-
-
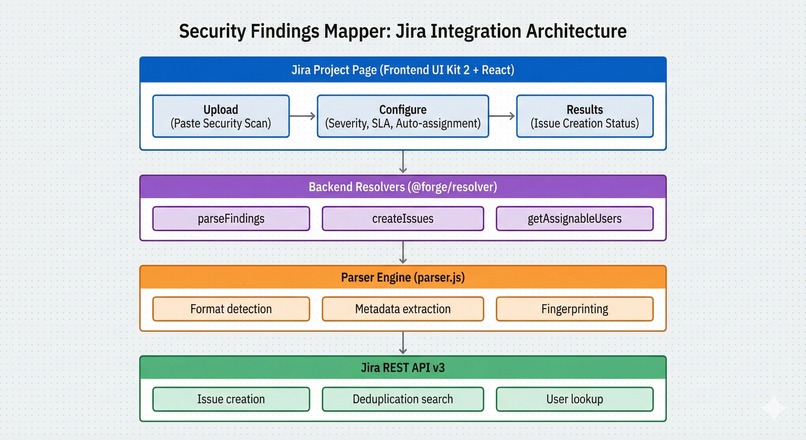
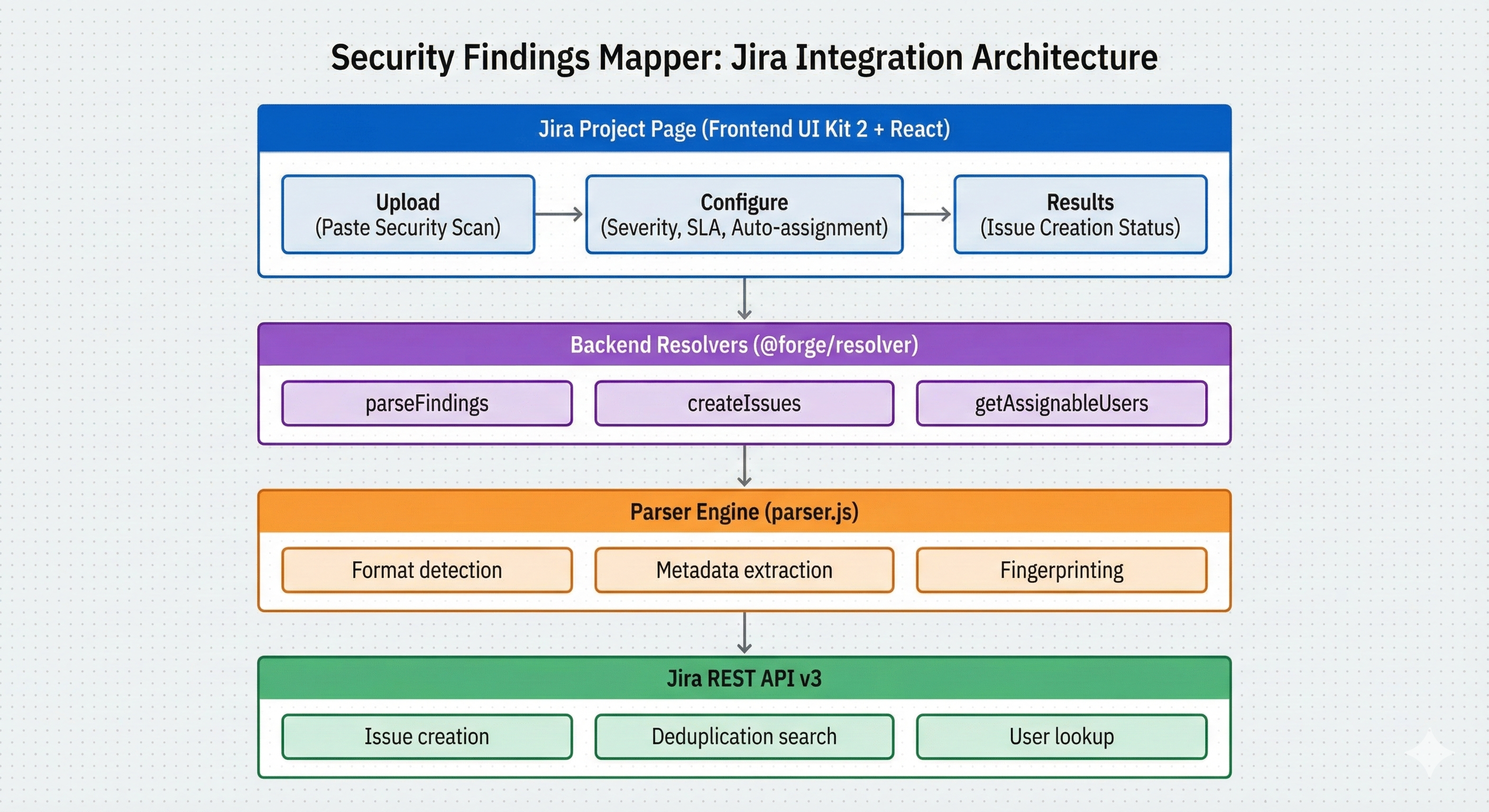
Security Findings mapper architecture
-

Security Findings mapper logo
-

Security Findings mapper banner


Inspiration
As a security engineer working with large development and security teams over the years, I've witnessed the same frustrating pattern repeat countless times across organizations of all sizes. Security teams conduct dozens of audits every year, each producing 50–200+ vulnerability findings in formats like SARIF, Snyk JSON, Semgrep, Trivy, or plain-text reports. The painful reality?
Every single finding gets manually copy-pasted into Jira.* I've personally spent — and watched dozens of colleagues spend — 6–8 hours per audit just transcribing vulnerabilities. Copying titles, severity levels, CWE/CVE identifiers, file locations, and remediation steps from scan reports into Jira tickets, one by one. After years of watching talented security professionals waste their expertise on data entry, I asked myself: What if you could paste a security scan and have Jira issues created in 30 seconds? That's why I built Security Findings Mapper — to give back hours to security engineers and help development teams fix vulnerabilities faster.
What it does
Security Findings Mapper transforms security scans into Jira issues in three steps: Upload (paste SARIF, Snyk, Semgrep, Trivy, CSV, or plain text), Configure (filter, assign by severity, set SLA), Create (bulk-generate deduplicated issues with severity, CVSS, CWE/CVE, location, evidence, remediation). Saves 6–8 hours per audit.
How we built it
We have build the custom multi-format parser (7+ formats) with regex-based metadata extraction → Node.js 22.x backend resolvers → Jira REST API integration → UI Kit 2 React frontend on Forge. Parser auto-detects format, normalizes to common schema (severity, CVSS, CWE/CVE, location, evidence, remediation). SHA-256 fingerprinting on (ruleId + location + scanner + severity) prevents duplicates across re-imports.
Challenges we ran into
Format variability: Semgrep uses dot-separated namespaces (javascript.express.security...), Snyk returns CWE as arrays, plain text has no structure — solved with format-specific parsers and intelligent title formatting. UI Kit constraints: No raw CSS on Inline — learned to use xcss tokens, shouldWrap, rowSpace (more maintainable anyway). Forge caching: Production deploys didn't reflect immediately — added visible build marker to confirm freshness.
Accomplishments that we're proud of
Deduplication at scale: Fingerprint-based matching prevents duplicate tickets even across re-imports and different scanners — solves a problem every large org faces. 7+ format support: Handles SARIF, Snyk, Semgrep, Trivy, Burp XML, CSV, plain text seamlessly with intelligent title extraction. Severity-based auto-assignment: Critical → senior engineers, low → junior team members — reflects real workflows. Production-ready: Deployed and battle-tested with real scan outputs from multiple tools.
What we learned
Forge constraints force better code (not limitations). Jira's API is more nuanced than expected: createmeta reveals available fields, duedate varies by issue type, JQL escaping is tricky. Most important: Automation only works if intuitive. Security engineers want paste-and-go, not 20 config options. Developers care about context (evidence, remediation, location) to fix issues fast. Every team needs different SLAs. Building tools requires understanding workflows intimately.
What's next for Security Findings Mapper
Immediate: CI/CD integration (GitHub Actions, GitLab CI) for auto-import on every build. Dashboard widget showing security debt trends. Slack/Teams alerts for CRITICAL findings.
Medium-term: CVSS trend tracking. AI-powered remediation suggestions (LLM-based fix snippets per CWE). Audit trail (PDF/JSON attachments).
Long-term vision: Fully automated security findings — from scan execution to developer notification to fix verification. Security teams spend zero time on data entry, 100% time on high-value analysis.
Built With
- atlassian
- forge
- javascript
- jira
- node.js
- restapi
- sha256


Log in or sign up for Devpost to join the conversation.