Inspiration
Every year, millions of young graduates are at critical junctures when it comes to their careers. For a CS graduate in his or her final year, such as Priya, with no financial cushion, family commitments, and extreme fatigue due to college projects, this is not an ordinary decision but a critical one in terms of making the right choice where failure would carry extremely high risk. When students struggle to make such decisions, all they are left with are generalized LinkedIn articles, peer pressure, or professional help from expensive career counselors. Our brains have not evolved to calculate how 11 different factors of our lives affect each other nonlinearly in 8 different ways.
What it does
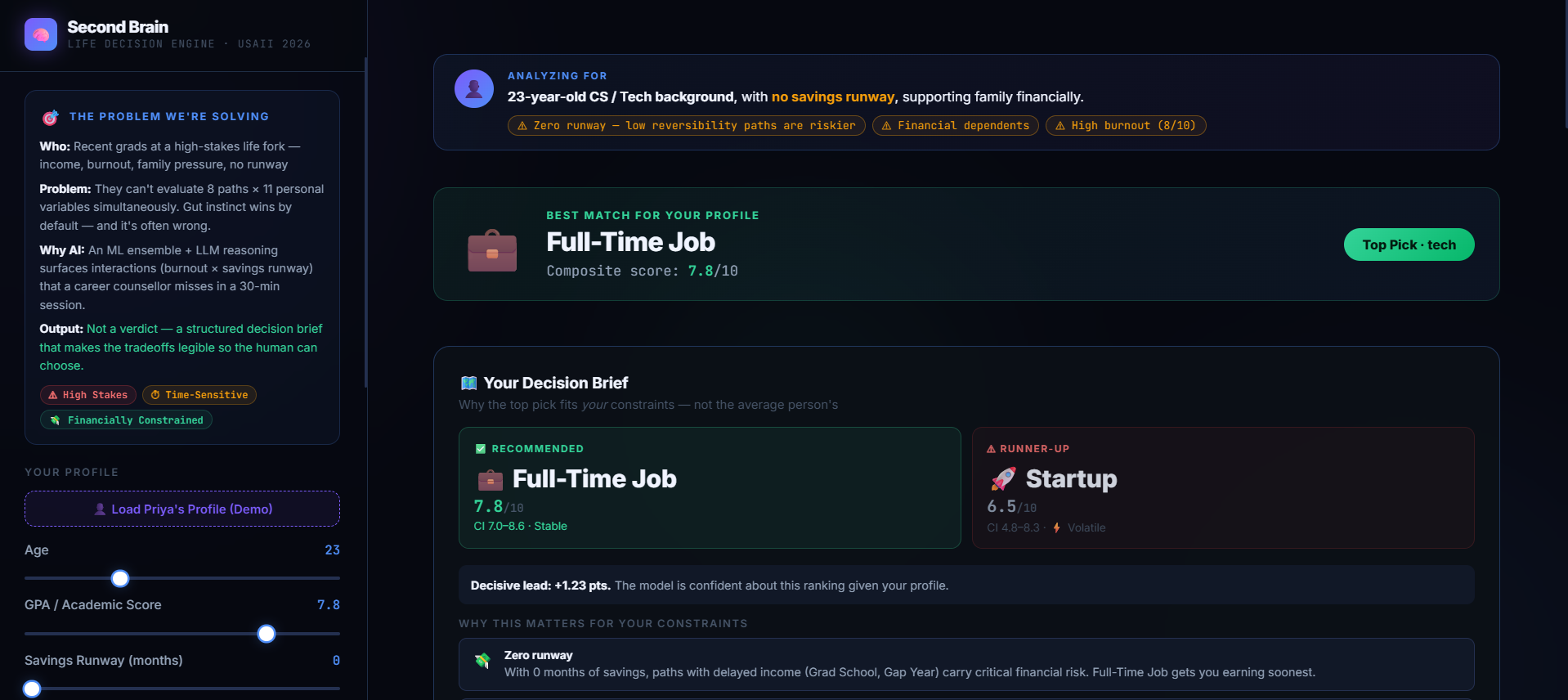
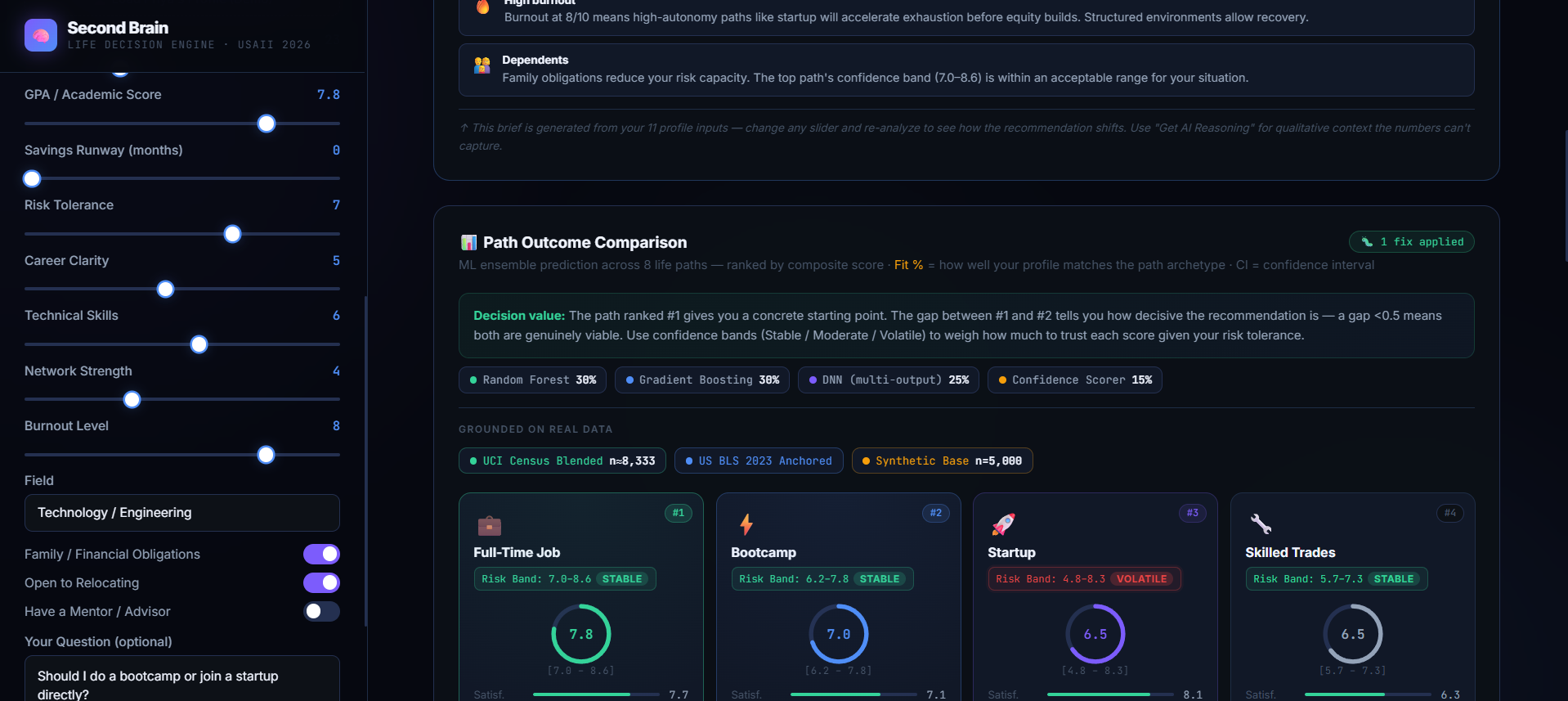
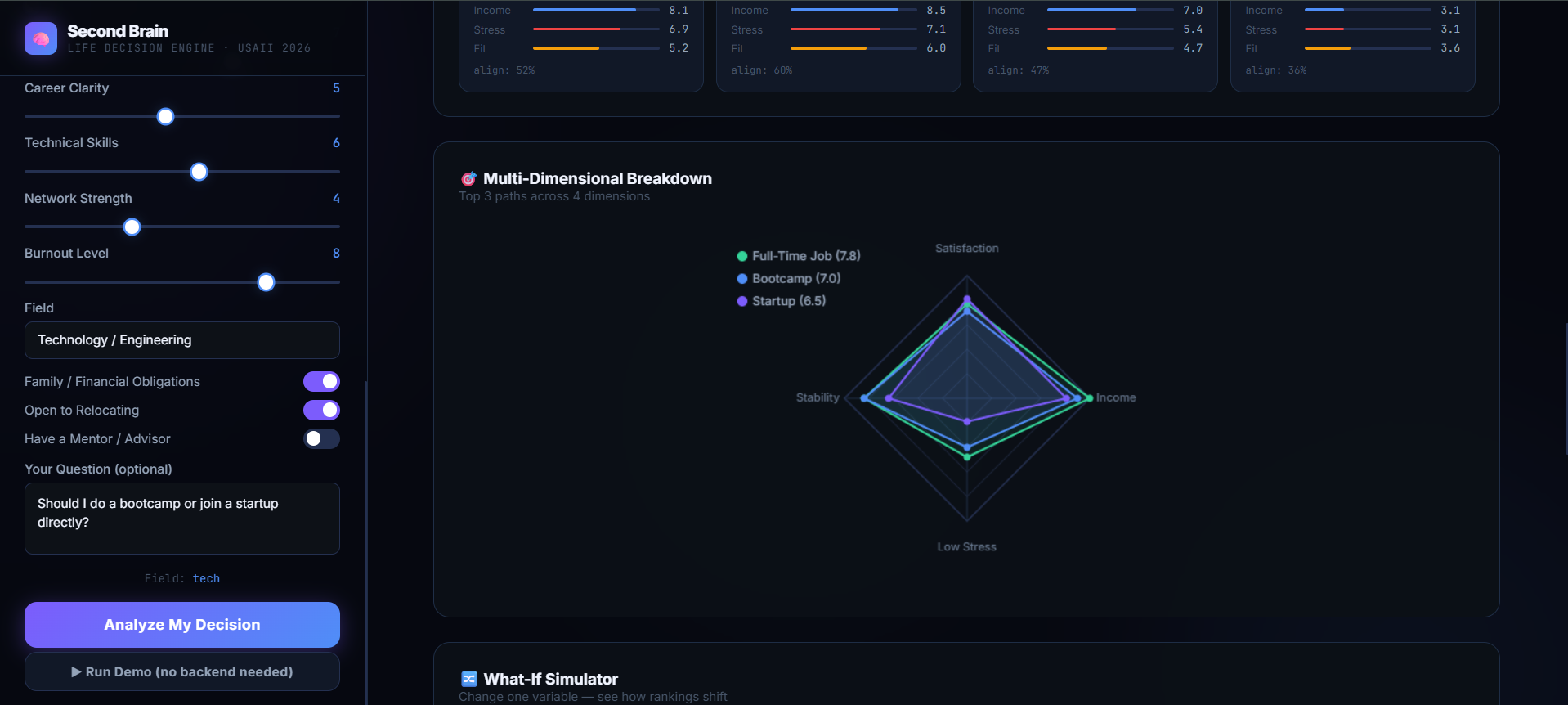
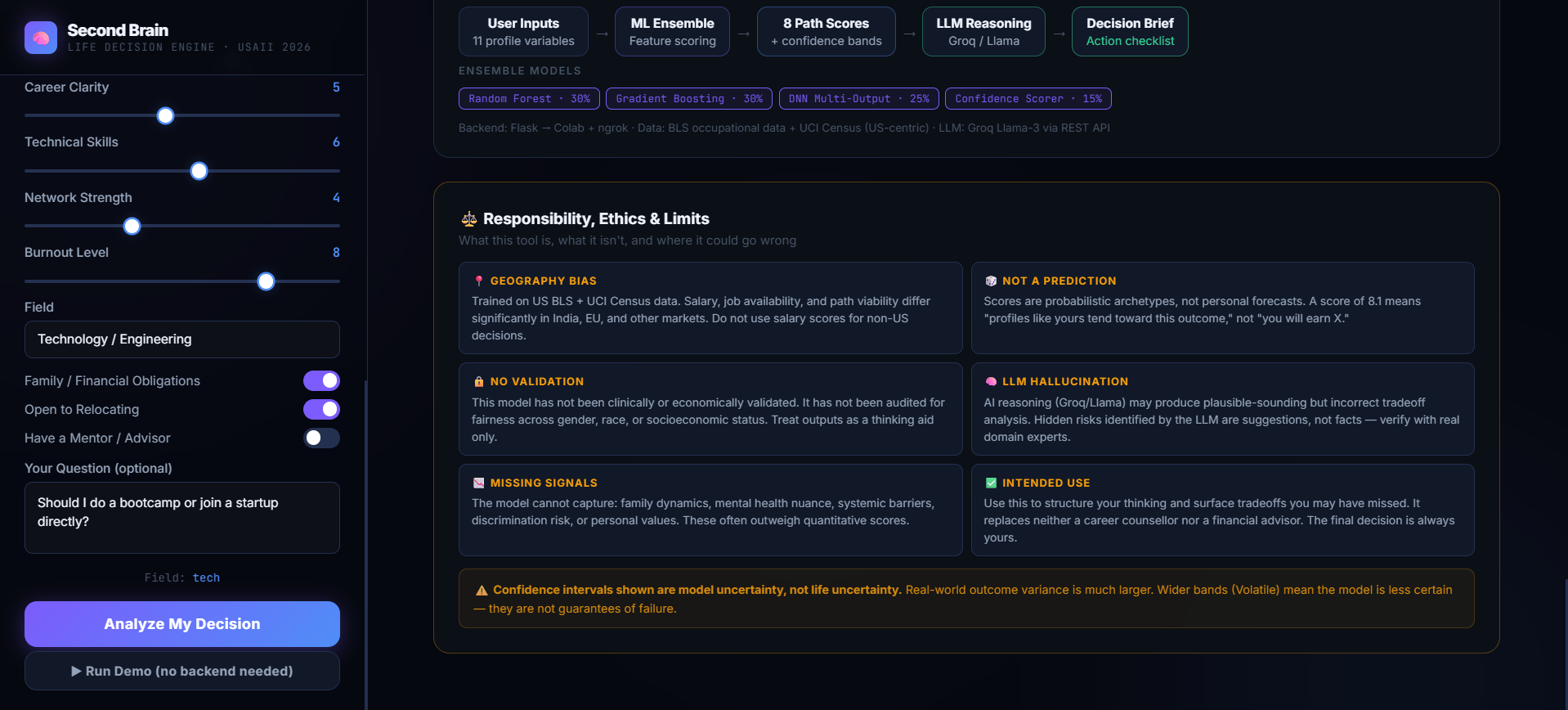
Second Brain: A Heterogeneous AI Ensemble for Life Decisions is a state-of-the-art decision simulator that scores a user's multi-dimensional personal profile against 8 major life paths: Graduate School, Full-Time Work, Start-up, Bootcamp, Freelance, Gap Year, Nursing, and Skilled Trades. Rather than offering a cookie-cutter recommendation, it assesses the user based on four primary dimensions: 5 Year Satisfaction, Income Potential, Stress, and Time to Impact.
-> Constraint-Aware Rankings: It executes an ensemble of 4 machine learning models to rank each option. For example, it identifies when a user has a high risk tolerance but insufficient savings runway, reducing the volatile path's rank in favor of a more stable choice.
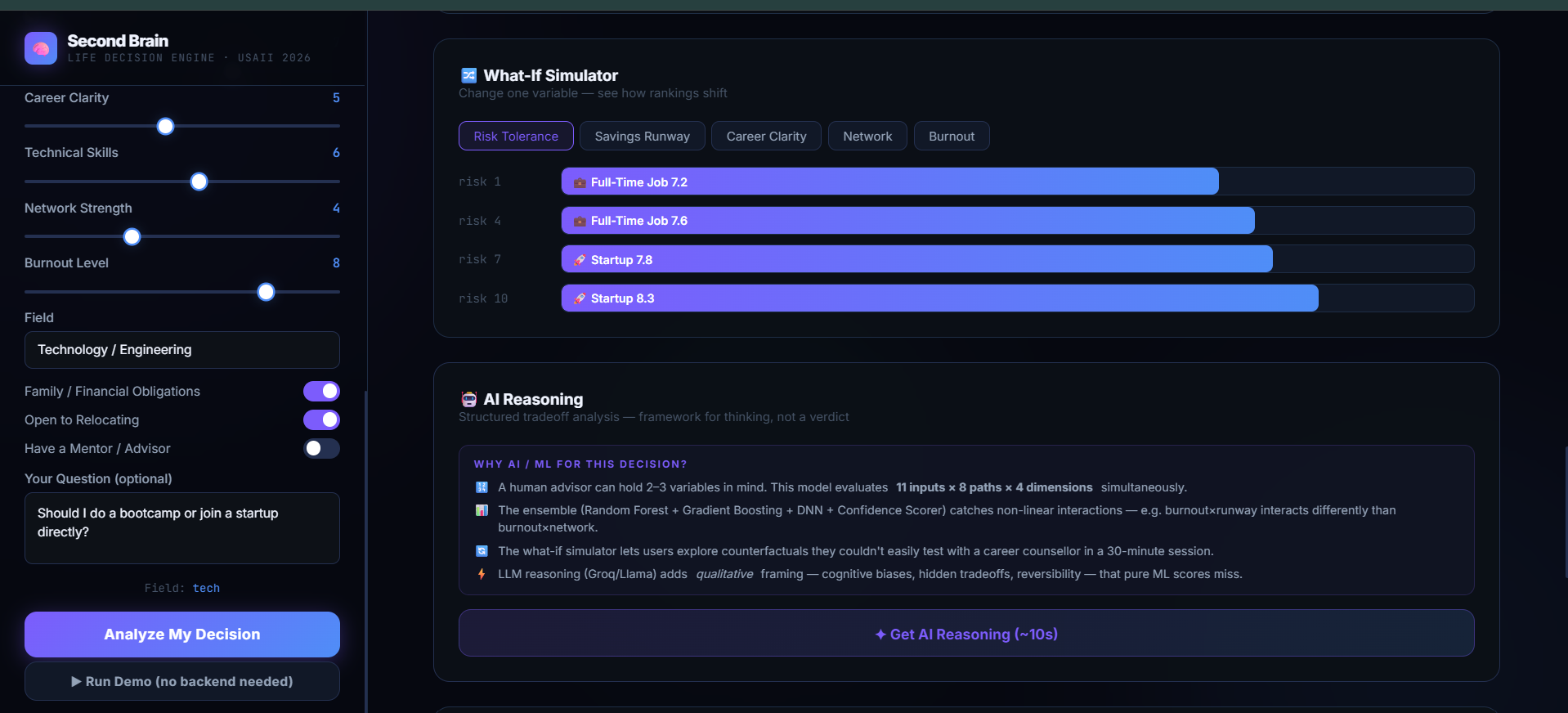
-> Monte Carlo Confidence Bands: It computes explicit statistical bounds (stable vs. volatile) of an option, thus not allowing users to only rely on the "best score" without knowing the risk factor behind it. -> What-If Simulator: It enables users to manipulate variables dynamically ("What if I save up 6 months worth of savings first?") and sees how the entire machine learning engine re-ranks paths.
-> LLM Reasoning & De-Risking Action Plan: Powered by LLaMA 3.3 70B, it discovers hidden qualitative trade-offs, highlights psychological biases and provides a step-by-step action plan.
How we built it
-> Tabular Data Core: In order to connect our model with reality, we extracted 32,561 actual respondent records from the UCI Adult Census Dataset (workclasses were mapped to risk aversion levels, marital statuses to family responsibilities, and actual income ranges to financial baselines). The mixture of 40% of the actual world data was combined with 60% of different synthetic data based on domain knowledge and adjusted according to BLS 2023 Education Pays graphs and CIRR Bootcamp results. -> Heterogeneous ML Ensemble: Multiple architectures were trained and ensembled for balancing bias and variance:
- Random Forest (30%): Non-linear feature interaction.
- Gradient Boosting (30%): Minimization of residuals through sequential learning to avoid overfitting. -Multi-Output Deep Neural Network (25%): Simultaneous prediction of all four metric dimension at once, considering dependencies between dimensions.
- Decision Confidence Scorer (15%): Cosine similarity with multi-dimensional path archetype. -> Reasoning Layer: We leveraged Groq LLaMA 3.3 70B through a fast REST API. The model takes as input the exact numerical output from the ensemble to create a grounded context without hallucination, while formatting a highly detailed qualitative brief in a custom JSON format. -> The Frontend: Developed in plain HTML5, CSS3, and JavaScript (index.html) with micro-components and dynamic rendering to deliver a light-weight, high-end UX that functions flawlessly in both demo and live API modes.
Challenges we ran into
As part of testing, it was identified that there was a huge architectural flaw in that the weighted ensemble model was outputting average results for all paths for a certain user profile. We realized that while we were feeding the base features of the user into the models, we weren’t feeding the actual target path vector at all! As a result, our weighted ensemble model didn’t know which path it was scoring at all! The way we fixed this problem was to create an explicit row feature vector for each of the 8 paths of each user, with the path ID (path_enc) label encoded directly into the global features array.
Accomplishments that we're proud of
-> Breaking out of the "Wrapper" Box: Our solution was not another wrapper around the LLM API. Predictions from this engine are powered purely and mathematically using statistical modeling and deep learning on actual public datasets.
-> True Decision Value: The output UI does not bark orders to the user. By highlighting the Monte Carlo risk band, the user who has stringent requirements realizes instantly that although something like a startup may have a very high score ceiling, its volatility renders it too risky for his current scenario. The -> UI Fidelity: Implementing live parameter updates of the what-if kind along with the modular radar chart creation system and the de-risking checkboxes in a single file is something we are very proud of.
What we learned
The lesson we learned is that numbers and language must be married for Responsible AI. A score generated purely through machine learning does not have the empathy needed for the anxious user to see how it is ranked. Inversely, an application built on pure language model lacks the mathematically rigorous foundation needed for the proper assessment of important life decisions. This marriage between both is achieved by rigorously bounding the language model’s prompts using machine learning.
What's next for Second Brain: A Heterogeneous AI Ensemble for Life Decisions
The next step is to eliminate geographic data bias. Since the UCI Census and BLS datasets have Western economic setups, the income and satisfaction scores cannot be extrapolated to economies that are still developing such as India, or to economic regions. The idea is to incorporate datasets from local economies (for example, Indian NSSO or localized technology salary indices) so that there can be geographic location toggle functionality.
Built With
- chatgpt
- css3
- deep-learning
- flask
- flask-cors
- gemini
- groq
- html5
- javascript
- llama-3.3
- machine-learning
- numpy
- pandas
- python
- scikit-learn
- tensorflow






Log in or sign up for Devpost to join the conversation.