Inspiration
Every year, millions of young graduates stand at high-stakes career crossroads. For a final-year CS student like Priya—facing zero financial runway, family dependencies, and severe burnout from college projects—this isn't just about choosing a job; it’s a high-stakes life decision where the wrong path carries immense downside risk.
When students try to navigate these forks, they are forced to rely on generic LinkedIn posts, peer pressure, or costly career counselors. Humans simply aren't wired to compute how eleven personal variables non-linearly interact across eight completely different life paths simultaneously. We wanted to build a true "Second Brain"—an intentional, data-driven engine that evaluates complex risk interactions to make these life-altering tradeoffs entirely legible.
What it does
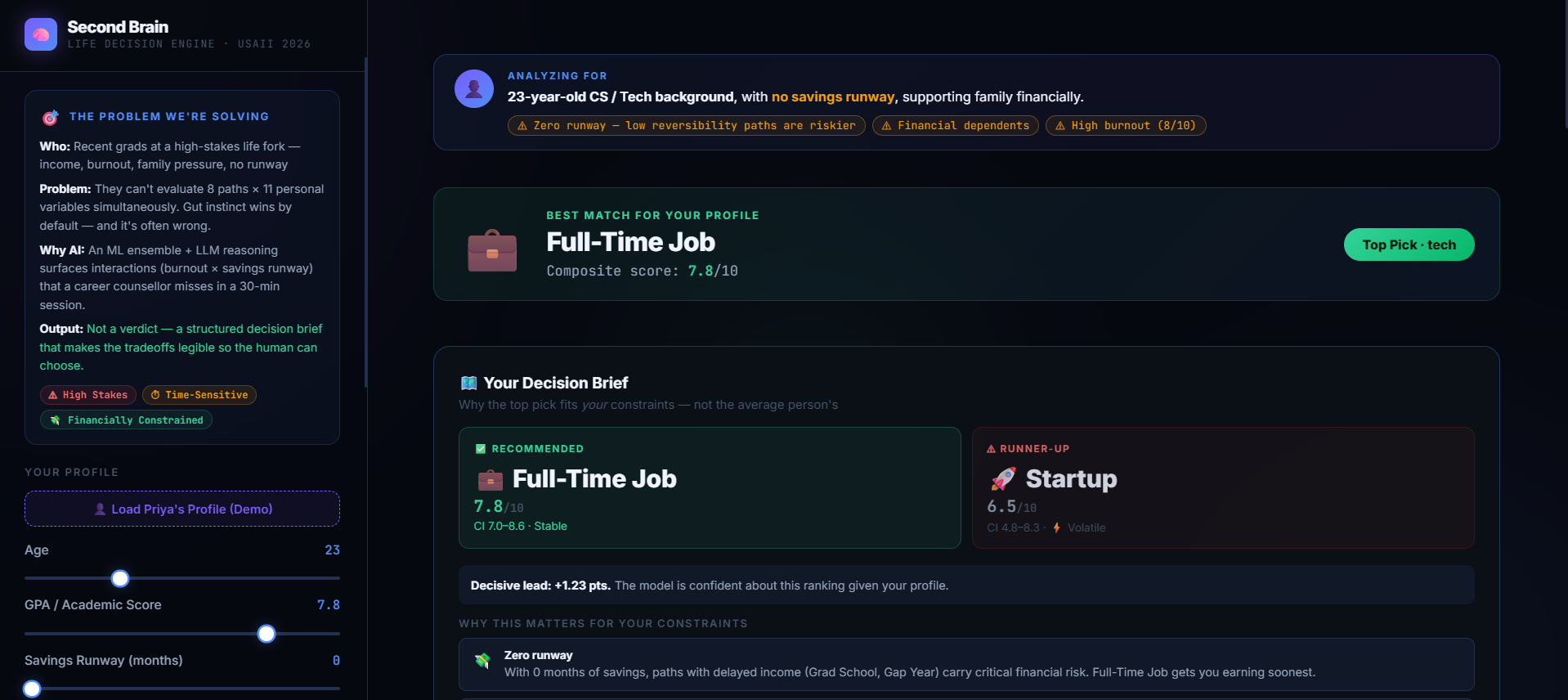
Second Brain: A Heterogeneous AI Ensemble for Life Decisions is an advanced decision simulator that evaluates a user's multi-variable personal profile against 8 major life paths: Grad School, Full-Time Job, Startup, Bootcamp, Freelance, Gap Year, Nursing, and Skilled Trades.
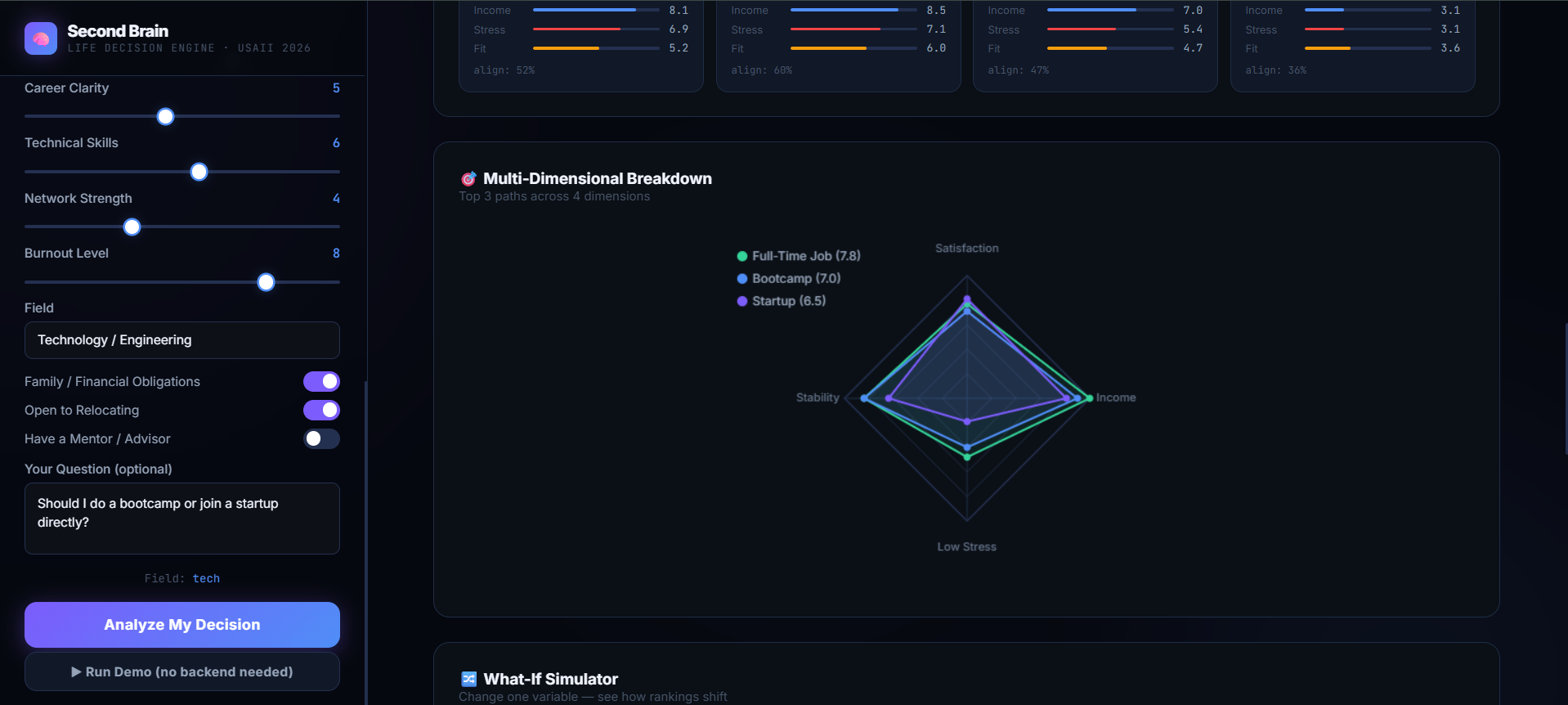
Instead of providing a generic recommendation, it analyzes the user across four core dimensions: 5-Year Satisfaction, Income Potential, Stress, and Time to Impact.
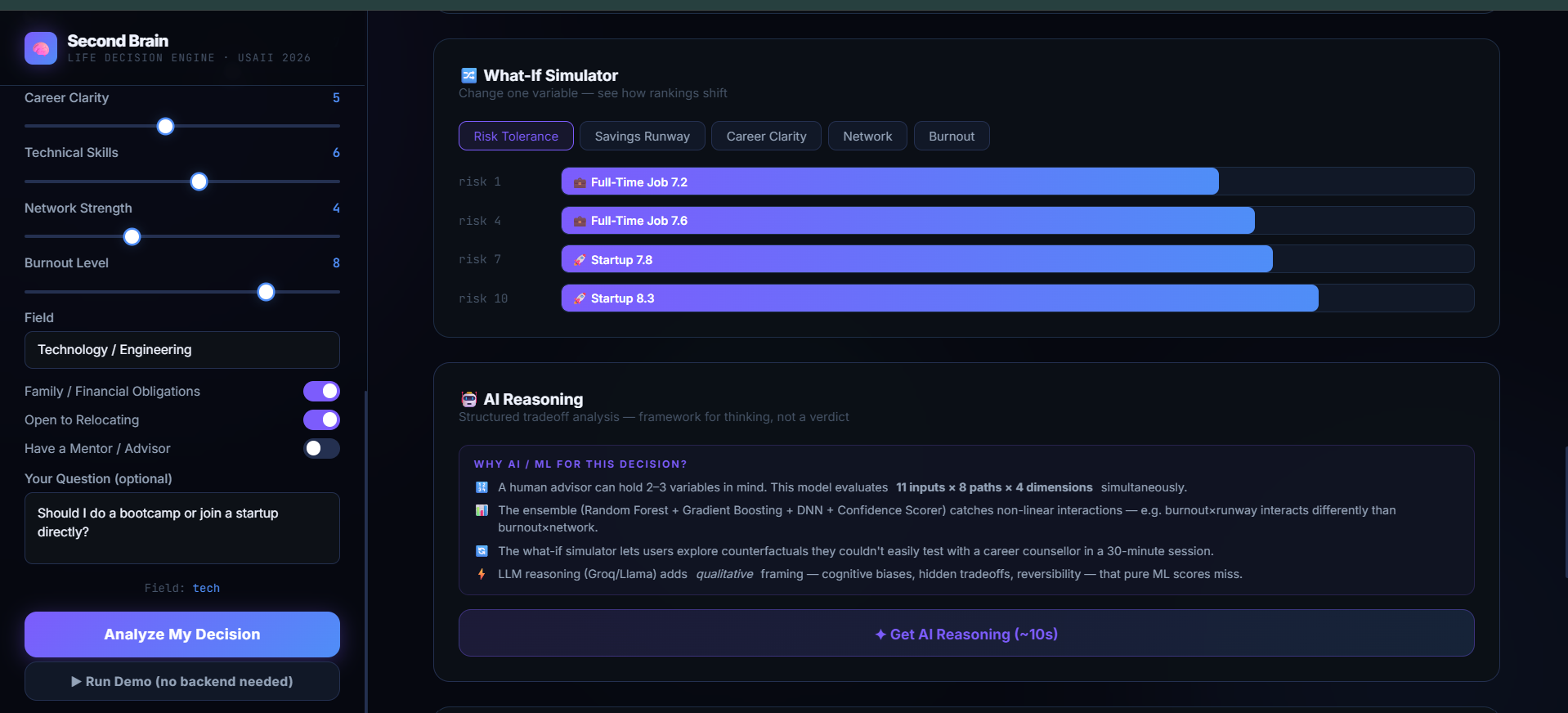
Constraint-Aware Rankings: It runs an ensemble of 4 machine learning models to score each path. For instance, it can detect if a user's risk tolerance is high but their savings runway is dangerously low, lowering a volatile path's ranking in favor of stability.
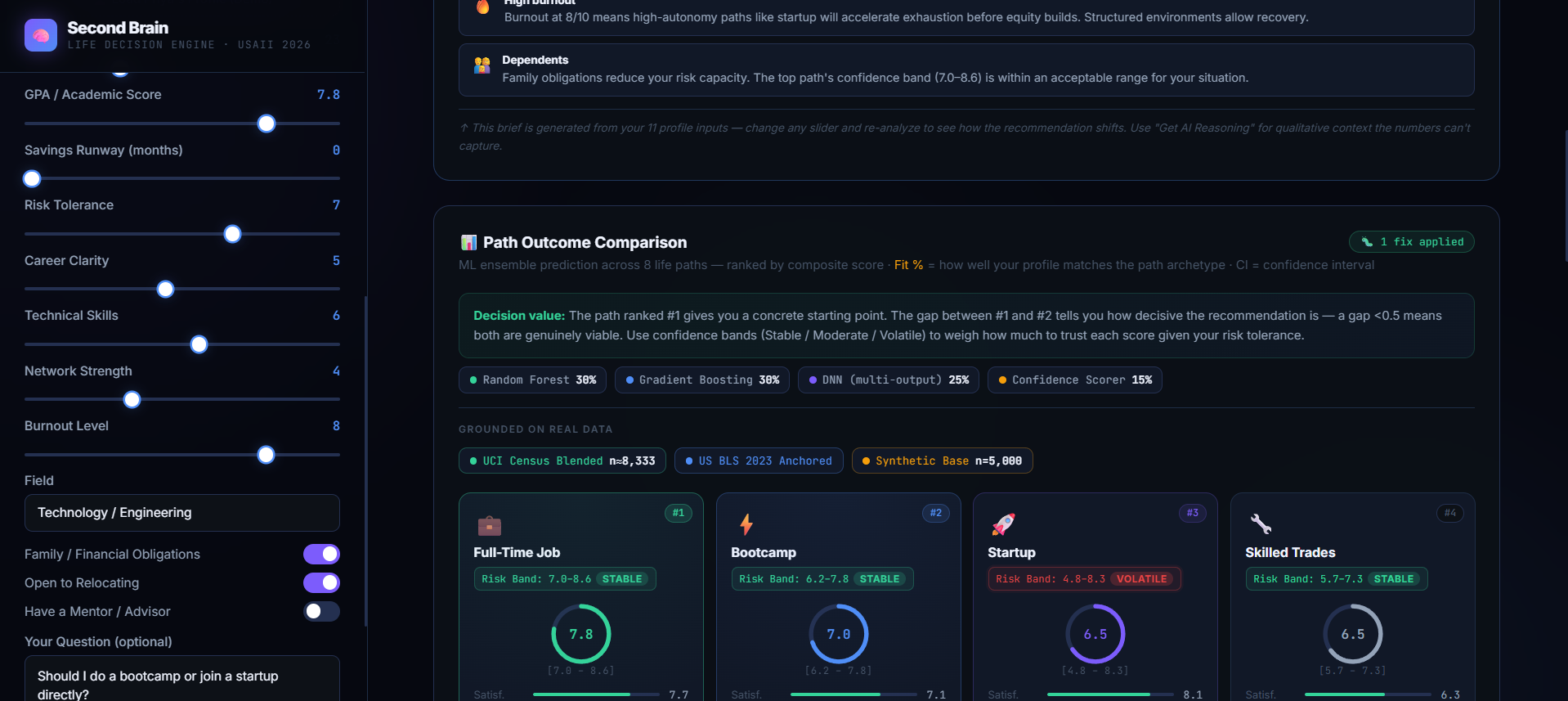
Monte Carlo Confidence Bands: It calculates explicit upper and lower statistical bounds (Stable vs. Volatile), preventing users from only looking at the "highest score" without seeing the underlying downside risk.
What-If Simulator: Users can dynamically tweak individual variables (e.g., "What if I build up 6 months of savings first?") and watch the entire machine learning engine re-rank paths in real time.
LLM Reasoning & De-Risking Action Plan: Backed by LLaMA 3.3 70B, it uncovers hidden qualitative tradeoffs, flags psychological biases, and generates a concrete checklist of actionable next steps to actively de-risk the chosen path.
How we built it
We built a modern web dashboard connected to a robust, heterogeneous machine learning and reasoning backend pipeline.
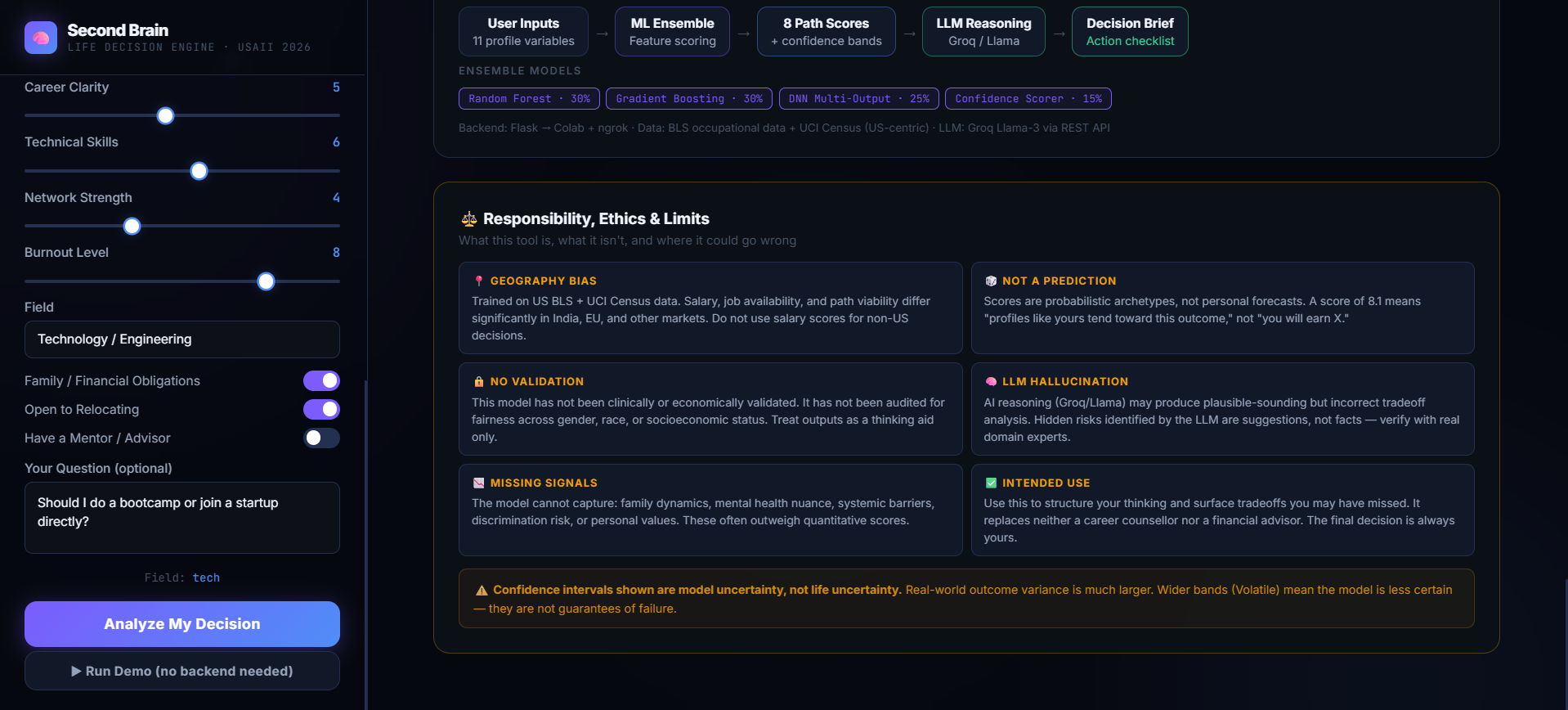
The Tabular Data Core: To anchor our model in reality, we fetched 32,561 real respondent rows from the UCI Adult Census Dataset (mapping workclasses to risk tolerance, marital status to family obligations, and actual income brackets to financial baselines). We blended this 40% real-world data with 60% diverse, domain-knowledge synthetic data and further calibrated it against U.S. Bureau of Labor Statistics (BLS) 2023 Education Pays charts and CIRR bootcamp outcomes.
The Heterogeneous ML Ensemble: We trained and stacked multiple architectures to balance variance and bias:
Random Forest (30% weight): Captures non-linear feature interactions.
Gradient Boosting (30% weight): Sequentially minimizes residuals to prevent overfitting.
Multi-Output Deep Neural Network (25% weight): Jointly predicts all 4 metric dimensions simultaneously, capturing cross-dimension co-dependencies.
Decision Confidence Scorer (15% weight): Evaluates exact cosine similarity against multi-dimensional path archetypes.
The Reasoning Layer: We utilized Groq LLaMA 3.3 70B via a high-speed REST API. It ingests the strict numerical outputs from the ensemble as a grounding context, preventing hallucination while structuring an incredibly thorough qualitative brief into a clean, custom JSON schema.
The Frontend: Crafted in vanilla HTML5, CSS3, and JavaScript using micro-component staggers and dynamic rendering for a lightweight, premium UX that works fully in demo mode or live API connection.
Challenges we ran into
During testing, we discovered a massive architectural flaw: our weighted ensemble was originally predicting identical averages across all paths for a given user profile. We realized that our pipeline was passing the user's base attributes to the models but leaving out the target path vector itself! This meant the ensemble was completely blind to which path it was actually grading.We fixed this by creating an explicit feature matrix row for each of the 8 paths per user, tracking the label-encoded path ID (path_enc) right into the global feature array. This immediately restored path-specific signals, shooting our ensemble accuracy to an R^2 of 0.80 on Gradient Boosting.
Accomplishments that we're proud of
Escaping the "Wrapper" Trap: We didn't just build another skin over an LLM API. The core predictions of this engine are driven by pure, mathematical statistical modeling and deep learning trained on real public datasets.
True Decision Value: The resulting UI doesn't just bark commands at the user. By showcasing the Monte Carlo risk bands, a user with high constraints can immediately see that while an option like a startup has a high score ceiling, its massive volatility makes it dangerously unstable for their current situation.
The UI Fidelity: Packing live what-if parameter updating, modular radar chart rendering, and an interactive de-risking checkbox framework into a single file is an implementation we are incredibly proud of.
What we learned
We learned that numbers and text need each other in Responsible AI. A pure machine learning score lacks the contextual empathy a stressed user needs to understand why a path is ranked a certain way. On the flip side, a pure LLM application lacks the mathematical grounding required to safely evaluate high-stakes financial and life decisions. Blending the two by using the ML ensemble to strictly fence and ground the LLM's prompt context is the ultimate blueprint for dependable, decision-support interfaces.
What's next for Second Brain: A Heterogeneous AI Ensemble for Life Decisions
Our primary objective next is removing geographic data bias. Because the UCI Census and BLS datasets reflect Western economic structures, the salary and satisfaction metrics don't fully translate to emerging markets like India or localized economic regions. We plan on integrating local datasets (such as Indian NSSO data or localized tech salary indexes) to allow localized geographic toggling, ensuring the tool is as accurate for a student in New Delhi as it is for one in New York.
Built With
- css3
- deep-learning
- flask
- flask-cors
- gemini
- groq
- html5
- javascript
- llama-3.3
- machine-learning
- numpy
- pandas
- python
- scikit-learn
- tensorflow

Log in or sign up for Devpost to join the conversation.