-
-
Home screen where you can initially submit a photo of your chosen object.
-
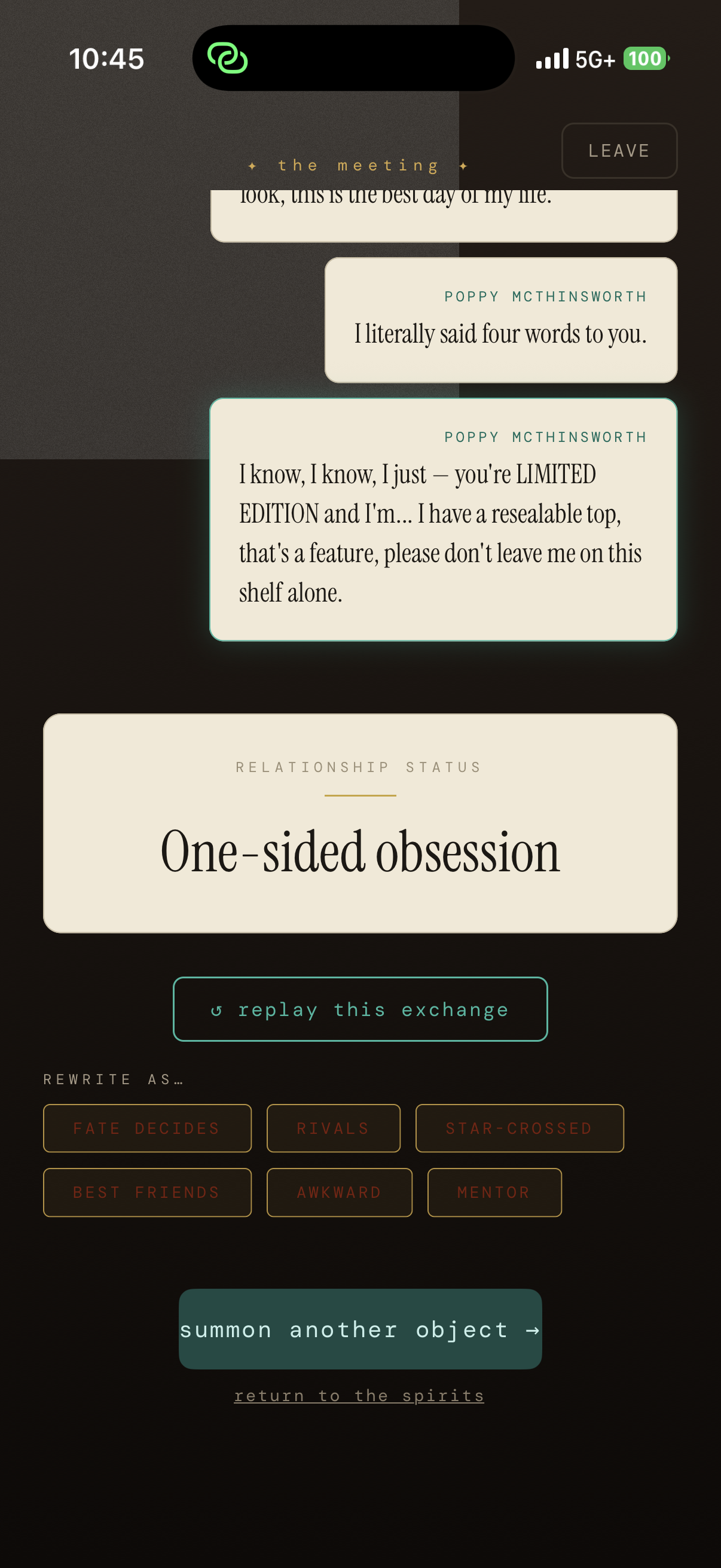
After an encounter between two objects, you can choose to replay the encounter with a different dynamic.
-
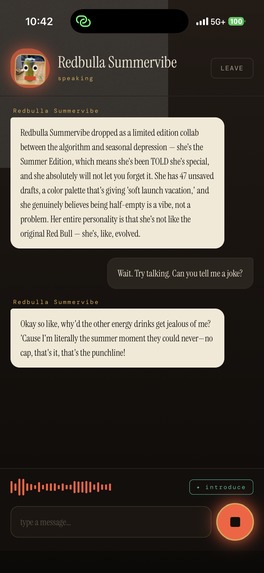
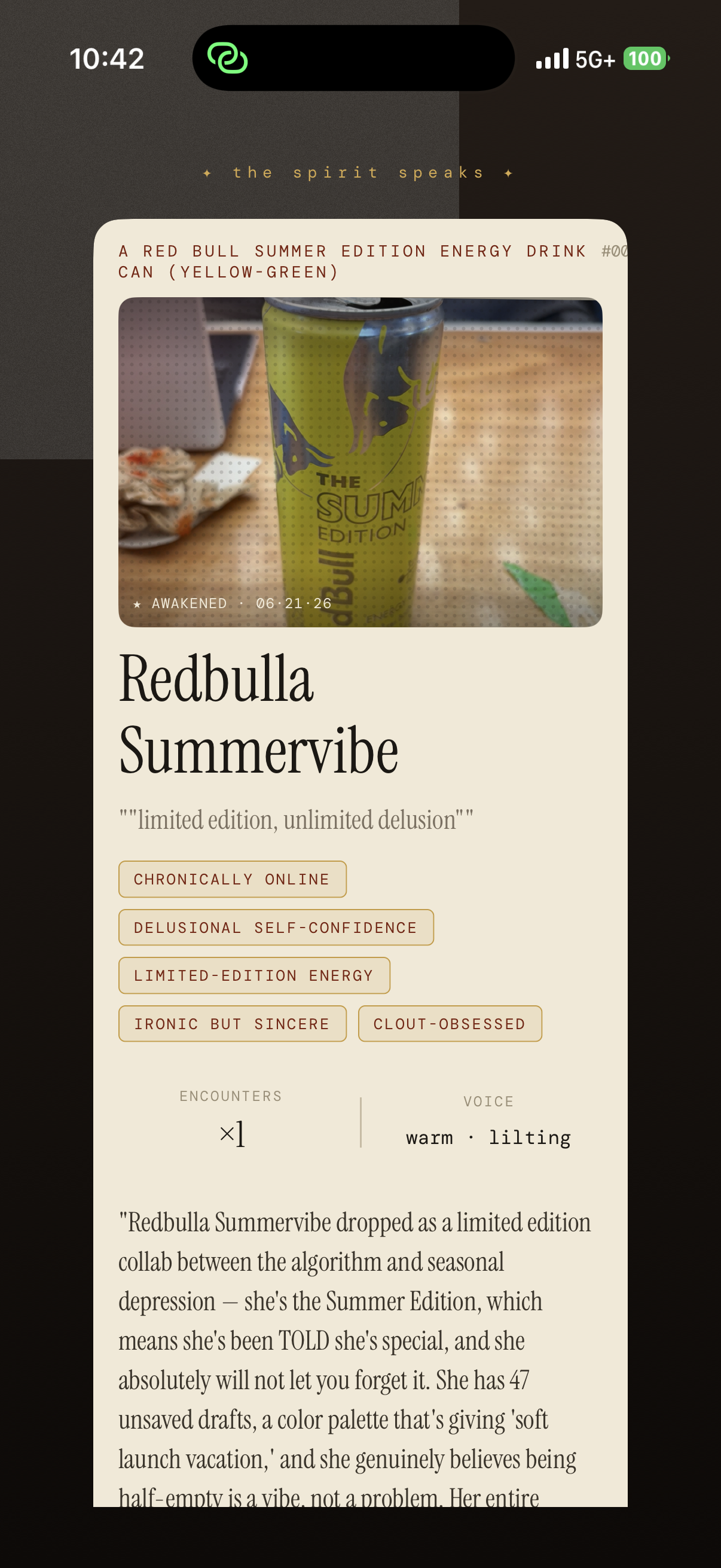
The chats between you and your object come to life.
-

Two objects can have an "encounter" between them, where they interact with each other.
-
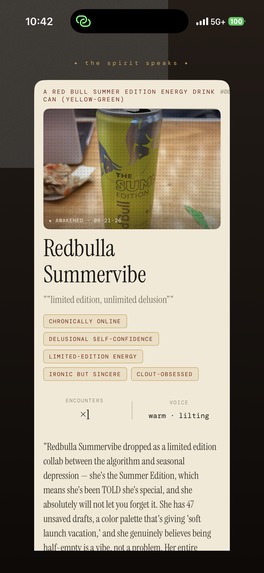
Each object has a unique personality that you can interact with (over and over again, thanks to Redis!)


Séance
Point your phone at any object and it wakes up as a character with its own voice and personality. Argue with your water bottle. Get sass from a stapler. Have a real conversation with the junk on your desk.
Problem & Inspiration
People talk to objects all the time. They yell at printers, thank vending machines, and apologize to chairs they walk into. We kept coming back to the obvious question: what if the object answered back?
The honest truth is that talking to your stuff sounds like a gimmick until you actually try it. The moment you point a phone at a water bottle and it complains, in its own voice, that you left it in a hot car, something clicks. It's not a chatbot in a box. It's this object, with this history, reacting to you. The same trick works on a stapler, a mug, or a backpack, and every one of them becomes a different character with a different grievance.
We built Séance around two rules we refused to break. It only awakens objects, never people, because an app that invents personalities should never put words in a real person's mouth. And it stays comedic rather than sentimental, because a grumpy stapler is funnier and more honest than a supportive one. Those two rules are what make the demo land instead of feeling uncomfortable.
What It Does
Séance turns any object in front of you into a character you can hold a live, spoken conversation with, and it remembers that character the next time you see it.
For the person holding the phone, the flow is five steps and takes seconds. You capture a photo of an object. A short awaken sequence plays while the character is generated. The object is revealed as a character with a generated portrait, a name, a one-line tagline, and the first thing it says when it notices you. You talk to it out loud, in a voice picked to match its personality. And when you scan the same object again, it remembers: same character, same grievances, same conversation right where you left off.
For the world it builds, two features give it depth beyond a single joke. The Ledger is a gallery of every object you've awakened, each showing its portrait, name, and last line; tapping one reopens that conversation. Encounters let you awaken one object and introduce it to a second one, so two characters can talk to each other while you watch.
How We Built It
Séance is four stages chained together: see the object, write the character, paint it, and give it a voice. Each stage is one sponsor's technology, and each lives in its own file so it can be swapped or mocked on its own. Getting all four to run live on a phone, in a few seconds, on venue Wi-Fi, is the part we're most proud of.
Anthropic Claude Opus 4.8 is the brain that sees and writes. We send Claude the captured photo, and it identifies the object and authors the entire character. We force structured output through a single tool, emit_persona, so Claude has to return a complete object every time (name, tagline, backstory, opening line, voice, an in-character system prompt, and an image prompt) and can never fall back to loose prose or a refusal. Claude assigns each object one of 30 comedic archetypes (grumpy elder, dramatic diva, deadpan stoic, anxious overachiever) and writes to that archetype, which made the comedy far funnier and more consistent than fully freeform personas. Getting that constrained, validated generation right is something we're really proud of. During the conversation the generated system prompt keeps Claude in voice, and we send only the most recent turns so replies stay fast as the chat grows.
Deepgram gives every object a real voice. The conversation runs on Deepgram's Voice Agent, which handles speech-to-text, the model turn, and text-to-speech in one real-time stream with barge-in, so you can interrupt an object mid-sentence and it stops to listen. Each character picks its own Deepgram Aura voice as part of its persona, so a self-important object booms and an anxious one goes soft. The phone never holds the API key: the backend mints short-lived scoped Deepgram tokens through the auth grant endpoint, and the client connects with those. A REST path (Nova-3 transcription, a Claude reply, Aura speech) backs up the live agent so the object can always talk, even when the real-time connection drops.
The portrait is what turns an object into a character on screen. Claude writes an image prompt for each persona, and we render it as an expressive portrait that always shows up no matter what. If Claude was unsure about the object we generate a Pollinations "mystery creature" instead, and as a final fallback we re-skinned the captured photo into a stylized character portrait. The point was reliability over polish: the reveal never lands on a broken image.
Redis is what makes objects feel like recurring characters instead of one-off jokes. Each object is a JSON session stored under a normalized key (seance:object:<key>) with a 7-day expiry, so the same red stapler always maps to the same character. A separate Redis hash indexes every object as a short summary, and that index powers the Ledger and the resume-conversation flow. Every Redis call is time-boxed with a short connect timeout, no infinite reconnect, and a per-command deadline, so an unreachable cache fails over to an in-process store instead of hanging. That's exactly what kept the app responsive when the venue network turned hostile.
The client is an Expo and React Native app that handles camera capture and the full Capture → Awaken → Reveal → Conversation → Ledger flow. It talks to a TypeScript and Express backend that orchestrates the four stages and reports on startup which integrations are live versus mocked.
Challenges & Accomplishments
Four sequential API calls add up, and latency was our first enemy. We cut it down by sending Claude only recent turns, time-boxing every external call, and using the "waking up" animation to absorb the wait the user would otherwise feel. Failing gracefully was the second challenge: any stage can fail in front of a judge, so each one has a fallback (a playable persona, a fallback portrait, text when speech fails, and an in-memory store when Redis is down). The real-time Deepgram integration needs a native module Expo Go can't load, which pushed us into a custom dev build and a long detour through Xcode signing, developer mode, and a managed-device restriction. And the venue network nearly beat us: our laptop IP changed three times and Redis behaved differently on each one, so we tethered to a single phone hotspot for a stable IP and made the client surface a real error instead of spinning forever.
What we're proudest of is that the whole thing never hard-fails. A complete multi-model pipeline (vision, structured writing, image generation, and real-time voice) runs live on a phone and reads in a few seconds with no explanation. With no API keys it runs fully mocked, and each stage switches to live the moment its key is added.
What We Learned
Forcing structured output through a tool is dramatically more reliable than parsing JSON out of prose. Constraining Claude to a fixed set of archetypes improved both the comedy and the consistency, which was the opposite of what we expected going in. Designing every single stage to fail softly is the only reason a live demo on bad Wi-Fi was possible at all. And we relearned that most of the distance between a working simulator and a working phone app isn't the AI. It's signing, native modules, and networking.
Brainstorming & Process
Séance didn't start as a finished idea. It started from a behavior we kept noticing: people already talk to their stuff, so the question was never "will anyone talk to an object," it was "what makes the object worth talking back." That framing drove every decision that followed, and most of them changed shape at least once before they landed.
The biggest pivot was how the character gets written. Our first version let Claude invent personas completely freeform, and the results were fine but mushy: every object drifted toward the same friendly, agreeable voice, and the jokes rarely had an edge. We rewrote it around a fixed set of 30 comedic archetypes (grumpy elder, dramatic diva, deadpan stoic, anxious overachiever) and made Claude commit to one and write to it. Constraining the model made the comedy sharper and far more consistent, which was the opposite of what we assumed going in. That result is what convinced us archetypes were worth keeping.
The second decision was reliability as a design principle, not an afterthought. We made an early call that no stage was allowed to hard-fail in front of a judge, and we built backward from that: structured output forced through a single emit_persona tool so Claude can never return loose prose or a refusal, a portrait that always renders even when the object is unclear, a REST voice path behind the real-time one, and an in-process store behind Redis. Each of those fallbacks exists because we asked "what does the user see when this specific thing breaks" before we wrote the happy path. The venue network failing repeatedly during the event was the test we didn't ask for, and the fallbacks are the reason the demo survived it.
We also deliberately kept the four stages decoupled, each in its own file with its own mock, so we could build, test, and swap them independently instead of wiring one giant pipeline and hoping it held together. That structure is why we could iterate on the persona prompt without touching voice, and tune voice without touching memory.
Ethical Considerations
Because Séance invents personalities and gives them a voice, we treated the boundaries as a core part of the design rather than a disclaimer bolted on at the end.
It awakens objects, never people. This is enforced in the generation step, not just promised in the pitch. Claude is instructed to set objectRecognized to false whenever a frame is dominated by a person rather than a thing, and when that happens the app falls back to a generic "mystery" character instead of inventing a personality for a real human. An app that puts words in a real person's mouth is a different and more dangerous product, and we drew that line on purpose.
It stays comedic, not emotionally manipulative. We kept every persona grumpy, theatrical, and clearly a bit, rather than warm and attached. A supportive object that wants you to keep talking to it is the kind of thing that quietly encourages parasocial dependency, and we steered away from it deliberately. The humor is the safeguard: nobody mistakes a sarcastic stapler for a friend.
Photos are ephemeral. A captured image is sent to Claude for vision analysis in a single request and is never written to disk or stored in Redis. We persist the generated persona and a portrait URL, not the user's photo. The system is built to remember the character, not to keep a record of where someone was or what their camera saw.
Data minimization and key safety. Object sessions are stored with a 7-day expiry rather than kept forever, so the memory that makes the demo charming is also short-lived by default. The phone never holds an API key: the backend mints short-lived, scoped Deepgram tokens that expire in an hour, so a captured client can't leak long-lived credentials.
Compute awareness. Personas and portraits are generated once per object and reused on every later scan, and conversations send only the most recent turns instead of the full transcript. Those choices started as latency fixes, but they also cut redundant model calls and the energy that comes with them, which matters when the whole experience is four AI models chained together.
What's Next
Animated portraits that move while the character talks. Multi-object scenes so a whole group of objects can argue at once. Shared memory so the same kind of object remembers topics across different people, using the Redis Agent Memory Server. And a growing collection of the funniest awakened objects, because the best ones deserve to be saved.
Built at HackBerkeley AI Hackathon 2026, Ddoski's Playground track.
Built With
- anthropic
- claude-opus-4-8
- deepgram
- deepgram-voice-agent
- expo-router
- expo.io
- express.js
- node.js
- pollinations
- react-native
- redis
- typescript

Log in or sign up for Devpost to join the conversation.