







Inspiration
Every day, professionals in healthcare, finance, and law paste sensitive documents into AI tools to extract insights. Patient records, bank statements, employment contracts — names, Social Security numbers, account numbers sent in plaintext to third-party APIs. In regulated industries, that's a compliance violation. For everyone else, it's a privacy risk most people don't think about.
Existing workarounds fall short. Enterprise data agreements are expensive. Keyword blocklists miss context-dependent PII. Post-processing redaction is already too late. We wanted to solve this at the source: make it architecturally impossible for PII to reach the LLM.
What it does
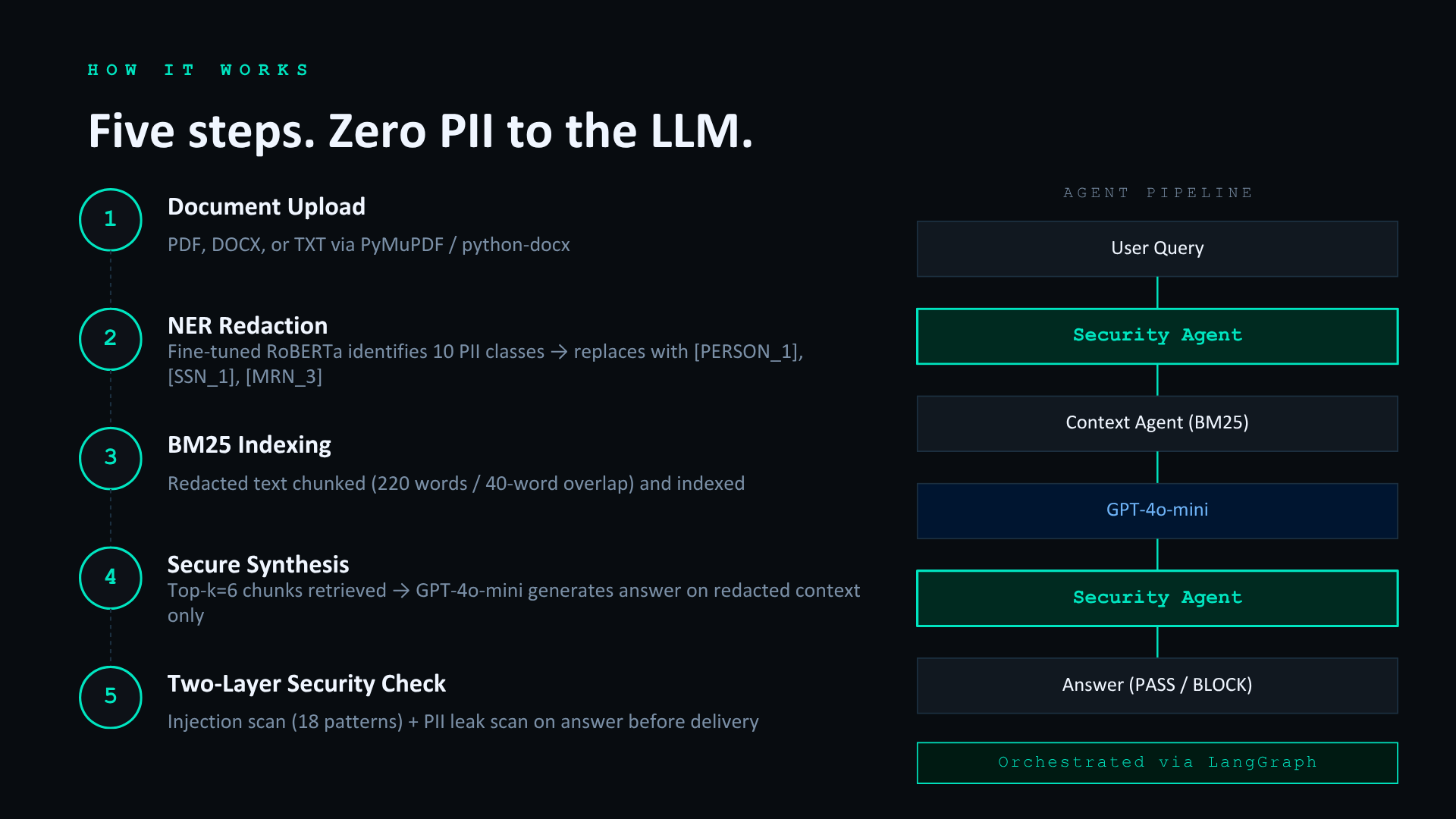
Securify lets you ask AI questions about sensitive documents without exposing any PII to the model. You upload a file, a fine-tuned NER model identifies and replaces ten classes of PII with structured placeholders like [PERSON_1] and [SSN_1], and only the redacted version ever reaches GPT-4o-mini. The mapping between placeholders and real values never leaves the server.
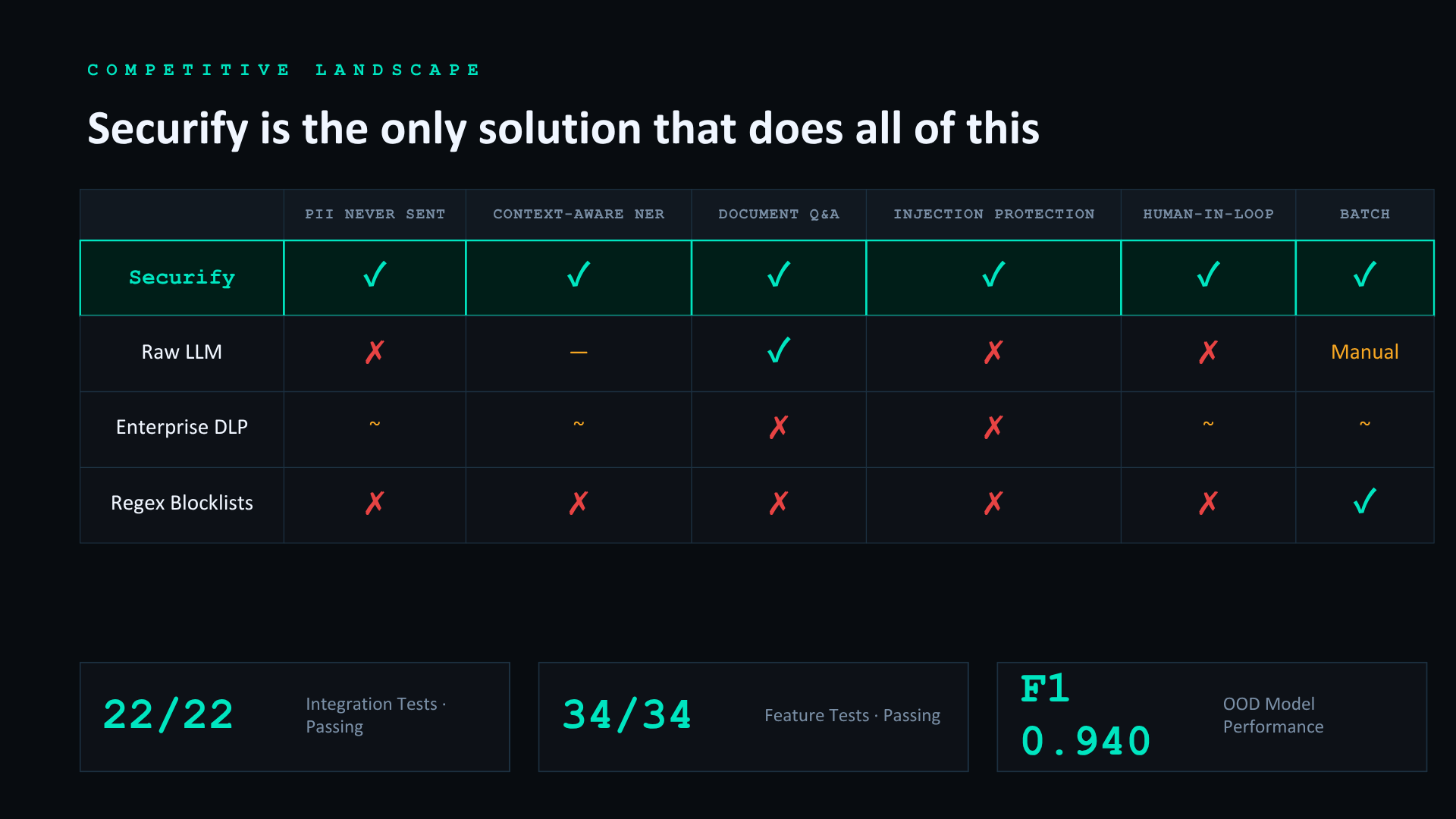
A two-layer security agent blocks prompt injection attempts on the way in and scans answers for PII leaks before delivery. Every query is logged with a PASS or BLOCKED verdict. Additional features include streaming responses, a side-by-side redacted document view, human-in-the-loop entity flagging, PDF export, and batch processing for up to 500 documents at once.
How we built it
We fine-tuned RoBERTa-base for named entity recognition using 160,000 training examples: 80,000 from the ai4privacy dataset and 80,000 synthetic documents generated with Faker. We collapsed ai4privacy's 63 label classes into a 10-class schema relevant to healthcare and finance. The model hit OOD micro F1 of 0.940 on a 5,000-example held-out test set.
The backend is FastAPI with a LangGraph agent pipeline. For retrieval we use BM25 instead of dense embeddings because dense models degrade on redacted text — placeholder tokens like [PERSON_1] all look the same to an embedding model. BM25 handles them correctly. Streaming runs over SSE. Batch processing uses Celery and Redis.
The frontend is React 18, TypeScript, Vite, Tailwind, and Zustand, deployed via multi-stage Docker on Railway. The model is hosted on HuggingFace Hub.
Challenges we ran into
Retrieval on redacted text was harder than expected. Dense embeddings fail because every [PERSON_N] token produces an identical vector, so the retriever can't distinguish between different entities. Switching to BM25 fixed this entirely.
Training data label mapping took significant effort. The ai4privacy dataset has 63 overlapping label types and we needed to collapse them into 10 without losing coverage on critical classes like DIAGNOSIS and MRN, which aren't well-represented in general NLP datasets.
Deployment had a late issue: the 503MB model checkpoint was missing its tokenizer artifact after being recovered from a dropped git stash. We resolved it with a fallback loading chain that degrades gracefully rather than crashing the server.
Accomplishments that we're proud of
- OOD micro F1 of 0.940, with perfect recall on DIAGNOSIS and MRN
- 22/22 integration tests passing with live GPT-4o-mini responses across three document types
- 34/34 feature tests passing covering streaming, flagging, batch, and redaction completeness
- Zero PII leaks across the entire test suite
- A full-stack product live in production with streaming, batch processing, human-in-the-loop flagging, and a complete audit trail
What we learned
The hardest part of a privacy system isn't the model — it's the edge cases. Street addresses, ZIP codes, and formatted dates don't behave like named entities. A fine-tuned NER model combined with a structured regex layer for known-format PII turned out to be the right approach.
Retrieval quality matters as much as generation quality. The BM25 switch was the single highest-leverage change we made, taking the system from off-target section matches to near-perfect retrieval.
We also learned: upload your model to permanent storage the moment training finishes. Recovering a checkpoint from a dropped git stash cost us several hours.
What's next for Securify
- Restore the complete fine-tuned model artifact on HuggingFace so the F1 0.940 checkpoint runs in production
- Expand DIAGNOSIS coverage to include medication names and ICD codes
- Multi-document sessions with cross-document retrieval
- Role-based access so compliance officers see redacted text while credentialed users see originals
- Tamper-evident audit log suitable for SOC 2 reporting
Built With
- bm25
- celery
- fastapi
- gpt-4o-mini
- huggingface
- langgraph
- openai
- railway
- react
- redis
- roberta-base
- typescript

Log in or sign up for Devpost to join the conversation.