-
-

Thumbnail
-
Page 1 Screenshot - Before User Input
-
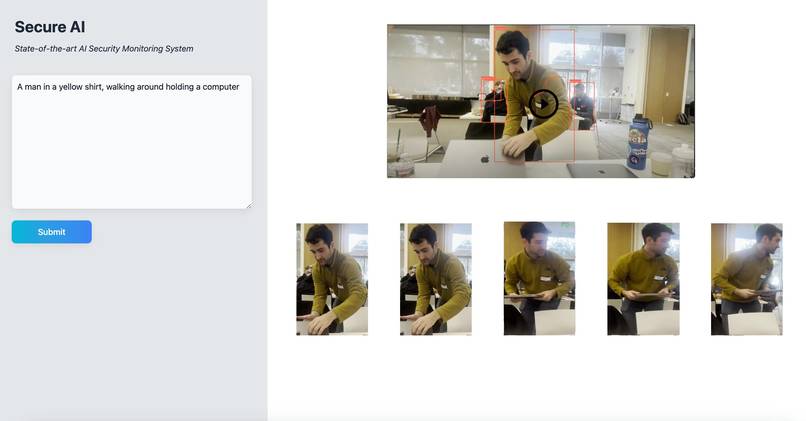
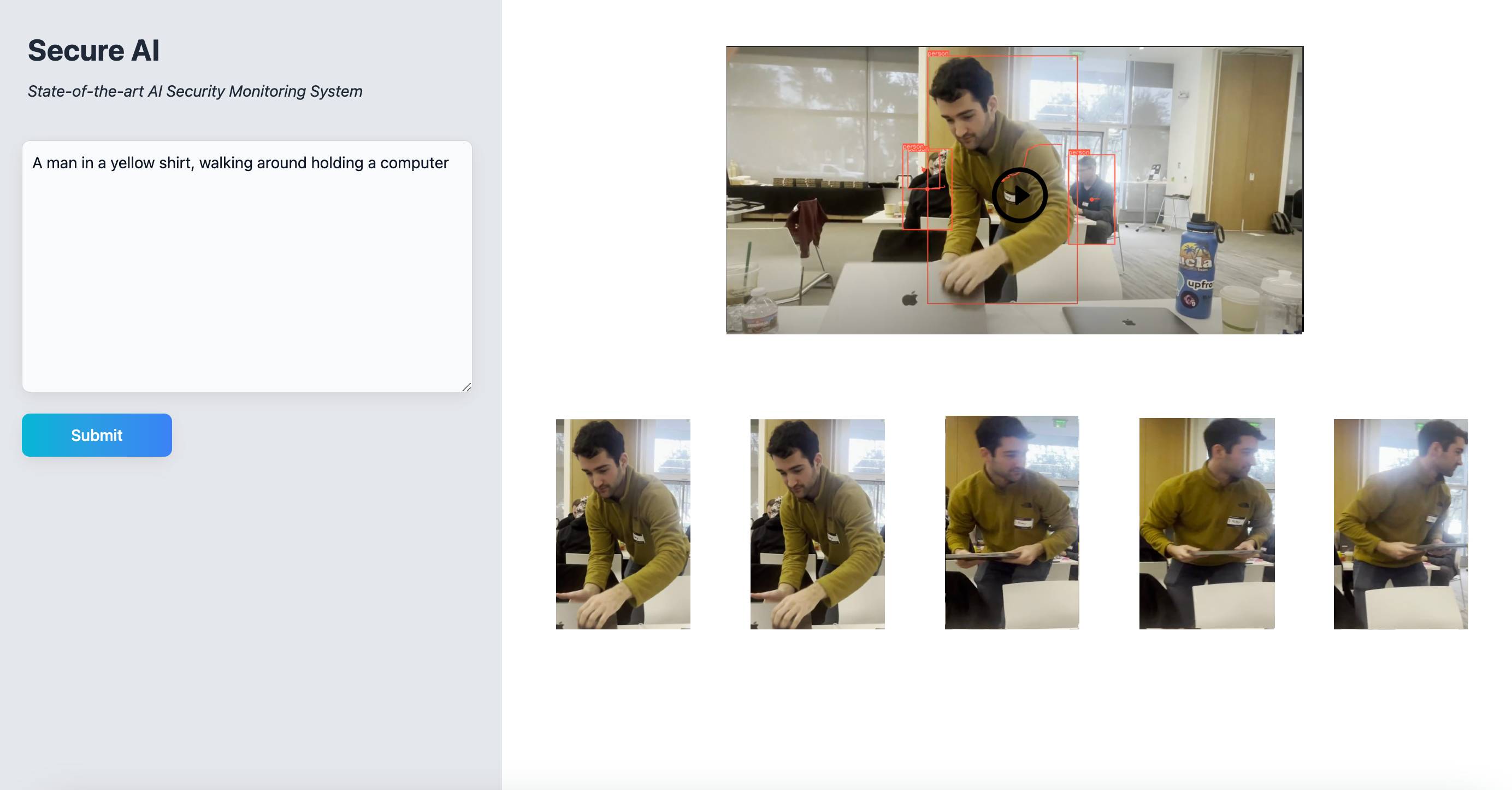
Page 2 Screenshot - After User Input

Problem
Facial recognition systems have been used by the police to solve crime for decades, however, the technology has a critical shortcoming. To be effective, the systems require a clear well-lit photo. Any blurry footage, faces turned at angles, or even minimal disguises like glasses or baseball caps significantly hamper its usefulness. Additionally, in many instances, the police only have a description of the suspect instead of any clear images. With only a description, the criminals could slip away… until now!
Summary
Secure.ai is a tool that scans a video library to find any individuals that match a given description. For example, the police get a witness account that a man in a brown jacket and tan pants just stole a backpack. No worries! The officer can submit that description into Secure.ai and view a dashboard of any relevant footage captured by CCTV.
Benefit
By using this system, law officers don’t need to solely rely on facial recognition or spend hours watching surveillance video. It not only saves money but also speeds up catching criminals and protects people.
User Experience Example
Simply upload your video to Secure.ai and interact with the chatbox as if talking to your technician! For example, you can ask “I have a suspect who is a 6-feet white male, wearing a yellow jacket with a baseball cap. Could you show me the track of the suspect?” Secure.ai will provide you with snapshots of the suspect and a summary looks like “the suspect first visited Safeway at 10am and got into a red sedan, the suspect shows up at ADDRESS at 3pm holding a white plastic bag and was wondering around.”
How we built it
A video library is uploaded into Secure.ai or live-feed is integrated (for the MVP we used static videos). These videos are sent into the YOLO object detection model for image segmentation. From here we passed these segmented images into Gemini Multimodal, a model that allowed us to process and understand text, images, and video. We then embedded these images using OpenAI’s CLIP (Contrastive Language-Image Pre-training) which allowed us to embed how well a given image and a given text caption fit together. We then stored this data in a multimodal vector database (Astra DB). For each query, we retrieve nodes from the multimodal vector database using a similarity search. Then we gather the context frames for each node, showing the time before and after the event. With the contexted nodes, we generate 1) a text summary of the event that happened in the time frame and 2) reference images showing the source of truth of our text summary.
Finally, the server also overlays a tracking box around the target in the original video and sends this new video with the overlay back to the user to be viewed in the dashboard. This is done by using OpenCV and Ultralytics to annotate and serve the new video through an api endpoint. All of this is displayed on a React frontend where the dashboard shows the video clippings, text summary, and segmented reference images.
What's next for Secure.ai
We can also extend the app to understand Sports performance. Secure.ai should have the ability to analyze game recordings. This allows the coaching staff to interact with game recordings much faster to pinpoint team vulnerabilities. An example query for this use case is “How did the QB get sacked in Q4?”
There are many different use cases that we haven't even scratched the surface of.





Log in or sign up for Devpost to join the conversation.