-
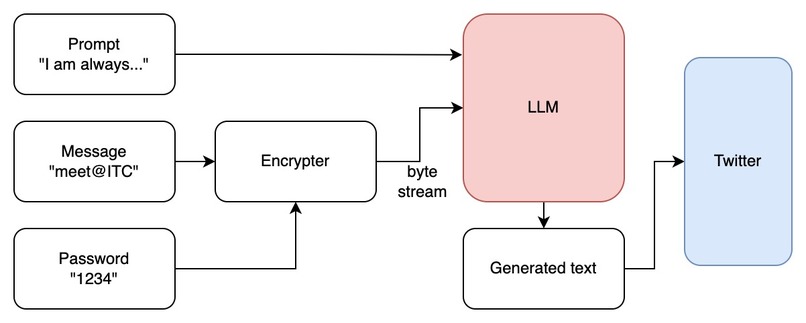
SecretGPT's message encoding pipeline
Inspiration
With the widespread use of social media and the adoption of generative AI technologies like ChatGPT, an intriguing opportunity for covert communication arises. Our project, named SecretGPT, serves two purposes. First, SecretGPT is a proof of concept for concealing secret messages within innocent looking text generated by AI. Second, our project functions as a security audit, shedding light on the potential misuse of publicly available large language models (with publicly available APIs) by bad actors.
It is an ethical question whether large corporations like Google or the Government should store copies of users' encryption keys for public safety. In terms of detecting secret communication, it easy to tell if someone uses cryptography; the message will be a garbled string of characters. However, the method we demonstrate for secret communication (called steganography) allows the sender to hide the fact that secret communication is even occurring. This fundamentally complicates the detection of harmful or illegal content communicated on a public platform. In particular, the feasibility of using generative AI to do steganography by synthesizing text poses a potential threat to personal and national security.
What it does
SecretGPT takes a secret message specified by the user and encodes the information into the generated output of a large language model (LLM). The generated text is seemingly innocent and contextually unrelated to the secret it holds. We provide an example below:
secret: meet@ITC
context prompt: I am always being asked if I like doing hackathons, but
generated text (encoding):
I am always being asked if I like doing hackathons, but my honest opinion, no not really.
The last two I did, one at a university, one with a company were both really great,
the company had a great space with food / snacks and coffee 24 - hours and it felt great,
I met some great folks, but at 4:45 in morning, when you're tired you want your sleep, not to be coding.
So, I am not a huge hackathon guy but, I have a few tips on doing them,
that will hopefully help. The most obvious tip, get a great idea. You can do this,
you can come up, you can do it.
To demonstrate its real world application, we allow the user to post the generated text publicly on Twitter. Anyone with an account can view the generated text, but the masses will not be able to tell that secret communication is occurring. Only the poster and the intended recipients know the presence of the secret. Any recipient with access to Twitter and a shared password can copy the Twitter post into SecretGPT's decoder to extract the message.
How we built it
We use the gradio library to deploy a website that demonstrates our project. The link to our project's website can be found at the bottom of this webpage in the "Try it out" section.
All code was written in python. We deployed the LLM using Huggingface's transformers library. We used a pre-trained model falcon-7b. We experimented with different pre-trained models, but ultimately chose falcon-7b since it offered us a good trade-off between computation complexity and text-realism.
We created a Twitter bot (using the library tweepy) account that can optionally post user-generated text. A link to the Twitter bot's page is found in the "Try it out" section.
To convert the secret to LLM generated text we do the following steps: 1) compression, 2) AES encryption, 3) an entropy coding to obtain the tokens the LLM needs to use to hide the message. While encoding we employ some extra filtering of tokens so that we can guarantee that the LLM output doesn't include undesirable characteristics like newline breaks, some weird spaces, etc.
We used mixed-precision and distributed computing to speed up inferences of the LLM.
Challenges we ran into
The process of encoding secret message bytes into LLM token can (and should for security reasons) be done by a near-optimal entropy coding scheme like arithmetic coding. This would permit us to more closely preserve the probability distributions of tokens randomly selected by the LLM. However, this requires implementing the coding from scratch in a manner that functionally uses arithmetic coding 'backwards'. Due to time constraints, we use a "naive" encoder that simply converts a sequence of bytes into a sequence of 2 (or 4) bit integers. This implementation surprising doesn't degrade the quality of the LLM output but definitely adds a security vulnerability to a clever enough adversary.
We tried using ChatGPT at first, but we found that deploying a pre-trained model on a local Linux server gave us a considerable speed-up.
The decoding process also gave us some challenge. In particular, how does the decoder know when the user's 'context prompt' ends and when encoded message starts? Coincidently, since we are using AES encryption in block cipher mode we can do a simple brute-force of all possible starting positions. An incorrectly chosen starting position will be misaligned when performing decryption.
Accomplishments that we're proud of
Overall, we are thrilled that we got our implementation to work since, going into the project, we were concerned with a lot of technical and subtle barriers.
What we learned
We learned that it is indeed possible to communicate covertly (steganographically) using LLMs as an encoder. We also had a great opportunity to work with new tools and python libraries.
What's next for SecretGPT
- add a near-optimal entropy coding to 1) gain better theoretical security 2) increase the quality of generated text
- use more advanced models, including the current version of ChatGPT
Note: website link expires in 72 hours due to gradio limitations
Built With
- chatgpt
- cryptography
- deep-learning
- huggingface
- llm
- machine-learning
- python
- social-media
- steganography
- torch
- transformers





Log in or sign up for Devpost to join the conversation.