-
-
Security Auto-fix Flow

Security Auto-Fix Flow
Inspiration
Every engineering team has the same problem — security scanners generate dozens of findings per push, but nobody has time to fix them. The gap between detection and remediation is where breaches happen. CVEs pile up in backlog, developers get overwhelmed with vulnerability lists they don't have context to prioritize, and critical issues like SQL injection, command injection, and insecure deserialization sit unpatched for weeks.
I wanted to close that gap completely. Not just detect vulnerabilities — but fix them, validate them, review them autonomously, and make the system smarter with every run.
What it does
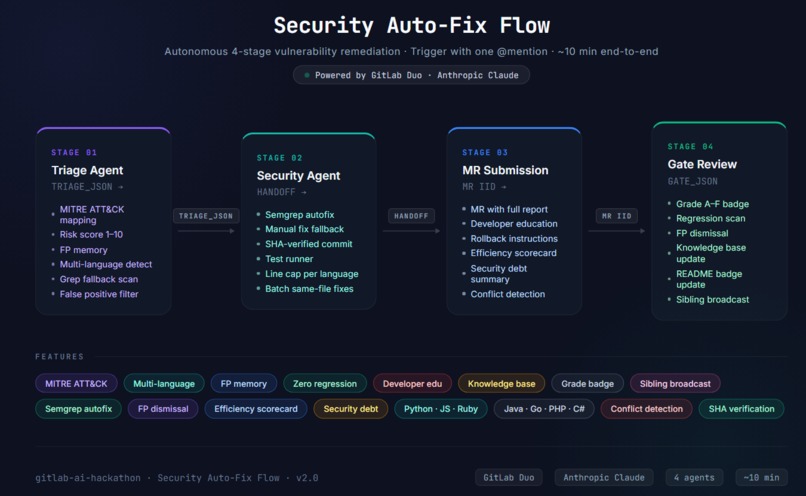
Security Auto-Fix Flow is a fully autonomous 4-stage AI pipeline built on GitLab Duo Workflows:
Triage Agent — Scans the repo using GitLab SAST with a grep fallback, scores every finding by exploitability using a risk model, maps each to MITRE ATT&CK, and classifies as
AUTO_FIXorHUMAN_REVIEW. Reads a living Security Knowledge Base from previous runs to annotate repeat patterns and avoid false positive blind spots.Security Agent — Fixes the top 10 findings by risk score with minimal, surgical code changes. Commits to a dedicated branch, verifies the vulnerable pattern is actually gone by re-reading the committed file, runs scoped CI tests, and hands off a cryptographically verified HANDOFF JSON.
MR Submission Agent — Creates a Merge Request with a full audit trail: findings table with confidence ratings, developer education per fix (why it was vulnerable, how it was fixed, what to never write again), rollback plan, coverage report, and security debt trend analysis.
Gate Review Agent — Audits the diff independently using GitLab Duo Code Review, verifies every finding is addressed, scans for regressions — new vulnerabilities introduced by the fixes — posts a Bottom Line verdict with grade A–F, updates the Security Knowledge Base, and refreshes the security grade badge in README.
The project also ships a standalone Duo Chat agent for interactive, on-demand security fixes directly from the GitLab Duo sidebar — same detection and fix logic, no pipeline required.
Works across Python and JavaScript with detection support for Java, Go, Ruby, PHP, and C#.
How we built it
The flow is built entirely on the GitLab Duo Agent Platform using AgentComponent stages with verified structured handoffs between every stage:
TRIAGE_JSON → HANDOFF → GATE_JSON
Each contract is minified, machine-verifiable JSON that the next stage parses — no free-form text passing between agents. This prevents hallucination from propagating across stages.
Key technical decisions:
- Language agnostic — cross-language grep pattern covering 7 languages, per-language severity table, language-detected test runners and manifest files
- False positive memory — gate writes
SECURITY_KNOWLEDGE.mdafter every run; triage reads it on the next run using exact path + line + pattern three-way matching, so the flow gets smarter without creating blind spots - SHA verification —
get_commitprimary path +ls-remotefallback prevents fabricated commit SHAs from reaching the MR - Pattern-still-present check — after committing, the agent reads the file back and confirms the vulnerable pattern is actually gone before marking as fixed
- findings_fingerprint and GATE_OVERRIDE — triage emits a canonical
findings_fingerprintmap of every finding's severity, path, line, and fix decision. The gate agent receives this directly and must explicitly flag any disagreement asGATE_OVERRIDEwith a reason. This means the gate verifies against ground truth, not against the fixer's own claims about what it fixed. - Per-language partial fix logic — instead of a flat line cap that silently escalates oversized fixes to HUMAN_REVIEW, the agent attempts a function-scoped partial fix first. If the fix exceeds the language-specific cap (25 lines for Python/Go/Ruby/PHP, 30 for JS/TS, 40 for Java/C#) but can be scoped to the vulnerable function, it commits the partial fix with confidence=MEDIUM and flags remaining scope separately. Only genuinely impossible cases escalate to HUMAN_REVIEW.
- Conflict detection —
get_merge_request_conflictsat both Stage 3 and the gate prevents wasted reviews on unmergeable branches - Authoritative triage —
auto_fix_decisionfrom Stage 1 is treated as ground truth by Stage 2, preventing the security agent from second-guessing triage decisions - Scanner gap handling — in environments without SAST pipelines configured,
list_vulnerabilitiesreturns empty and the flow falls back to grep. The grep pattern covers the same vulnerability categories as Bandit/Semgrep but without CVE-backed confidence scores, so severity classification uses a deterministic lookup table keyed by pattern category rather than scanner metadata. This makes fallback behavior predictable and auditable.
Challenges we ran into
Prompt engineering at scale — 4 system prompts that need to work together without contradicting each other. Getting triage classification right took dozens of iterations — risk score computation, test directory content checks, and HUMAN_REVIEW override ordering all interact in subtle ways that only surface in live runs.
SHA hallucination — LLMs will confidently fabricate commit SHAs that look real but aren't. Solved by requiring verbatim extraction from tool output with format validation (exactly 40 lowercase hex characters, no patterned sequences) before HANDOFF is emitted.
False positive contamination — the agent kept misreading FIXED entries in the knowledge base as false positive dismissals. Solved by enforcing header-only parsing (## {date} | FALSE POSITIVE | {path}:{line}) and explicitly forbidding inference from repeated FIXED entries.
Merge conflicts — the gate committing to main for knowledge base updates was advancing main and causing subsequent security branches to diverge. Solved by get_merge_request_conflicts early detection at both Stage 3 and gate.
Size constraints — the GitLab AI Catalog has a flow YAML size limit. Fitting 4 complete agent prompts with all engineering decisions into the limit while preserving every rule required careful compression without losing logic.
Test directory cross-contamination — agent would see @app.route in one file and apply the REAL finding classification to all files in the batch. Solved by explicitly requiring per-file content checks before any classification decision.
Scanner fallback reliability — when GitLab SAST hasn't run on a repo, list_vulnerabilities returns empty and all findings come from grep. Severity must still be deterministic. Solved by a fixed lookup table mapping grep pattern categories to severity and CWE, with no LLM inference permitted — the same pattern always produces the same severity regardless of surrounding context.
Accomplishments that we're proud of
- End-to-end autonomy — trigger with one
@mentioncomment, get a gate-approved, merge-ready MR in ~10 minutes with zero human intervention - Living knowledge base — the flow genuinely gets smarter every run, with structured entries for every fix and false positive that inform future triage
- Multi-language in one flow — same 4-stage pipeline handles Python and JavaScript vulnerabilities in the same run, with language-detected fix patterns and test runners
- Gate as independent verifier — the gate agent receives the original triage output directly, not just the remediation report, so it verifies against ground truth not agent-reported claims. The
findings_fingerprintcontract enforces this at the data level. - Partial fix over silent escalation — when a fix is too large for a single safe commit, the agent makes a provable partial improvement rather than doing nothing. Every run moves the security posture forward.
- Developer education built in — every MR teaches the developer why the code was vulnerable, how the fix prevents exploitation, and what pattern to never write again
- Cross-project broadcasting — one fix in one project creates vulnerability pattern alert issues in sibling projects with deduplication across runs, protecting the whole organisation without flooding issue trackers
What we learned
- Multi-agent systems need contracts, not conversations — structured JSON handoffs are far more reliable than free-form text passing between stages
- Incremental complexity beats speculative complexity — every rule we added had to prove itself in a live run before it stayed. Every time we added rules to handle hypothetical edge cases, we introduced new failure modes. The best fixes were the ones that removed ambiguity, not added instructions.
- LLMs reason past explicit instructions when they build confident narratives — the only reliable fix is tool-verified outputs, not more warnings in the prompt
- The gate being independent of the fixer is the right architecture — it catches what the fixer gets wrong without slowing down the flow
- Order of operations matters in prompts — risk score computation before vs after the test directory check produces completely different results
- Deterministic fallbacks outperform flexible reasoning — the grep severity lookup table produces consistent, auditable results. A more "intelligent" approach that let the model reason about severity from context was less reliable and harder to debug.
What's next for Security Auto-Fix Flow & Agent
- Semgrep re-scan verification — add a post-fix verification step using Semgrep re-scan to confirm the scanner no longer flags the fixed code, not just a pattern grep. This closes the loop between detection and verified remediation.
- Scanner-first triage — when
list_vulnerabilitiesreturns empty, trigger a SAST pipeline run and wait for results before falling back to grep. This ensures scanner-backed confidence scores are used wherever possible. - More language coverage — extend fix patterns to Java, Go, and Ruby with end-to-end tested runs
- Auto-merge on grade A — if gate gives grade A with zero regressions and no CRITICAL unresolved, automatically approve and merge without human review
- PR triggers — extend beyond push-to-main to trigger on merge request creation, catching vulnerabilities before they reach the default branch
- Slack/Teams broadcasting — post gate verdicts and security debt summaries to team channels, not just GitLab issues
- Dependency auto-PR — dedicated dependency upgrade runs on a schedule (weekly) to keep CVE debt from accumulating between pushes
- Knowledge base analytics — track recurring vulnerability patterns across runs and surface them as team-level security insights
Built With
- anthropic
- att&ck
- claude
- gitlab
- gitlabapi
- gitlabci/cd
- gitlabduo
- gitlabworkflows
- grep
- javascript
- mitre
- python
- yaml
Log in or sign up for Devpost to join the conversation.