-
-
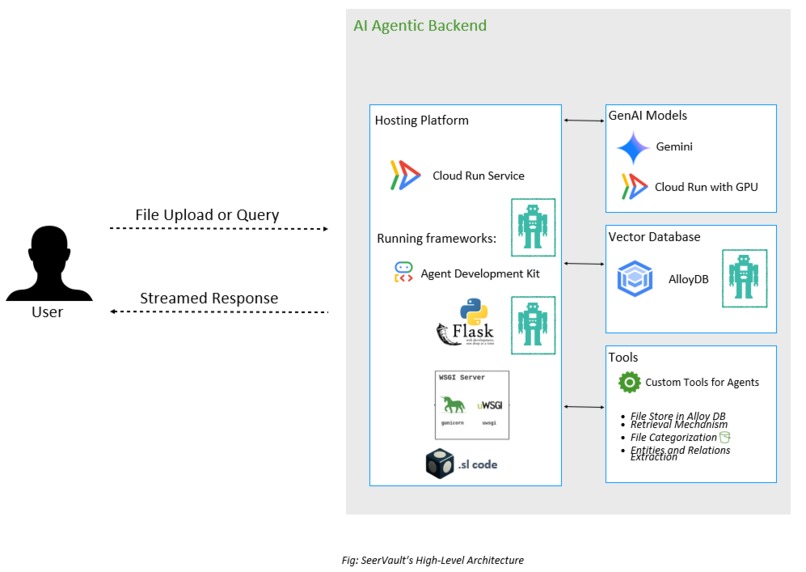
Architecture
Inspiration
Cloud storage in 2025 still behaves like file cabinets from 1995. Users must remember filenames, folder hierarchies, and where things were saved. Knowledge workers constantly download, search, filter, rename, and re-upload because storage is passive.
At the same time, multi-agent AI tooling is exploding, but orchestrating those agents requires hundreds of lines of boilerplate, custom schedulers, and brittle message-passing code. We asked a simple question:
!! Q> Why can't we talk to our data, and have intelligent agents reason over it?
That question ultimately inspired both SeerVault and the domain-specific language behind it: .sl.
What it does
SeerVault is a semantic-aware, conversational cloud storage system. You can ask:
- “Show me photos from 2014 in Paris with my family.”
- “Find my tax-filing documents from 2018.”
- “Combine all regional sales spreadsheets into a dashboard.”
Under the hood:
- Files are stored durably in Google Cloud Storage.
- Meaning is extracted (text, entities, timestamps, relationships).
- Multi-modal vector embeddings are generated.
- Agents reason over this semantic substrate.
- Results are retrieved by meaning, not filenames. It turns cloud storage into an intelligent knowledge interface.
How we built it
SeerVault is composed of three core layers:
Semantic extraction pipelines
Parse PDFs, spreadsheets, images, text
Generate entities, visual embeddings, structured metadata
Multi-agent orchestration
Powered by Google’s ADK
Coordinated using our DSL: .sl
Declarative scheduling, concurrency, message passing
High-performance storage
Binary objects in Google Cloud Storage
Semantic vectors in AlloyDB
Elastic Cloud index for cross-modal retrieval
Everything runs serverless on Cloud Run, scaling ingestion, retrieval, and agent reasoning under load.
Challenges we ran into
- Low-latency vector retrieval across heterogeneous files
- Concurrent multi-agent orchestration
- Asynchronous embedding pipelines with partial retries
- Serverless scaling strategies on Cloud Run
- Consistency between relational and semantic layers
Accomplishments that we're proud of
- Designed and implemented .sl, a production-grade DSL that compiles into ADK agent configurations.
- Reduced 300+ lines of agent boilerplate to ~50 declarative lines.
- Built an end-to-end semantic storage experience with conversational retrieval.
- Demonstrated real-time vector ingestion into AlloyDB.
- Eliminated manual download-edit-upload workflows.
- Built a cloud system where intent drives data interaction.
What we learned
Throughout development, we discovered that treating agent communication as first-class syntax dramatically improves clarity, maintainability, and extensibility in multi-agent systems. Embeddings alone proved insufficient without structured metadata to anchor semantic meaning and provide explainability. We also found that serverless multi-agent workloads demand careful scheduling, concurrency limits, and backpressure strategies to avoid runaway costs or cascading retries. Most importantly, semantic search only becomes reliable when backed by durable storage semantics, ephemeral pipelines lead to inconsistent results and user mistrust. Finally, the developer experience for AI agents is still in its infancy; this validated our belief that domain-specific languages can meaningfully advance tooling and accelerate real-world adoption.
What's next for SeerVault
Moving forward, we’re exploring hierarchical multi-vector representations to improve cross-modal disambiguation and reduce false positives in complex queries. We’re also prototyping lightweight, on-device embedding pipelines to enhance privacy and reduce cloud bandwidth requirements, along with federated semantic search across siloed data stores. On the security side, semantic-aware access control and policy-level reasoning will help mitigate latent leakage risks between embeddings and metadata. Temporal context models will enable dynamic re-ranking based on evolving intent, and autonomous agent workflows will support advanced tasks like report generation and KPI aggregation. Long-term, our trajectory is toward a new class of storage systems that fundamentally understand and operationalize your data rather than merely store it.


Log in or sign up for Devpost to join the conversation.