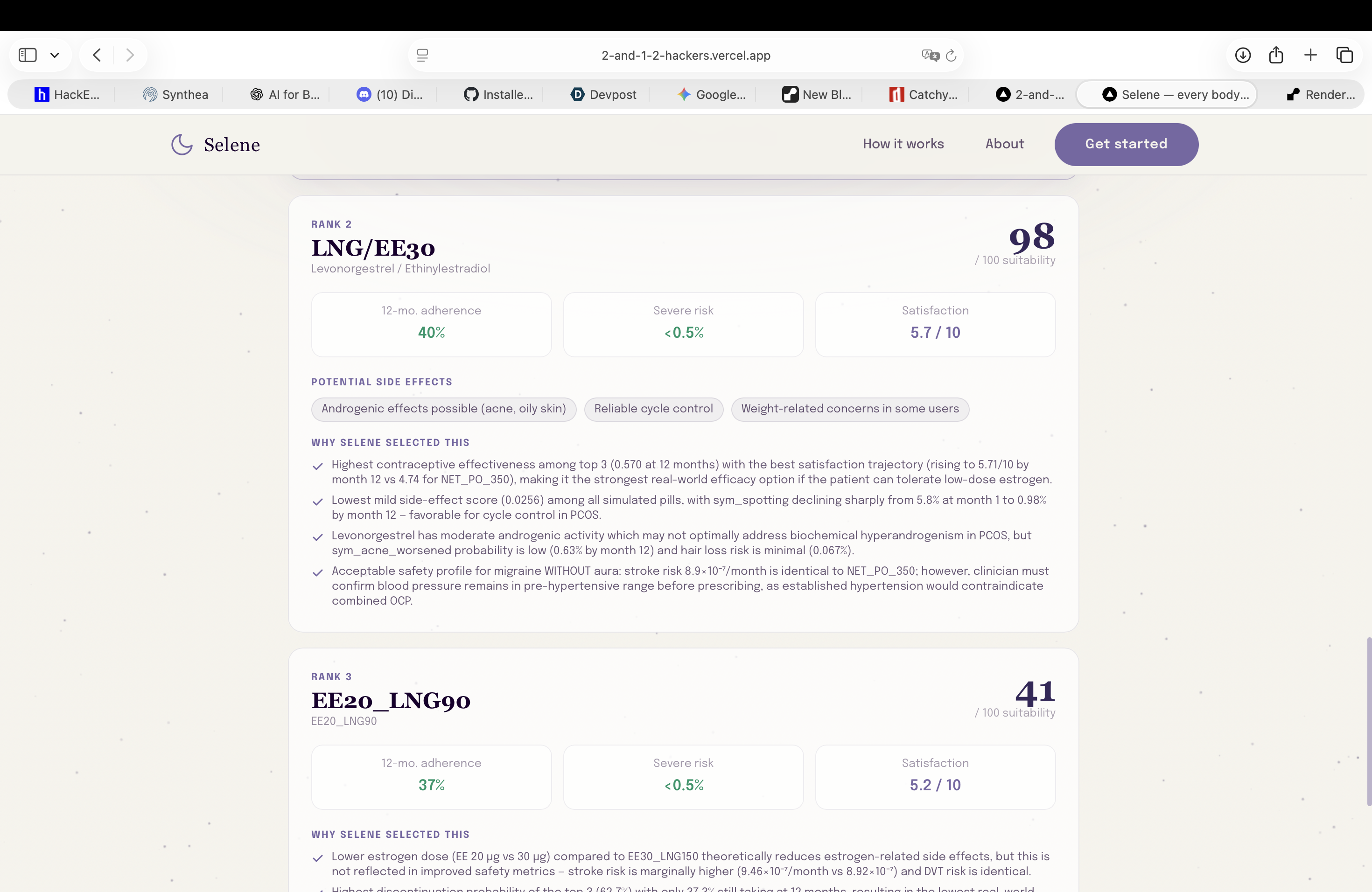
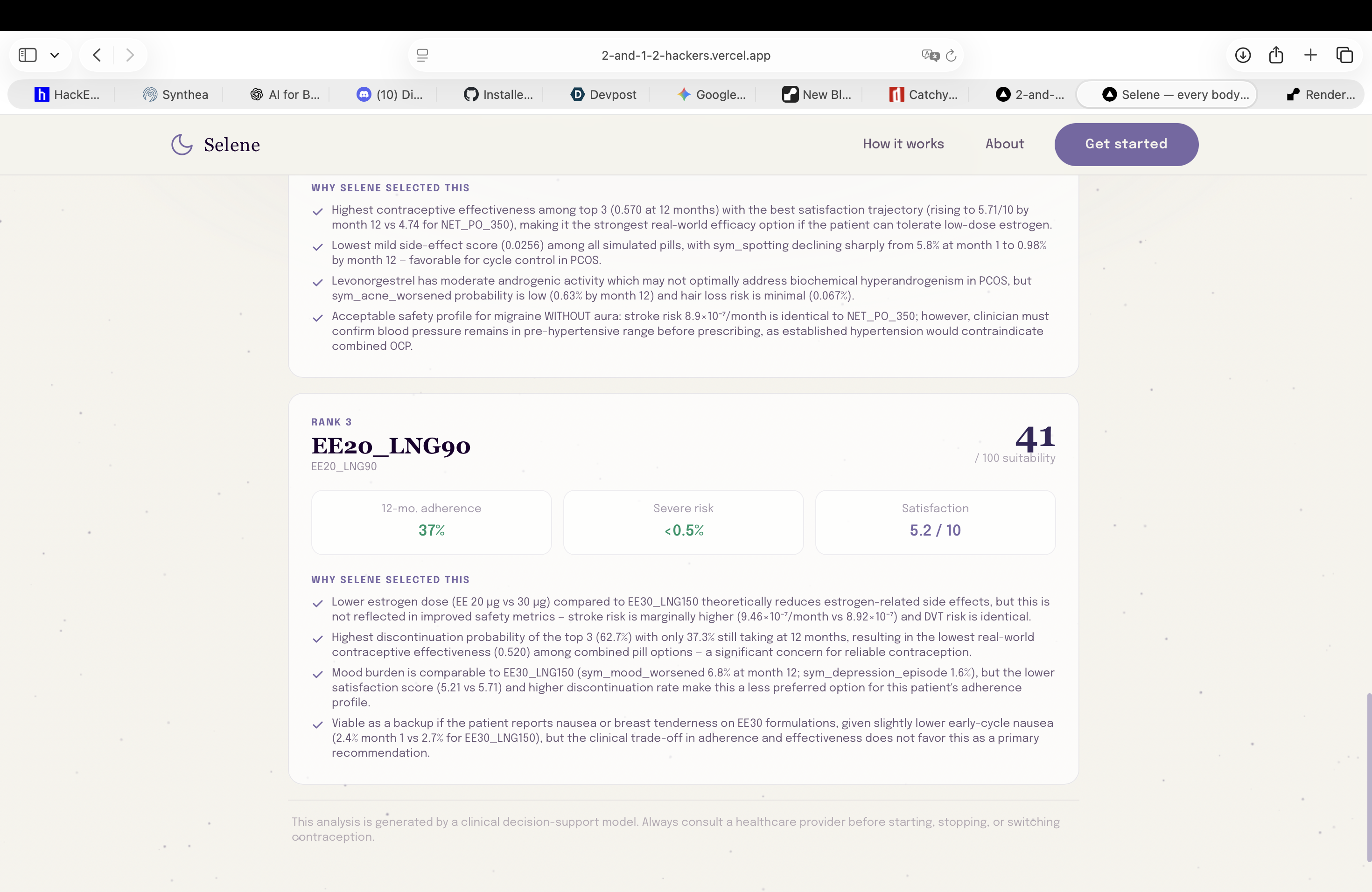
Agent recommendations ranked in order: each pill displays risk factors, treatment adherence likelihood, and predicted satisfaction scores
-
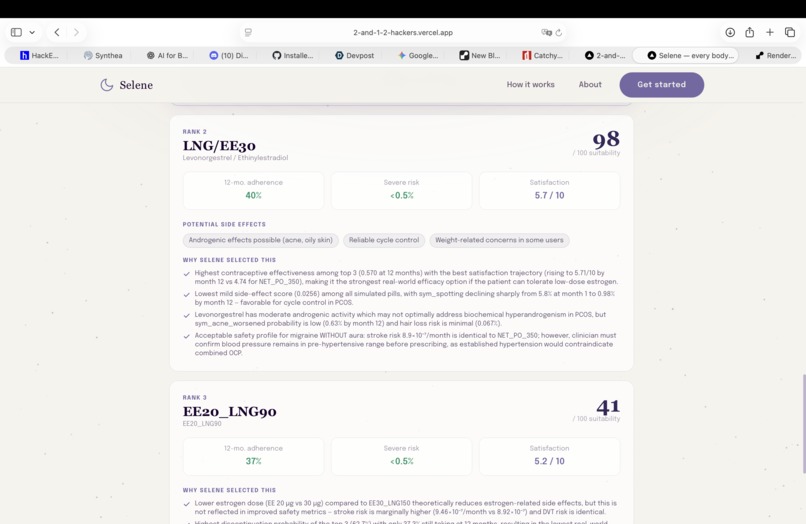
Agent recommendations ranked in order: each pill displays risk factors, treatment adherence likelihood, and predicted satisfaction scores
-
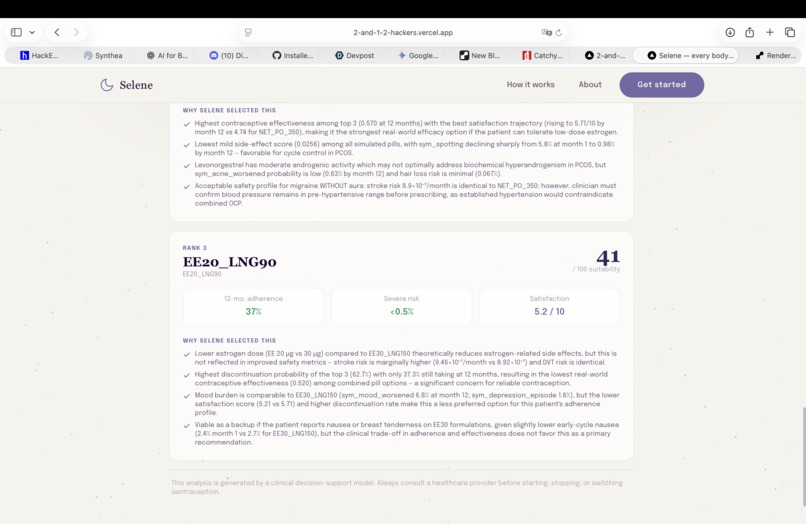
Agent recommendations ranked in order: each pill displays risk factors, treatment adherence likelihood, and predicted satisfaction scores
Inspiration
Contraception is one of the most personal healthcare decisions a woman will ever make, and most of the time it's handled in a 10-minute GP appointment that ends with a generic recommendation and the words "try it for three months and see how you feel."
That three-month trial-and-error period is not a medical inevitability. It is a data problem dressed up as clinical practice. The information needed to make a better first recommendation already exists. It just isn't synthesised at the point of prescribing.
We built Selene because we felt this personally. The side-effect lottery that millions of women quietly accept, mood shifts, blood clot risk, acne, cramps that may or may not improve, is not unsolvable. It is the result of under-investment in women's health technology. Every day on the wrong pill is a day it affects your body, your mood, your work, your relationships. We wanted to build something that finally takes that seriously.
What it does
Selene takes a patient's full clinical profile and returns a ranked, personalised oral contraceptive recommendation, not a generic one.
A LangGraph agentic loop powered by Claude (claude-sonnet-4-5) reasons over the patient's conditions, vitals, and history. Before Claude sees any candidates, a deterministic safety gate filters all WHO MEC Category 3/4 contraindications using pure boolean rules. Claude then selects which pills to simulate, adjusts a utility weight vector, and decides when convergence is reached:
$$U = \alpha \cdot \text{efficacy} - \beta \cdot \text{risk} + \gamma \cdot \text{symptom_relief} + \delta \cdot \text{tolerability}$$
Two ML models, deployed as REST APIs on Red Hat OpenShift, power the loop: a **GMM that profiles the patient into one of 12 clinical archetypes, and a HistGradientBoosting simulator that predicts a full 12-month symptom trajectory for each candidate pill. The loop runs, refining weights and re-simulating, until the best option converges.
How we built it
| Layer | Technology |
|---|---|
| Agent | Claude (claude-sonnet-4-5), LangGraph, LangChain |
| Cloud | Red Hat OpenShift: both ML models deployed as REST APIs |
| ML | GaussianMixture (k=12, BIC-selected), HistGradientBoosting + MultiOutputClassifier |
| Backend / Frontend | FastAPI, Next.js, TypeScript |
| Safety Gate | Pure Python: 7 WHO MEC Cat 3/4 rules, zero LLM involvement |
| Data | Synthea (custom EHR modules), FDA OpenFDA drug labels, FDA FAERS adverse events, Drugs.com reviews |
We generated 4,117 synthetic patients with Synthea, extended them with FDA FAERS adverse event rates and Drugs.com tolerability signals, then trained the simulator on 444,636 rows (4,117 patients × 9 pills × 12 months). Both models are served on OpenShift and called by the agent as external HTTP tools: clean lifecycle separation, concurrent simulator calls via asyncio.gather .
Challenges we ran into
Making safety architectural, not prompted. Any safety guarantee that relies on the LLM behaving correctly is not a guarantee. The solution was structural: the exclusion logic runs before agent state is populated, making it unreachable from any prompt path.
No real training data exists. Labelled prescription outcome data for OCPs doesn't exist at usable scale. We built the entire training set from scratch, Synthea custom modules for PCOS, endometriosis, thrombophilia, and migraine with aura, grounded with real adverse event and review data.
Calibrating the GMM to achieve 96.5% safety recall required a two-stage exclusion design: patient-level hard rules first, then population-level cluster exclusions to catch elevated risk in subgroups where individual binary flags are absent.
Accomplishments that we're proud of
- Safety recall of 96.5% on the GMM with mean assignment confidence of 99.9%, no contraindicated pill ever reaches the agent
- Simulator AUROC of 0.992 on PCOS improvement, 0.987 on cramp relief, clinically meaningful signal from synthetic data
- A hard architectural guarantee that the LLM cannot influence a medical exclusion decision, even under adversarial prompting
- Native NaN handling covering 64% missing PHQ-9 and 92% missing testosterone, no imputation pipeline, no data leakage
What we learned
Safety in AI is an architectural property, not a prompt property.
We also learned that women's health technology is dramatically under-resourced relative to the scale of the problem. 150 million women use oral contraceptives globally. The prescribing process is largely unchanged from decades ago. Building Selene made that gap impossible to ignore, and convinced us there is a real product here.
What's next for Selene
- Expand to the full formulary (patches, rings, IUDs) beyond the current 9 oral formulations
- Regulatory pathway scoping for use as a clinical decision support tool (not a prescribing device)
- B2B rollout via gynaecology clinics and telehealth platforms
Built With
- claude
- faers
- fastapi
- fda-faers-adverse-events
- fda-openfda-drug-labels
- machine-learning
- next.js
- openfda
- python
- red-hat
- synthea
- typescript




Log in or sign up for Devpost to join the conversation.