-
-
System Pipeline
Inspiration
Every semester, students email mentors, professors, and career centers with some version of the same vague sentence: "I want to do X but I'm a Y major with no background in it." The advice they get back is either too generic to act on ("follow your passion") or too overwhelming to start (a 40-step roadmap). We wanted to know whether an AI system could do what a genuinely good mentor does: ask the right clarifying questions, name the assumption that will actually sink the plan, and end the conversation with one small thing to do tonight - not a lecture. Two failed prototypes later, we also got curious about why small open models kept failing at this in such a specific, repeatable way (see "Challenges" below), which became as much a part of the project as the original idea.
What it does
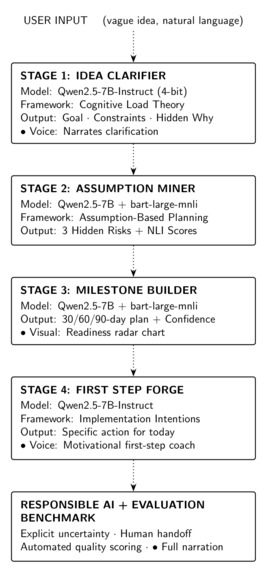
A student types one vague sentence of ambition. Second Brain v3.0 runs it through a five-stage cognitive pipeline and returns a complete, narrated execution plan:
- Stage 1 - Idea Clarifier: decomposes the sentence into a Core Goal, Real Constraints (severity-rated), Hidden Motivation, and Critical Skill Gap.
- Stage 2 - Assumption Miner: surfaces the three hidden assumptions most likely to cause failure, each NLI risk-scored and paired with a free, 7-day, yes/no test.
- Stage 3 - Milestone Builder: generates a confidence-scored 30/60/90-day plan (Foundation, Momentum, Proof) with named platforms and real deliverables.
- Stage 4 - First-Step Forge: forces one IF–THEN-structured action for today, under 45 minutes, zero cost - plus the most tempting wrong first step to avoid.
- Stage 5 - Responsible AI Layer: states explicitly what the AI cannot know about this specific student, scores Path Uncertainty, and hands the decision back to the human.
Every stage is narrated aloud via gTTS, visualized in a five-dimension Readiness Radar, and exported as a Markdown file plus an MP3 the student can keep.
How we built it
The pipeline runs entirely on a free Google Colab T4 GPU with no API key and no gated model access. Qwen2.5-7B-Instruct (4-bit NF4 quantized via bitsandbytes, ~5 GB VRAM) handles all open-ended reasoning across Stages 1–4 through 14+ chat-template prompts. facebook/bart-large-mnli performs zero-shot NLI classification - with no labelled training data - to convert raw model text into calibrated risk and confidence scores. gTTS provides free voice narration, and matplotlib renders the readiness radar as a base64-embedded PNG. We deliberately split the work across three small, single-purpose models instead of asking one model to reason, score, and narrate, which kept VRAM under 7 GB total and made each component independently debuggable.
Challenges we ran into
Our first two versions (v1: flan-t5-base, 248M; v2: flan-t5-xl, 3B) both produced plans that literally echoed our prompt templates back - milestones reading [specific action] and first steps reading "I will [[start]] at [[time]]." We initially assumed this was a prompt-wording problem and rewrote the prompts repeatedly with no improvement. The actual root cause was architectural: T5-family encoder–decoder models are trained on text-to-text mapping and tend to copy template syntax verbatim, regardless of prompt wording. Switching to a decoder-only instruction-tuned model (Qwen2.5-7B) eliminated the problem completely rather than reducing it. We also hit a silent AttributeError from using torch.cuda.get_device_properties(0).total_mem instead of .total_memory, and had to build a three-tier parsing fallback (numbered-list regex → sentence splitting → individual regeneration) to guarantee exactly three milestones per phase even when the model's own formatting drifted.
Accomplishments that we're proud of
- Zero template-leakage incidents (100%) across every benchmarked test idea - empirically confirmed, not just claimed.
- A working, automated 4-metric quality benchmark (Specificity, Relevance, No-Template-Leak, Detail Depth) that scored a 74% aggregate quality across three diverse test ideas.
- A genuinely free, keyless, end-to-end pipeline: model loading, reasoning, risk scoring, voice narration, and export - running in ~6 minutes on a free-tier T4.
- Grounding every stage in a named, peer-reviewed framework (Sweller 1988, Dewar et al. 2002, Gollwitzer 1999) instead of arbitrary prompt design.
- A Responsible AI layer that names what the AI cannot know about the specific student, rather than a generic disclaimer.
What we learned
The biggest lesson was that model architecture family predicts failure mode better than prompt engineering effort: no amount of prompt rewriting fixed the bracket-echoing problem in our T5-based versions, because the behavior was a property of the encoder–decoder objective itself, not the wording we gave it. We also learned that confidence and risk scores are far more trustworthy — and far more useful to the end user — when computed by an independent model (zero-shot NLI) rather than self-reported by the same generator that wrote the text. Finally, we learned that "responsible AI" is more convincing as a set of concrete, per-output mechanisms (confidence scores, uncertainty ratings, explicit unknowns) than as a single disclaimer sentence at the bottom of the page.
What's next for Second Brain: Cognitive Scaffold Engine
- Expand the benchmark test set beyond three ideas and add demographic diversity to strengthen the specificity/relevance claims.
- Raise the Detail Depth ceiling (currently 39% average) by requesting longer minimum responses per stage without reintroducing genericness.
- Add multilingual voice narration using gTTS's existing language support, currently wired for English only.
- Run an ablation between 4-bit NF4, 8-bit, and full-precision inference to quantify the actual quality/VRAM trade-off.
- Pursue longitudinal validation: track whether students who follow a generated plan actually progress through their stated milestones.


Log in or sign up for Devpost to join the conversation.