-
-
second brain
Inspiration
As a solo creator managing multiple client projects, design ideas, and creative feedback at once, I constantly struggled to keep track of everything I learned. Notes scattered everywhere, ideas forgotten, feedback lost in old chats. Alongside my BBA studies at Indira Gandhi National Open University, I create AI-powered high-end campaign photoshoots for a fashion brand called Dash and Dot — and I needed a system that doesn't just store information, but actually understands it. That's what inspired Second Brain.
What it does
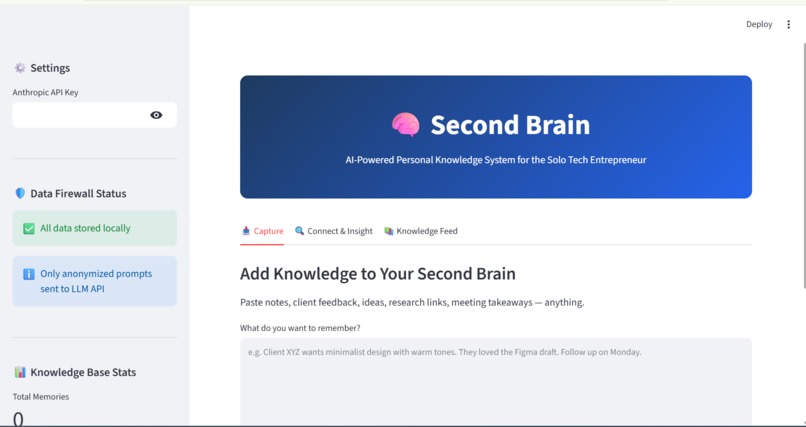
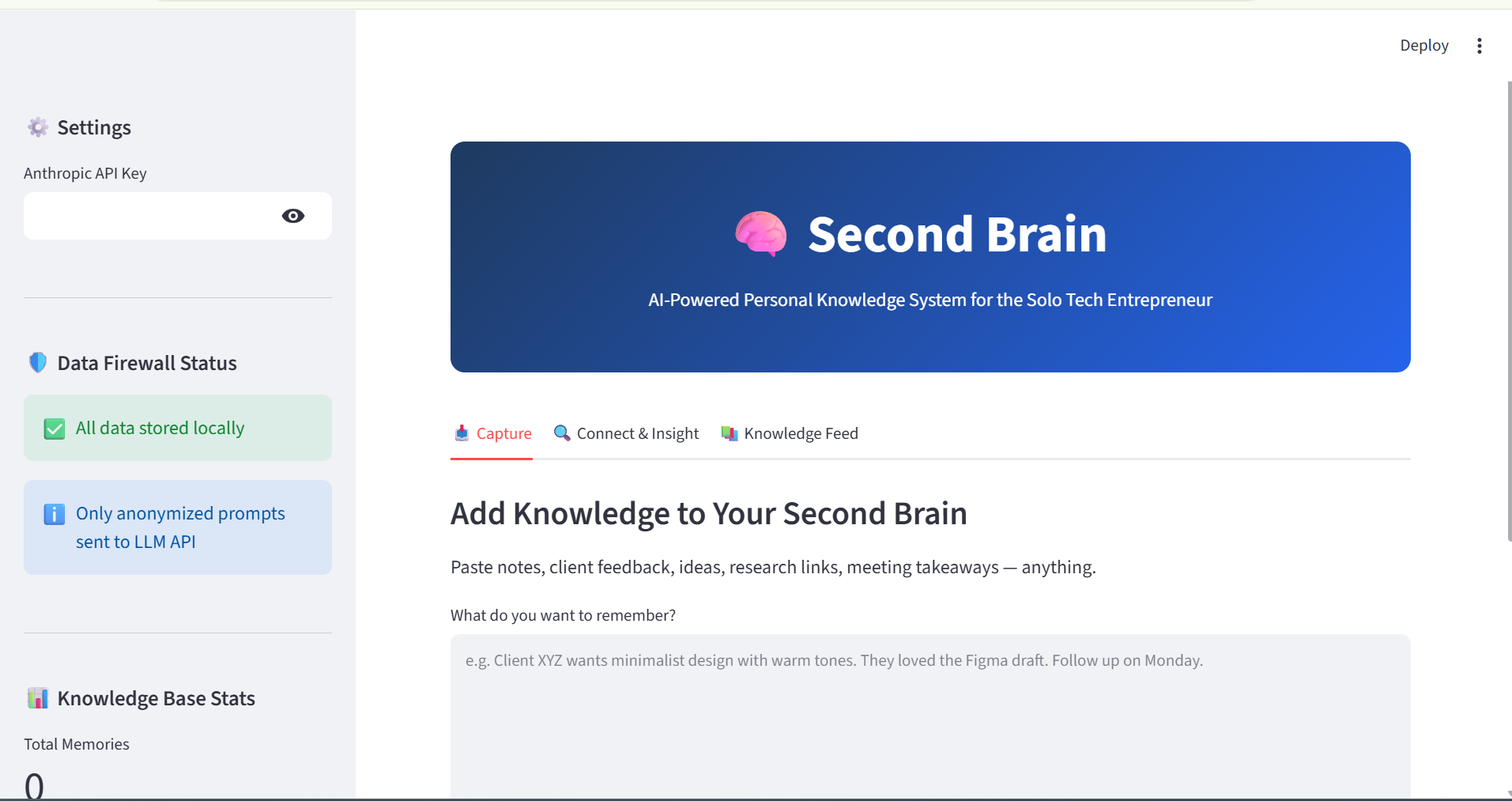
Second Brain is an AI-powered personal knowledge management system built around a specific user persona: a young solo tech entrepreneur who builds websites, does graphic design, video editing, and deploys AI agents for small businesses. It automatically captures notes, finds semantic connections between them, and synthesizes actionable insights — turning scattered information into compound intelligence.
How I built it
Second Brain runs on a three-agent CrewAI pipeline:
- Capture Agent: Takes any note and embeds it locally using sentence-transformers (all-MiniLM-L6-v2), storing it in a local ChromaDB vector database. No data leaves the user's device.
- Connection Agent: Performs semantic similarity search across stored memories, ranking results by relevance rather than relying on simple keyword matching.
- Insight Agent: Synthesizes connected memories into an actionable brief using Anthropic Claude (claude-sonnet-4-6), through a strict data firewall that only sends anonymized, summarized prompts — never raw personal notes.
The frontend is built with Streamlit, and the entire system is designed to be fully functional for capture and search even without an active API key, thanks to a built-in fallback mechanism.
Challenges I ran into
The biggest challenge was designing the data firewall correctly — making sure personal notes are never transmitted to an external API while still leveraging LLM intelligence for insight generation. I also had to solve a tricky bug where ChromaDB collections would lose sync across Streamlit reruns, which I fixed by implementing a single shared, persistent database client across all three agents. Testing the full pipeline as a first-time solo hackathon participant, while also managing my creative work for Dash and Dot, taught me a lot about debugging under time pressure.
Accomplishments that I'm proud of
I'm proud of building a working three-agent AI pipeline from scratch with no prior experience in multi-agent systems. The data firewall architecture — where personal knowledge stays fully local while still leveraging LLM intelligence — is a design decision I thought through carefully. I'm also proud of the graceful fallback system: even without an active Claude API key, the Insight Agent never crashes; it intelligently falls back to a local summary so the user is never left with a broken experience.
What I learned
I learned how vector embeddings and semantic similarity search genuinely surface connections that keyword search completely misses. I learned how to orchestrate multiple AI agents with CrewAI, debug shared state issues in Streamlit, and design responsible AI systems where ethics — including a Kohier four-lens ethics framework and NIST-aligned bias audit — is an architectural constraint, not an afterthought. Most importantly, I learned that building something specific for a real user beats building something generic every time.
What's next for Second Brain
Next steps include adding persistent multi-session memory, deploying the app so it's accessible beyond localhost, and expanding the Insight Agent to support multiple LLM providers as a built-in fallback option.

Log in or sign up for Devpost to join the conversation.