Inspiration
Over 40 million people worldwide are non-verbal or minimally verbal, many of them autistic. Commercial AAC (Augmentative and Alternative Communication) devices cost $3,000–$15,000, and most apps require expensive subscriptions. I asked: What if AI could make a genuinely useful communication tool that costs almost nothing to run, works on any tablet, and actually sounds natural, not robotic?
What it does
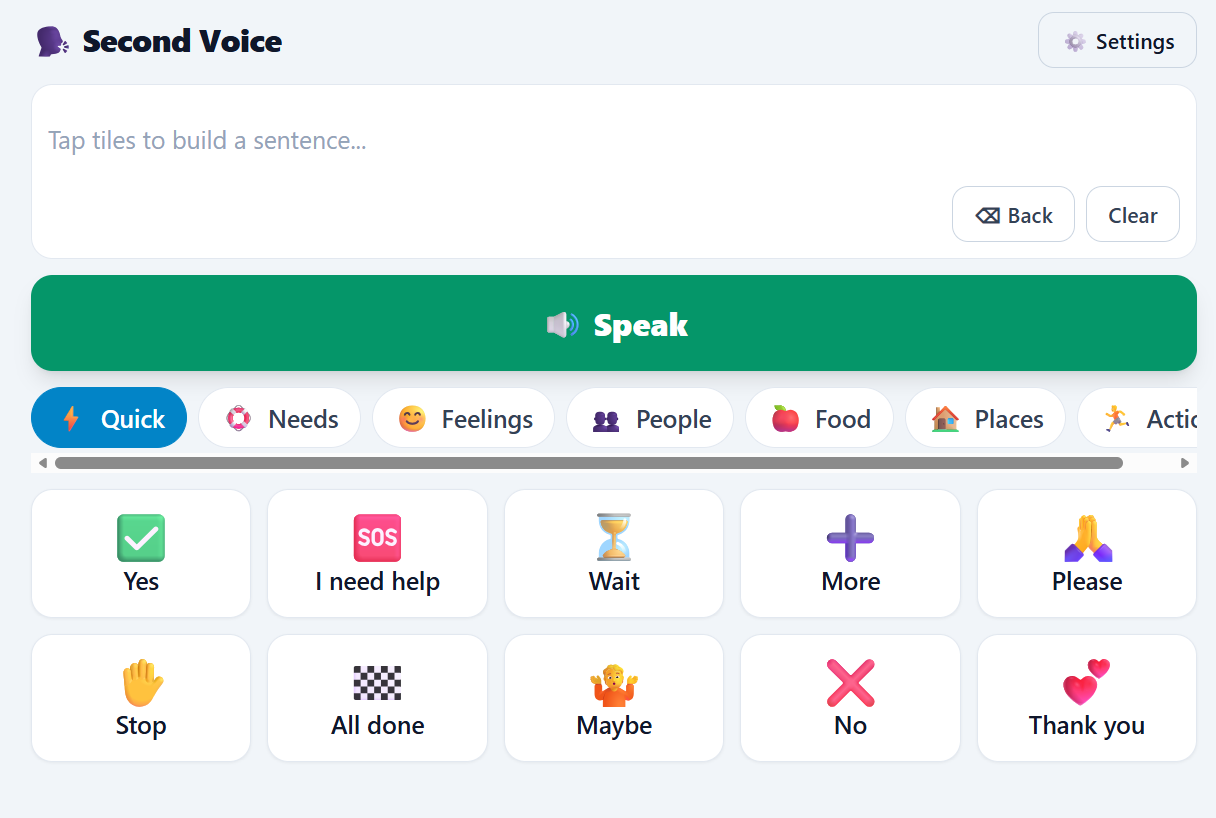
Second Voice is a tap-to-speak communication board:
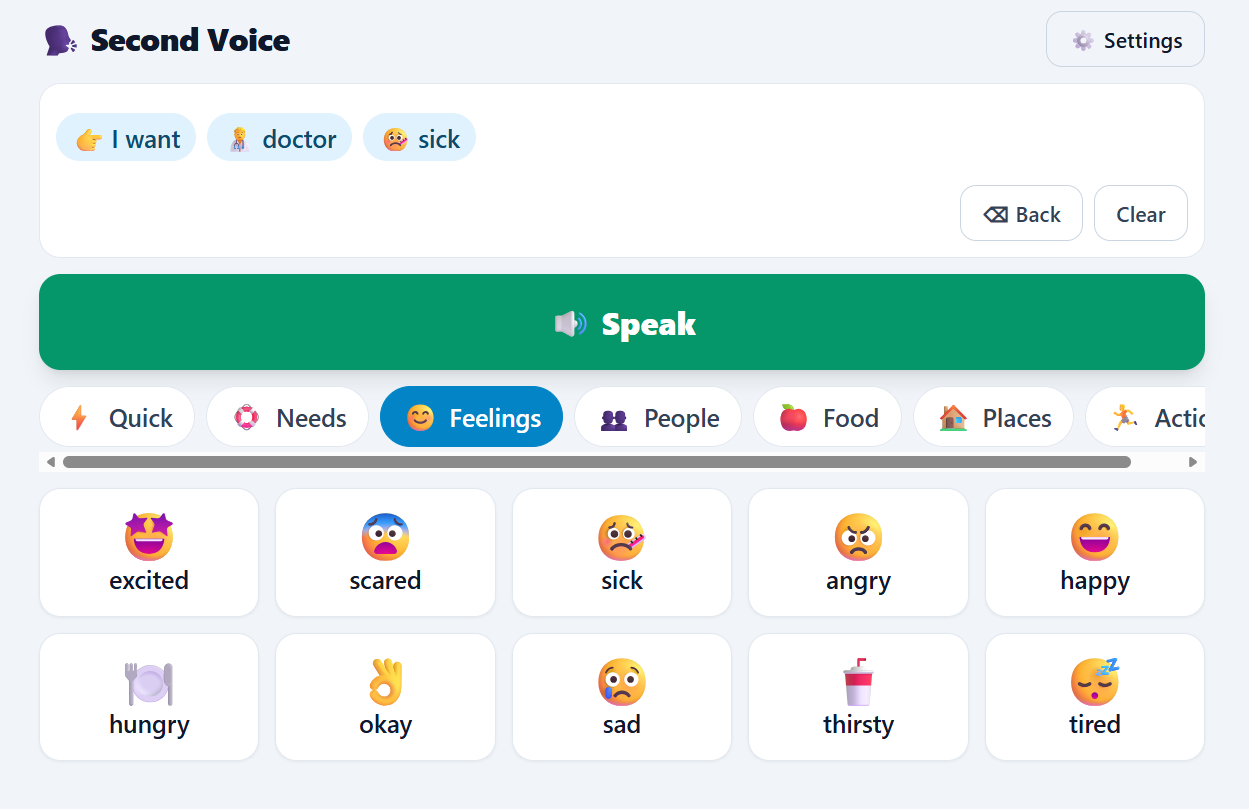
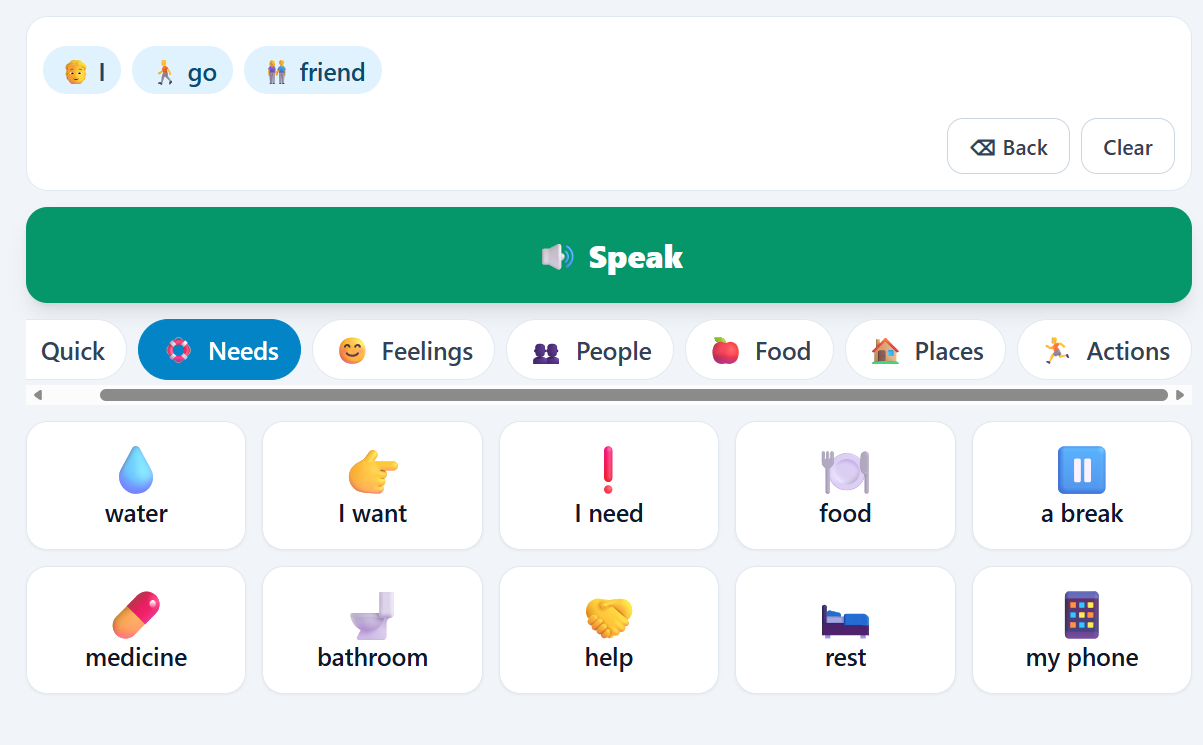
- Tap picture tiles organized into categories (Needs, Feelings, People, Food, Places, Actions) to build a message.
- Gemini AI composes the tapped keywords into a natural first-person sentence ("water" + "want" becomes "I want some water, please.").
- Kokoro TTS speaks it aloud in a natural human voice — entirely on CPU, no cloud dependency for speech.
- The phrase bank learns — tiles you use most float to the top automatically.
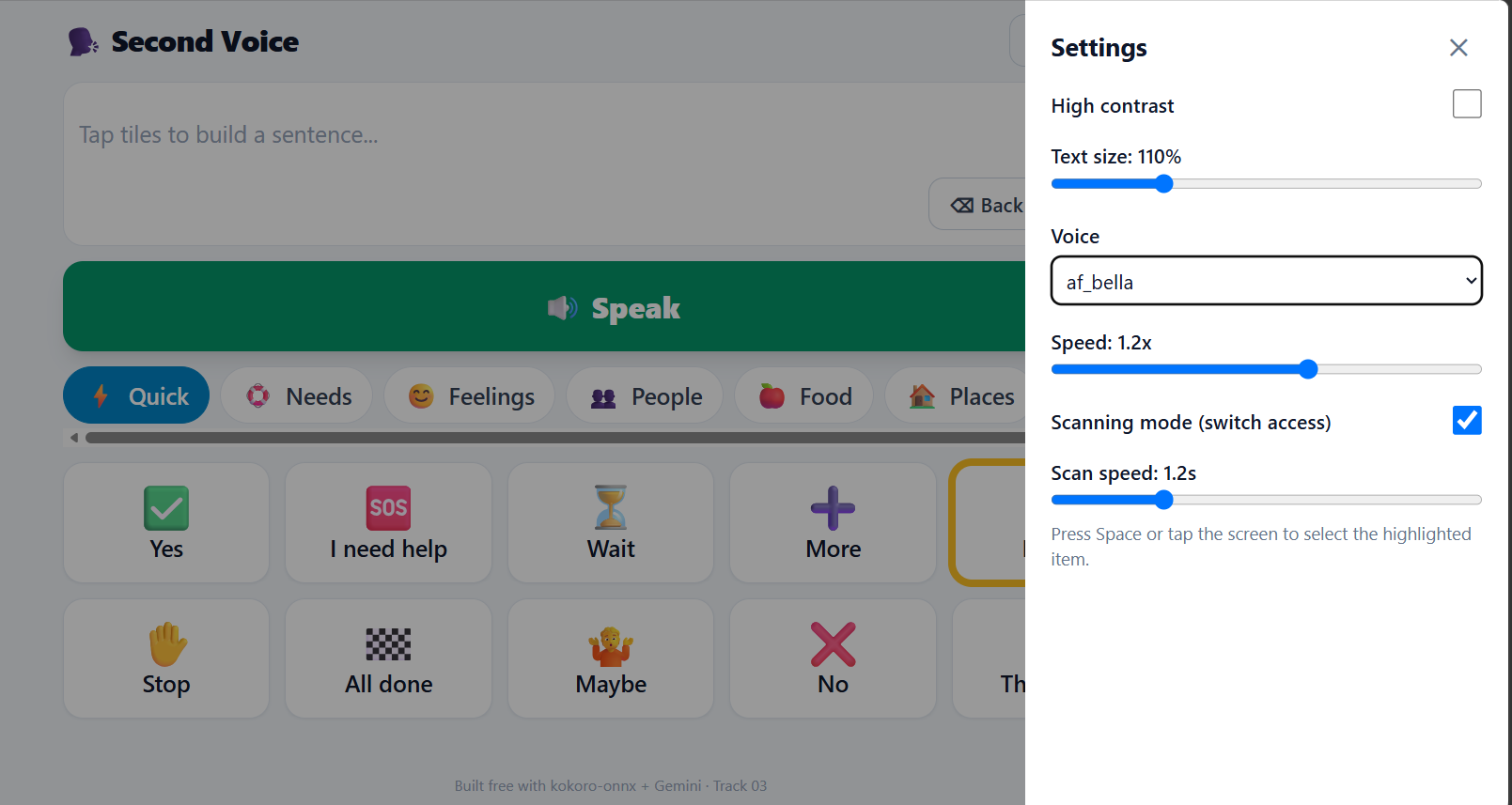
- Accessibility-first — high-contrast mode, adjustable text size, and a scanning mode for single-switch users with motor impairments.
- Installable PWA — works full-screen on a tablet like a dedicated AAC device.
- Quick-reply tiles ("Yes", "No", "I need help", "Thank you") speak instantly with one tap — critical for urgent communication.
How I built it
- Backend (Python + FastAPI):
- SQLite phrase bank with 7 categories and 70 seeded tiles
- Google Gemini 2.5 Flash (free tier) for keyword-to-sentence composition with a graceful plain-join fallback
- kokoro-onnx (the same 82M-parameter Kokoro engine bundled by Voicebox) for CPU text-to-speech returning WAV audio
- Frontend (React + TypeScript + Tailwind + Vite):
- Zustand state management with persisted accessibility settings
- Responsive tile grid, sentence-builder bar with chips, and a large Speak button
- PWA via vite-plugin-pwa with service worker for offline caching
- Scanning mode implementation using interval-based highlight cycling + Space/Enter selection
- Testing:
- Backend smoke tests hitting all 5 endpoints
- 4 Playwright E2E tests covering board loading, quick-reply speech, full compose+speak flow, and sentence editing
Challenges I ran into
- Thinking tokens eating output — Gemini 2.5 Flash's "thinking" mode consumed the output budget, returning truncated sentences. Fixed by disabling thinking via ThinkingConfig(thinking_budget=0).
- No GPU available — full Voicebox requires a GPU. I extracted just the Kokoro ONNX engine (~350MB), which runs great on CPU with sub-second synthesis.
- Browser autoplay restrictions — audio won't play without a user gesture. I ensured every speak action originates from a tap/click event.
Accomplishments that I am proud of
- Zero cost to run — no paid APIs, no GPU, no subscriptions. Gemini free tier + on-device TTS.
- Real accessibility — scanning mode for switch users isn't a checkbox feature; we implemented proper interval cycling with keyboard selection that actually works for motor-impaired users.
- Sub-second speech — kokoro-onnx on CPU delivers natural audio in under a second. The compose+speak round-trip is ~3 seconds total.
- Inspired by real open-source — I didn't just use APIs; I studied Voicebox's architecture and extracted its core engine in a lightweight form.
What I learned
- How AAC systems actually work and what makes them usable (large targets, scanning, symbol+text, frequency-based ordering)
- Gemini's free-tier constraints and how to work within them (deadline minimums, thinking budget control)
- ONNX runtime for running neural TTS models on CPU without framework overhead
- The gap between "AI that's cool" and "AI that helps someone communicate basic needs" — and how small that gap actually is with the right tools
What's next for Second Voice
- Short term (next 2-4 weeks):
- Deploy to DigitalOcean with a public URL and HTTPS
- Add a text-input mode for literate users who want to type freely
- Integrate Unlimited-OCR (free HuggingFace Space) for "read-the-world" — point at a sign or menu and hear it read aloud
- Mid term (1-3 months):
- Personal voice cloning via free HuggingFace Spaces (F5-TTS/XTTS) so users hear their own voice
- Caregiver dashboard for customizing boards, adding tiles, and reviewing usage analytics
- Gemini-powered next-tile prediction based on usage patterns and context
- Multilingual support (kokoro supports 8 languages; Chatterbox supports 23)
- Long term (3-6 months):
- Speech-to-text input for partially verbal users
- Cross-session memory that learns routines ("morning" context surfaces breakfast/bathroom tiles)
- Offline-first mode with bundled local voice for connectivity-free use
- Open-source release with a contributor guide so the AAC community can add symbol sets and languages

Log in or sign up for Devpost to join the conversation.