-
-
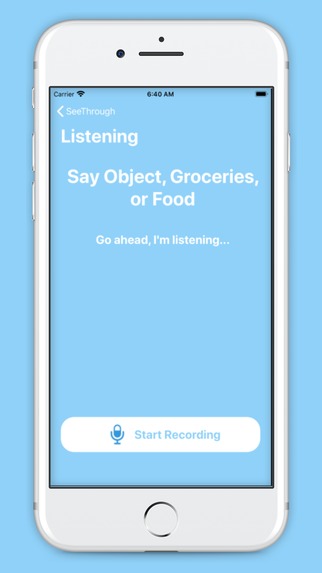
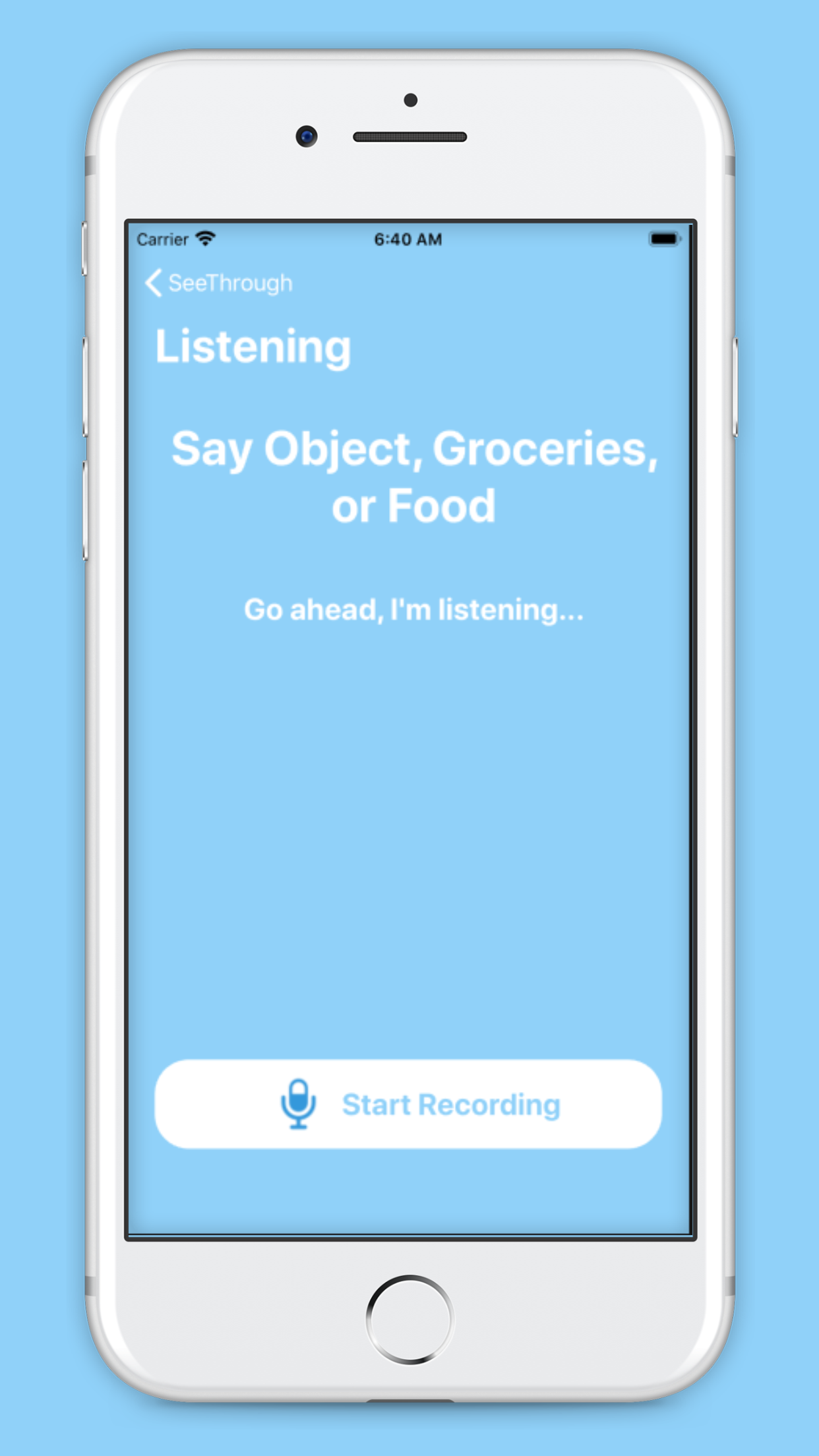
App scene for voice recognition
-
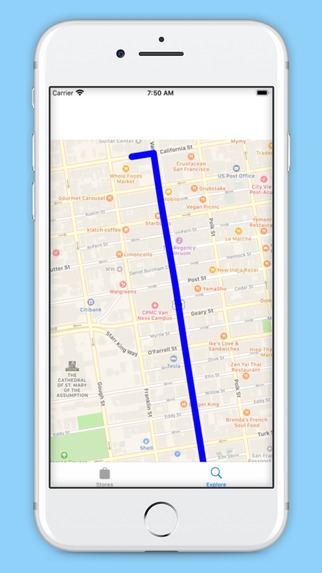
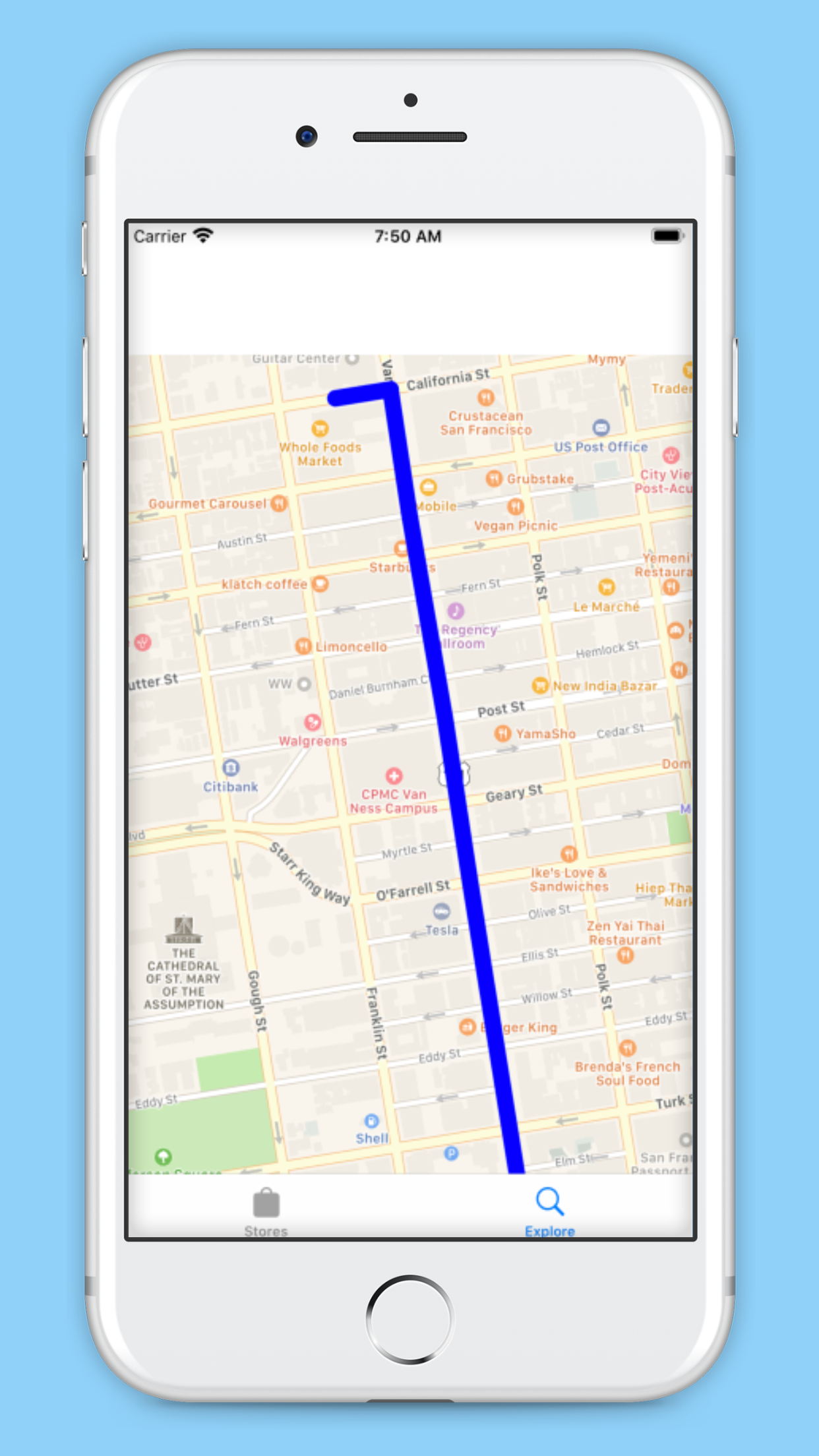
App scene for map display and directions
-
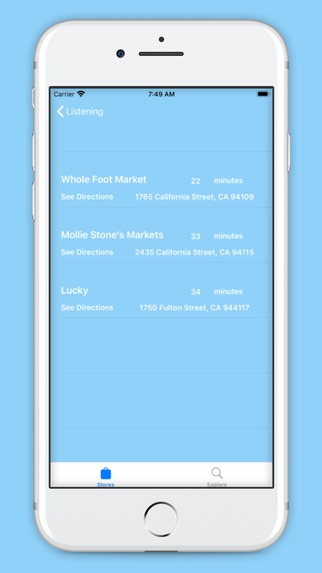
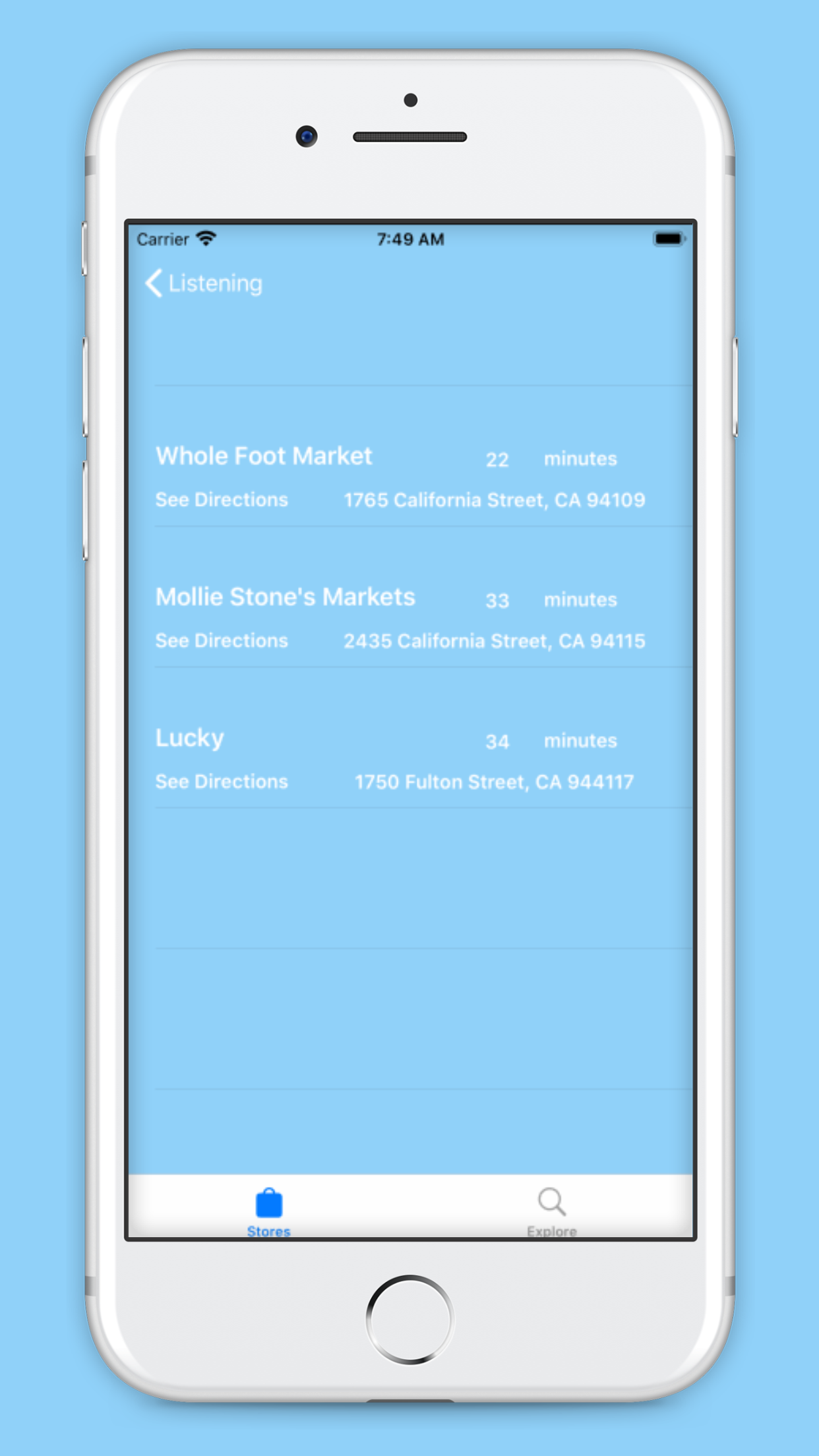
App scene for VisaAPI Grocery Stores Table
-
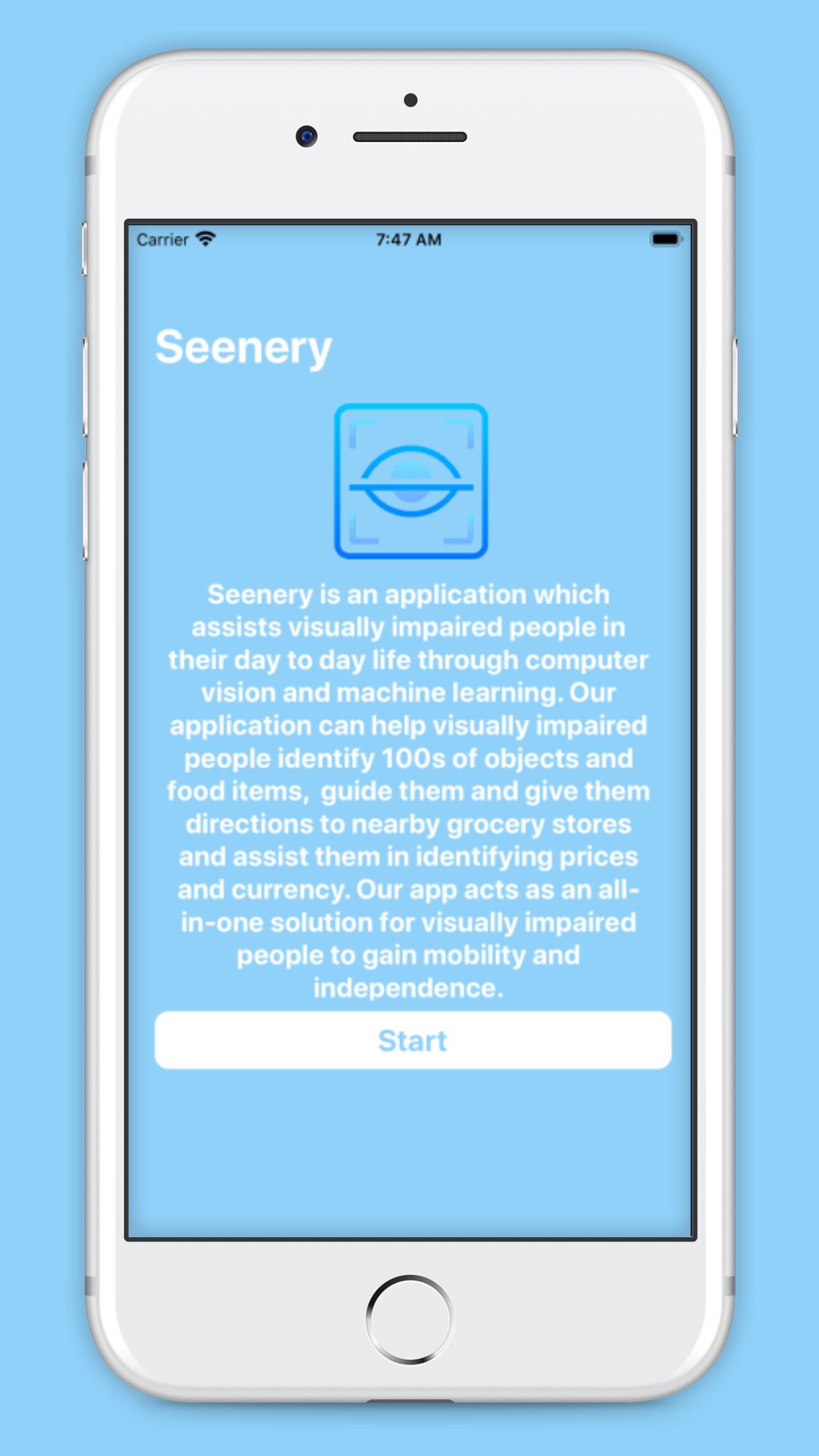
App scene for Introduction
Inspiration
We were inspired by watching videos from the blind community highlighting their struggles doing groceries, including the walk to the grocery store and actually doing the shopping. We wanted to build a geospatial solution which acts as their “eyes” and guides them.
We also wanted to include an object and food recognition software which tells a visually impaired user what objects they are near and what food is near them, so in the case they walk into a store or a restaurant, they can easily gain spatial awareness by scanning the objects near them.
What it does
Seenery has 3 main parts: Spatial Awareness through object/food recognition and Geospatial Awareness through GroceryHelp. The spatial awareness section allows a user to take a picture of an object or a type of food and our machine learning model will predict what that object or food is.
The GroceryHelp component of our app locates nearby grocery stores and gives audio directions to the selected stores. This component also allows user to select which store they go to and provides the approximated walking time and other key reminders within the directions function.
How I built it
The main functionality of our app is based around coreML, a new machine learning framework introduced by Apple. We used multiple machine learning models within our application: For object identification, we used the Resnet50 model provided by Apple and incorporated it into our liveview application to identify objects in real time at an efficient rate. We also used coreML models to identify types of food, allowing a visually impaired person to walk into a bakery or a food market and identify foods they want to buy or eat!
We utilized voice recognition to become the commanding force of our app, allowing a user to simply speak and navigate the user interface. We also used the AVaudioengine to give audible directions to the user to make our application more accessible and easier to use. We used Apple’s MapKIt to generate directions to nearby grocery stores, and then again used the AVaudioengine to make those directions audible and easy to understand.
When needed, we trained our machine learning models using X-Code’s create ML functionality. Most of our images were either found in data sets or simply through repeated scavenging on Google.
We also used Visas Merchant Search API to locate nearby Merchants and Grocery Stores, and then used Apple’s MapKit to find directions to the located Merchants as well as generate a map.
Challenges I ran into
We faced a lot of challenges mainly due to gaps in our understanding: We tried to overlay coreML models on top of each other which led to frustration and finally concluding that it wasn’t worth our time. Working with the map and making the directions audible also posed struggles due to our lack of understanding of speech to text and text to speech conversion within Swift as well as using Maps and Directions. More so, getting the TLS certificates for our API’s was extremely difficult and required a lot of troubleshooting with Visa and Firebase.
Accomplishments that I'm proud of
I'm proud of our use of machine learning models, especially building and training our own models to identify certain objects which proved to be useful within our application.
I'm proud of our User Interface, especially our use of voice recognition for navigation as we had little to no knowledge of the audio tool kits and we learnt a lot of new functionality by building the audio software.
I'm also proud of our teamwork and dedication. Even after many tough and stressful errors within our code, we rose to the task and overcame the issues as a team, which made me extremely proud and gave me satisfaction.
What I learned
We learnt a lot about speech to text conversion, training coreML models, using coreML models for image processing and recognition, building maps in swift and using Firebase and other API’s within IOS development which will all be useful in the future.
What's next for Seenery
In the future, we hope to expand our outreach to more stores and have more images and datasets to perfect our machine learning models. It also might be helpful to make 100% of our application voice based rather than sudo-voice based, as this previously did not fit into our 24 hour time constraint.
Disclaimer:
Buttons for Object Recognition and Food Recognition Scenes are the Image themselves: Images serve as buttons.
For github, install the podfile and use it in your terminal. Cocoapods install is needed because of 100mb file limit on github.
For object detection ONLY, our model was imported from https://developer.apple.com/machine-learning/models/. We used the Resnet50 model for object detection.











Log in or sign up for Devpost to join the conversation.