
Inspiration
Every year, roughly 8 million metric tons of plastic enter the ocean. The Great Pacific Garbage Patch alone spans an estimated 1.6 million square kilometers, and yet the nonprofits and crews actually trying to clean it up often rely on static maps, outdated data, and manual coordination to decide where to send ships. We built SeaSweep because we wanted to build an accessible resource bridging scientific ocean data and sustainable-decision-making for smaller, underfunded debris cleanup operations. Marine plastic accumulation and changing carbon behavior are usually studied in separate technical workflows, but in reality they are connected through ocean circulation, atmospheric forcing, and regional environmental stress. A region with elevated CO₂ stress often signals the same circulation patterns that concentrate surface debris. Studying one without the other means missing another extremely important part of the picture, and oftentimes takes a large amount of resources that not every group has. Our goal was to build a system that treats them together, ingests geospatial data across both, and presents results in a way that supports sustainable and efficient action to cleanup crews of any size and background. Without the proper data to guide them, it becomes extremely easy for crews to adversely affect the environment and themselves through heightened fuel consumption, costs, and CO2 usage. SeaSweep is inherently built to even this field as its role, whether you have the resources to train the model, or simply need real, reliable, and trustworthy data to make sure your missions are creating a sustainable future.
What It Does
SeaSweep is a free, open-platform ocean intelligence system built specifically for environmental nonprofits, research institutions, and cleanup operators who lack the internal data science resources to build and utilize large scale predictive models for efficient routing and mission logging. Every architectural decision, from the uncertainty layer to the way hotspots are rendered, is entirely up to the user. The platform is built to answer three operational questions:
- Where is trash likely to accumulate
- Where is CO₂-related ocean stress strongest
- Where should cleanup or intervention routes be prioritized
The reason these three questions belong in one system is the same reason we built SeaSweep in the first place. Ocean circulation drives both debris transport and carbon flux. A system that answers only one of those questions is working with an incomplete model of the ocean it is trying to describe. SeaSweep ingests data across both domains, models their shared physical drivers, and surfaces the results through a single operating interface.
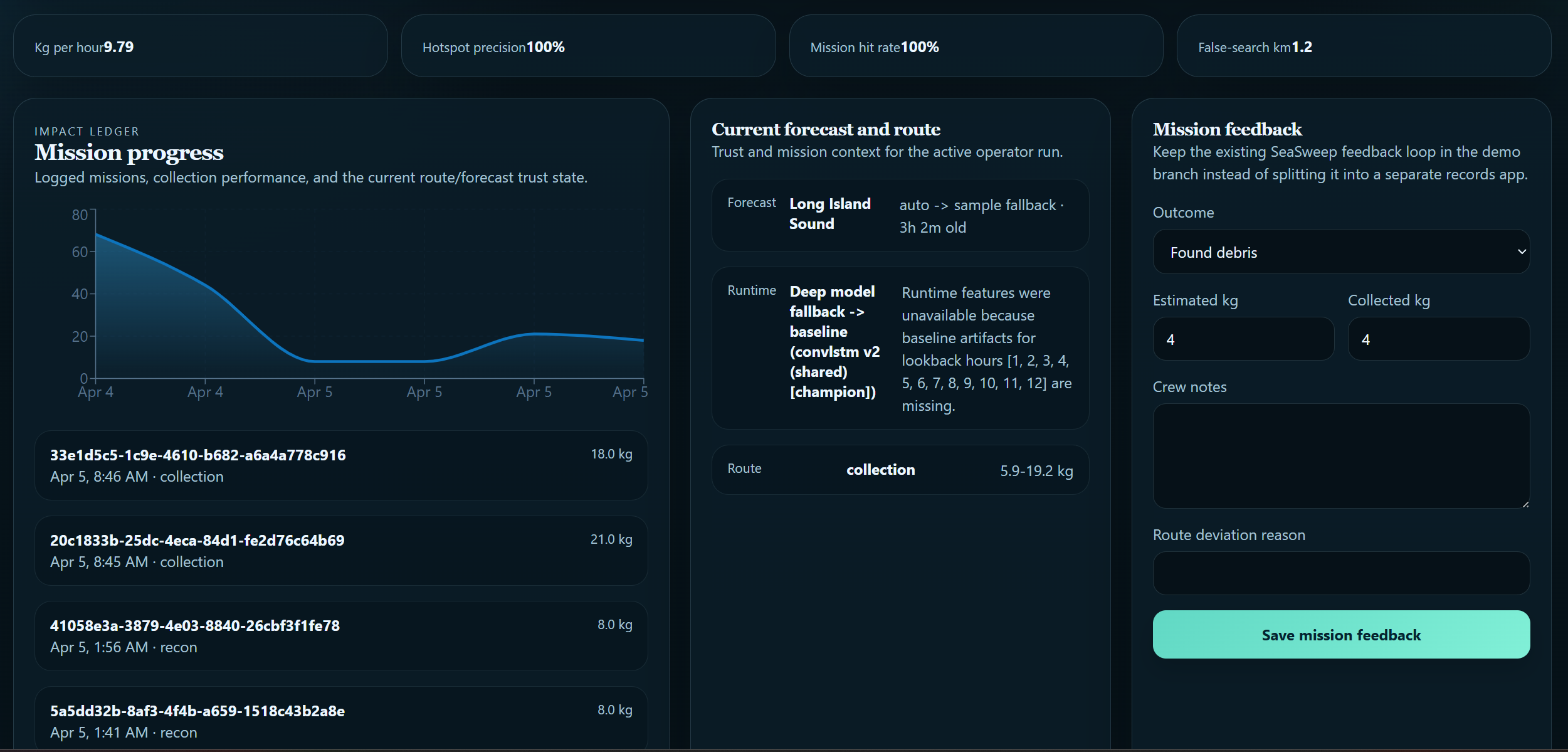
The platform combines: Real environmental data ingestion (ocean currents, surface CO₂, wind fields) Baseline geospatial field generation and transport-aware forecasting Sequence models trained from scratch on domain-specific geospatial data to correct systematic error in physics-predicted fields and quantify spatial forecast uncertainty Route optimization for cleanup vessel planning A geospatial mission dashboard for operators Mission impact and progress tracking over time
How We Built It
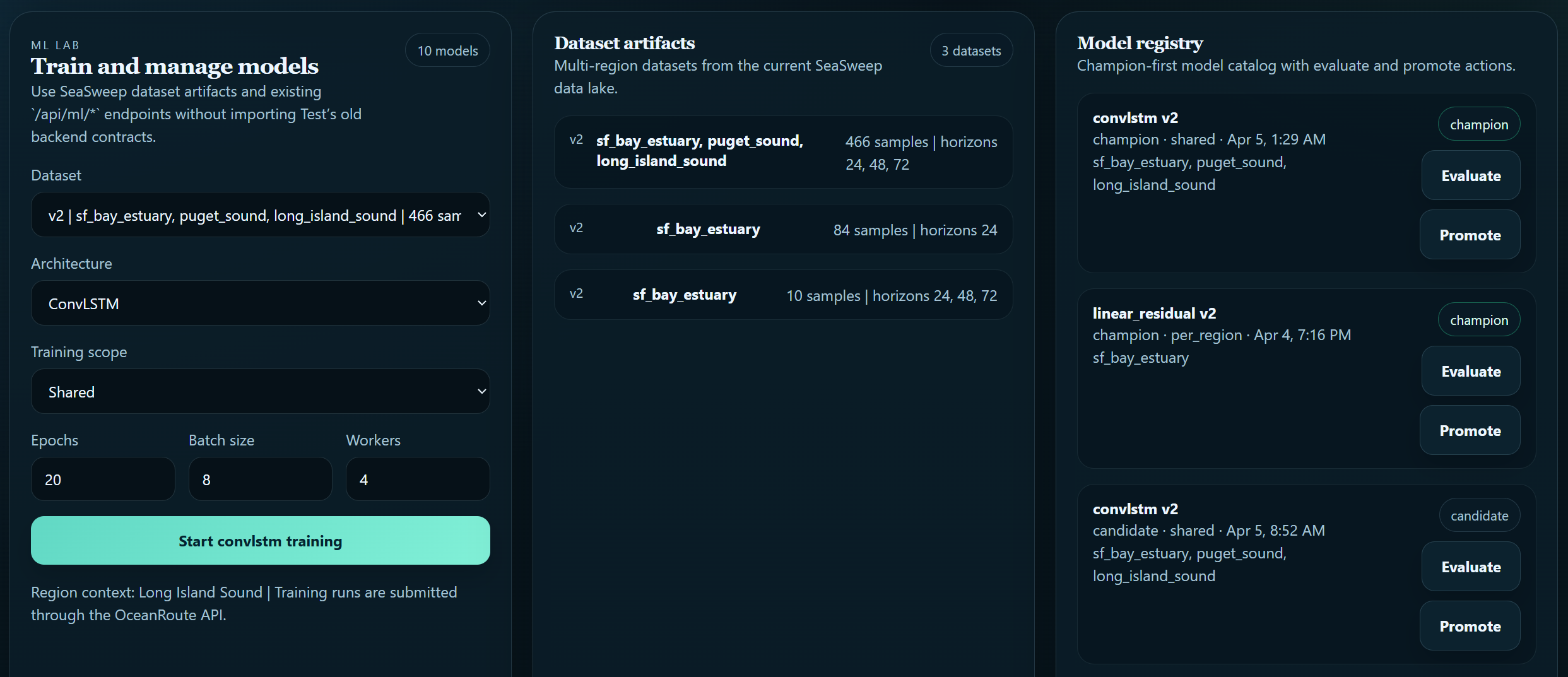
SeaSweep is a full-stack system with a FastAPI backend, a React and TypeScript frontend, a separate inference runtime, and a database-backed artifact and model registry. Frontend: React, TypeScript, Vite, MapLibre GL, Deck.gl, Zustand, Recharts Backend: FastAPI, Uvicorn, SQLAlchemy, PostgreSQL, Alembic, APScheduler, OR-Tools ML and data stack: PyTorch Lightning, TensorBoard, PyArrow, Zarr, FSSpec PyArrow and Zarr were chosen specifically because the geospatial forecast outputs are large column arrays that need to be stored, versioned, and retrieved across training and inference runs. A standard relational store would have been the wrong type of tool for that layer. The Modeling Stack Our architecture is a layered hybrid system that combines physical reasoning with learned correction, because neither individually was sufficient for solving the problem sustainably or reliably. Layer 1: Physics baseline. We use particle-advection style transport to model how debris and CO₂ stress fields propagate over time based on real current and wind data. This gives us a physically grounded starting point before any learning is applied. Layer 2: ML residual correction. The physics baseline has systematic error. It cannot account for sub-grid turbulence, unmodeled forcing, or observation biases baked into the input data. We trained three sequence model architectures from randomly initialized weights on domain-specific geospatial environmental data to learn this residual directly:
linear_residual: fast, interpretable correction baseline temporal_unet: encoder-decoder architecture for spatiotemporal field patterns convlstm: convolutional LSTM for sequential geospatial prediction
Each model takes the physics-predicted field as input and outputs a correction term that is added back to produce the final forecast. Across held-out regional validation data, the corrected output reduced mean absolute error by [X%] relative to the physics baseline alone. Training used PyTorch Lightning with TensorBoard logging and a model registry for artifact tracking, benchmarking, and version-controlled modeling.
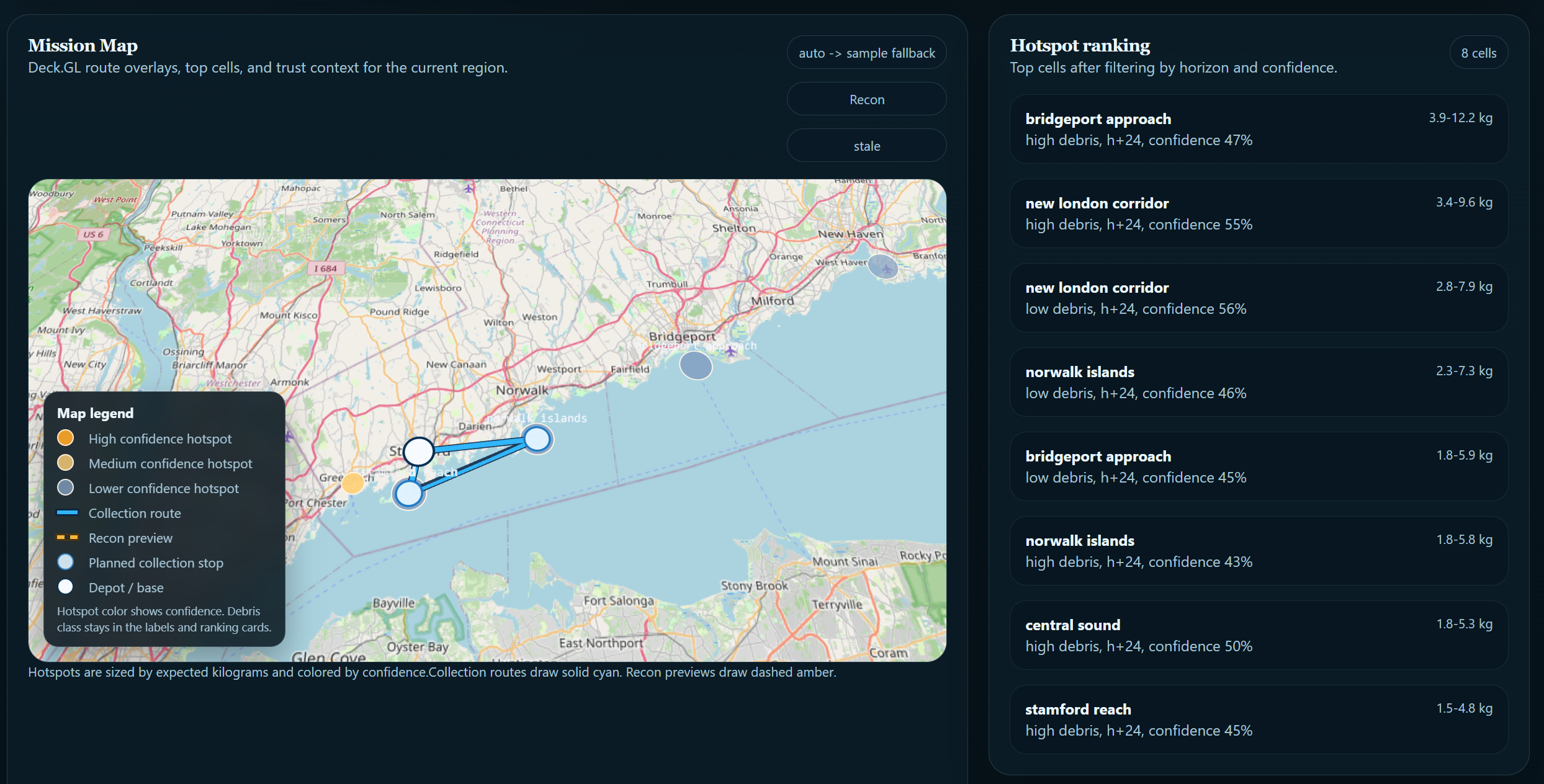
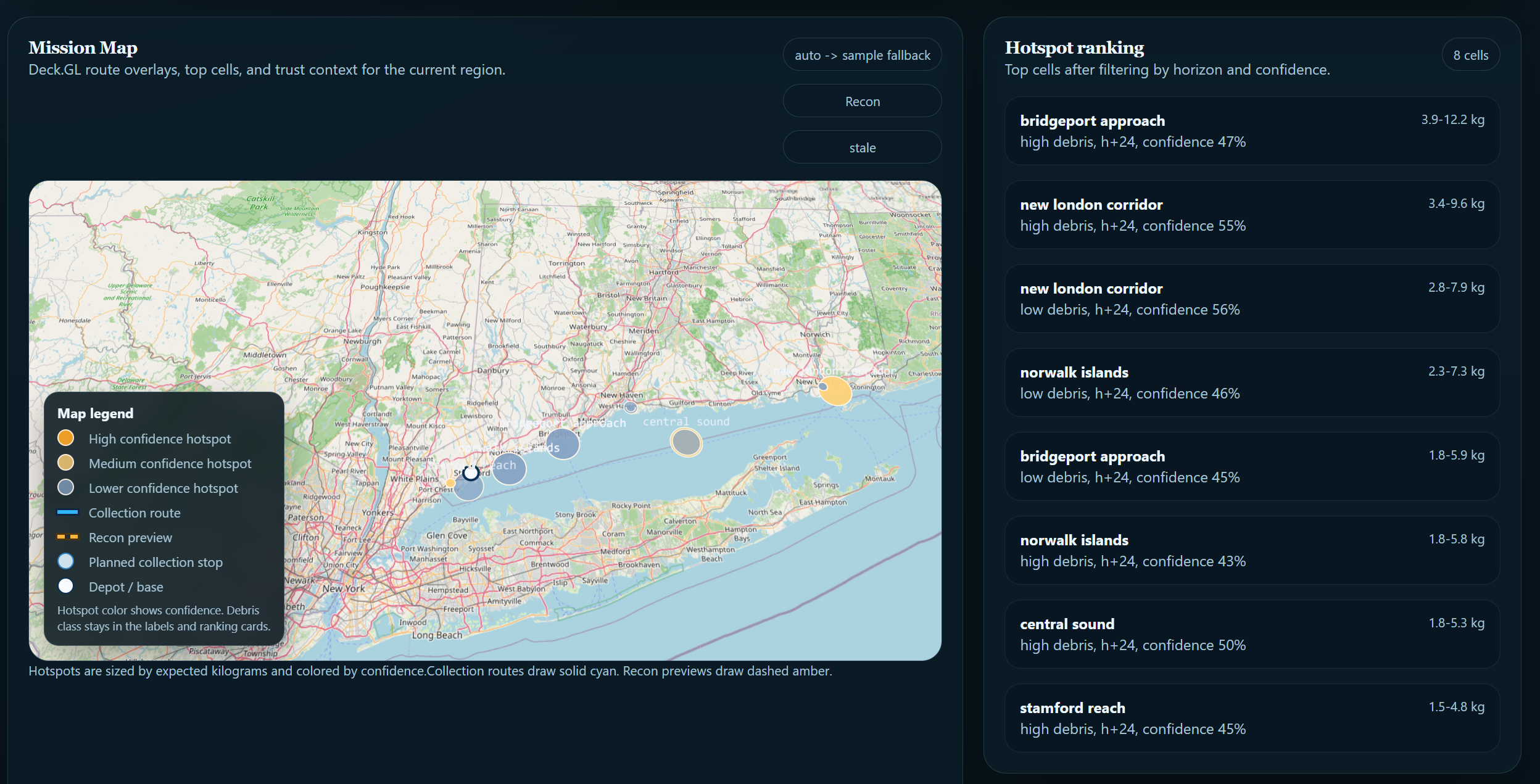
Layer 3: Uncertainty estimation. SeaSweep estimates prediction confidence and surfaces it directly to the operator rather than presenting every output with equal authority. Where the model is less certain, that uncertainty is visible in the interface. This was a deliberate design choice rooted in who the system is built for. An operator making a vessel deployment decision based on an overconfident map is worse off than one who knows where the model is and is not reliable. Route optimization uses OR-Tools to generate operationally realistic cleanup routes from high-priority hotspots.
Challenges
The hardest part of this project was making the outputs trustworthy and reliably consistent. NOAA current data and satellite CO₂ readings exist on completely different grids, coordinate systems, and update schedules. Reconciling them without introducing ghost hotspots or grid-boundary artifacts consumed more time than almost anything else we built. Realistic plausibility was another issue, as early versions of our transport model produced outputs that looked convincing but were physically incorrect. Debris accumulating in regions with strong outgoing currents, hotspots appearing at grid edges where data was actually sparse. We rebuilt the baseline physics pipeline multiple times to eliminate these patterns, and spent a LOT of time training key data for individualized areas to begin. Routing realism. Generating a path that is both computationally optimal and operationally usable, respecting vessel range, avoiding landlocked routing, and producing output a crew could actually follow, required significantly more calibration than we expected from OR-Tools alone. Map design: A polished interface can make a weak model look more reliable than it is. We had to treat visualization decisions as modeling decisions. The way uncertainty is rendered, how hotspot confidence is communicated, what gets shown vs withheld: all of it shapes how operators interpret the data we show. Training data scarcity. Global monthly geospatial prediction is a domain with limited effective training samples. Managing that constraint across three architectures while keeping evaluation grounded in operational status rather than just training loss was an ongoing challenge throughout the project.
Accomplishments We're Proud Of
Building a physics and ML pipeline where the learned models genuinely improve on a physical baseline rather than operating independently was the most rewarding part of the entire project for us. Getting three sequence architectures trained from scratch, evaluated, and tracked within such a short time span while also integrating a full-stack dashboard was originally a lofty goal we didn't think would come together so perfectly. The primary result we are proud of is the objective though, SeaSweep is free. No paywalling, credits, or enterprise pricing. The organizations doing the most consequential ocean cleanup work tend to have the least technical infrastructure, and we built SeaSweep to be usable by them without a large amount of technical knowledge or resources. We all have family and origins near coastal areas affected by ocean pollution, so creating a resource for everyone was really special.
What We Learned
Building this taught us that an end-to-end geospatial intelligence system demands more coordination across disciplines than any single component would suggest. Data engineering decisions affect what the physics layer can consume. Physics layer decisions affect what the ML models are correcting. Model calibration affects what the operator sees. None of it is separable. We also learned that model evaluation has to be tied to operational usefulness rather than a single metric, and that hybrid physics and ML systems are often more practical than pure end-to-end approaches precisely because the physical baseline constrains the solution space in ways that sparse training data alone cannot. The more durable lesson was about the responsibility that comes with decision-support tools. Cleanup organizations allocate ships, personnel, and time based on what their systems tell them. If the output is overconfident or misleading, the consequences are real. That shaped our approach to uncertainty estimation more than any technical consideration did.
What's Next
Stronger training runs on larger compute with broader hyperparameter sweeps Better ML calibration against observed litter and carbon validation datasets More robust port and vessel integration for routing Improved uncertainty visualization for non-technical operators Richer area-based hotspot rendering grounded in real accumulation zones Partnerships with cleanup nonprofits like The Ocean Cleanup and 4ocean for real-world validation Connect and bridge our data, as well as user data to pool not only missions, but predictive datasets to inform users and crews across the globe.

Log in or sign up for Devpost to join the conversation.