-
-
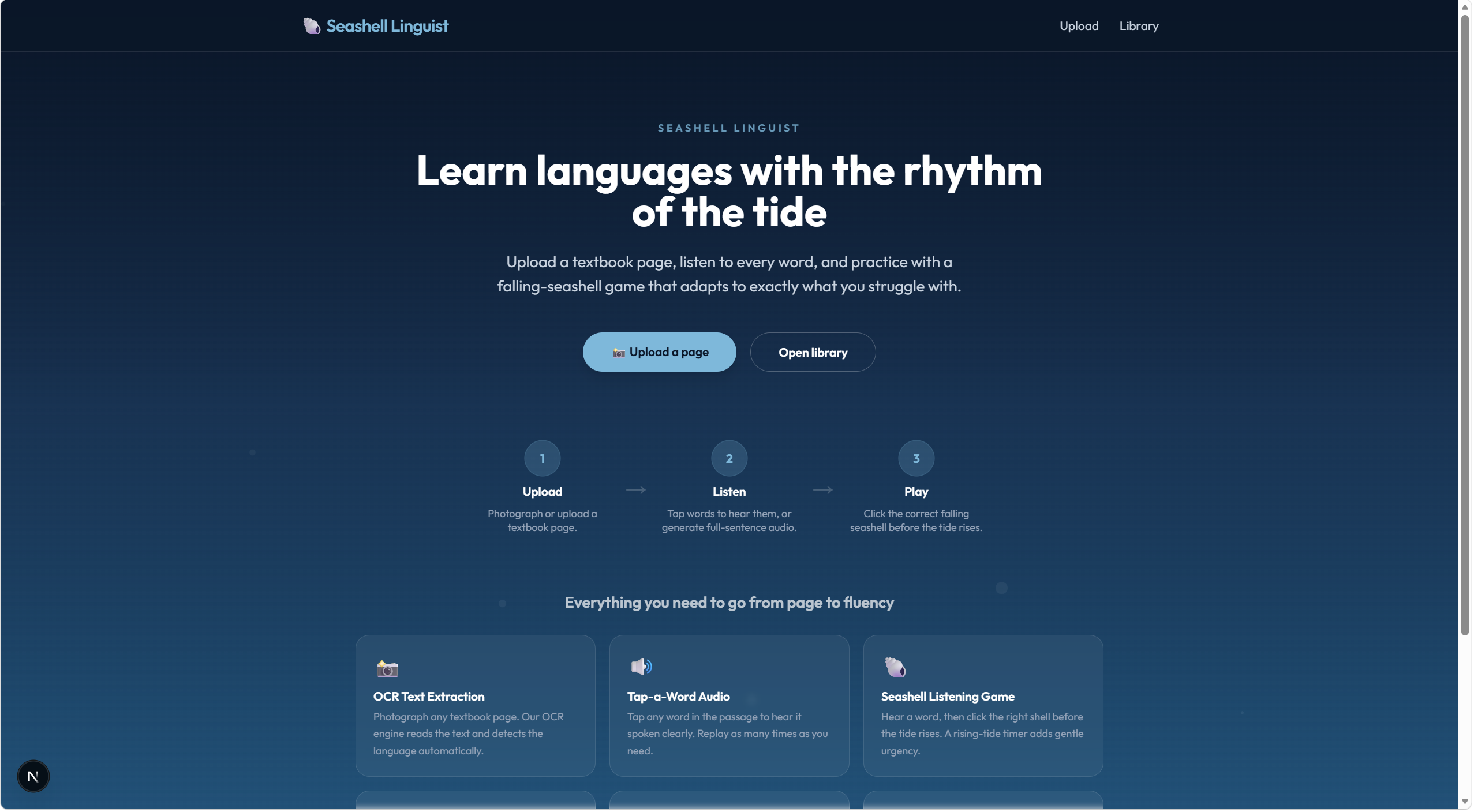
Interface
Inspiration Language learning apps are built around curated, pre-translated content — but real fluency comes from engaging with the world as it actually is. We wanted to build something that meets learners where they are: a restaurant menu in Tokyo, a street sign in Lisbon, a novel picked up at a local bookstore. The idea was simple — point your phone at any text, and instantly turn it into a study session. The ocean theme came naturally: you're always picking up new shells, building a collection one word at a time.
What it does Seashell Linguist transforms a photo of printed text into a full language-learning experience in three steps:
Scan — Upload a photo of any printed text. Gemini Vision OCR extracts the text and automatically detects the language, no configuration needed. Listen — On the reader page, tap any word or sentence to hear it spoken aloud by ElevenLabs' multilingual TTS engine. Perfect for picking up pronunciation from authentic material. Play — Jump into the Seashell Game. A word from your passage is read aloud, and four labeled shells fall down the screen. Pick the right one before the tide rises and swallows the board. Wrong-answer shells aren't random — they're semantically similar words, so every distractor is a genuine challenge. The app tracks your accuracy per word over time and automatically weights harder words to appear more often, creating a personalized review loop without any manual flashcard setup.
How we built it The stack is Next.js 15 with the App Router, TypeScript throughout, and Tailwind CSS for styling. The pipeline chains three AI services together:
Google Gemini handles both OCR (gemini-1.5-flash for multimodal image understanding) and semantic embeddings (text-embedding-004) for vocabulary vectors. ElevenLabs (eleven_multilingual_v2) generates natural-sounding audio for any word or sentence in any language. MongoDB stores everything — passages, user profiles, audio cache, and 768-dimensional vocabulary vectors — and MongoDB Atlas $vectorSearch powers the semantic distractor retrieval at game time. When a game round starts, the correct word is embedded in real time, and a vector search finds the closest neighbors in the passage's vocabulary space. Those neighbors become the wrong-answer shells, ensuring the distractors are always semantically plausible rather than noise. We built a cosine-similarity fallback so the game works on local MongoDB too.
Challenges we ran into Getting distractors right was harder than expected. Pure random wrong answers made the game trivial. We needed wrong answers that are close enough to be confusing but not so close that the question becomes unfair. Tuning the vector search parameters — number of candidates, exclusion filters, fallback fill logic — took several iterations to feel right.
Audio latency was a real UX problem early on. Calling ElevenLabs on every tap added a 1–2 second delay that broke the flow. We solved it with a MongoDB-backed audio cache keyed by (text, voiceId) — the first play generates and stores the audio, every subsequent tap is instant.
Dimension mismatch hit us when switching embedding providers mid-development. Stored vectors and the Atlas index had to be regenerated after any model change, which meant being disciplined about treating the vector index as a versioned artifact.
Accomplishments that we're proud of The thing we're most proud of is that the entire pipeline — photo to adaptive vocabulary game — is zero-config for content. There's no labeling, no translation, no manual word list. Every language Gemini can read and ElevenLabs can speak works automatically. We tested it on Chinese, Japanese, Spanish, French, and German without writing a single language-specific line of code.
We're also proud of the adaptive difficulty system. A simple exponential moving average (α = 0.25) over correct/incorrect answers turns a static word list into a living study deck that actually responds to what you struggle with.
What we learned We learned how powerful it is to combine a general-purpose vision model with a vector database — the combination lets you go from raw image pixels to semantically structured vocabulary without any hand-crafted NLP pipeline. We also learned to treat embeddings as data: model changes are breaking schema changes, and they need to be managed like migrations.
On the product side, we learned that game feel matters as much as the AI. The tide timer, the falling shells, the rising water animation — these aren't decorative. They create the time pressure that makes the game engaging rather than just another flashcard drill.
What's next for Seashell Linguist Spaced repetition scheduling — surface words at the scientifically optimal review interval using the stored difficulty scores. Multiplayer mode — race a friend through the same passage, competing on the same falling shells in real time. Camera capture on mobile — skip the upload step entirely; point, snap, and start studying in one tap. Progress dashboard — visualize vocabulary growth, accuracy trends, and which words are still giving you trouble across all your uploaded passages. Sentence-level games — expand beyond single words to test comprehension of full phrases and grammar patterns.

Log in or sign up for Devpost to join the conversation.