-
-
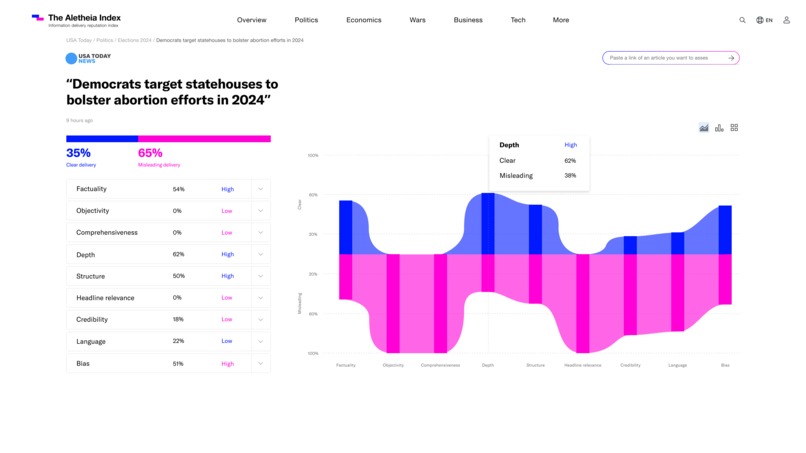
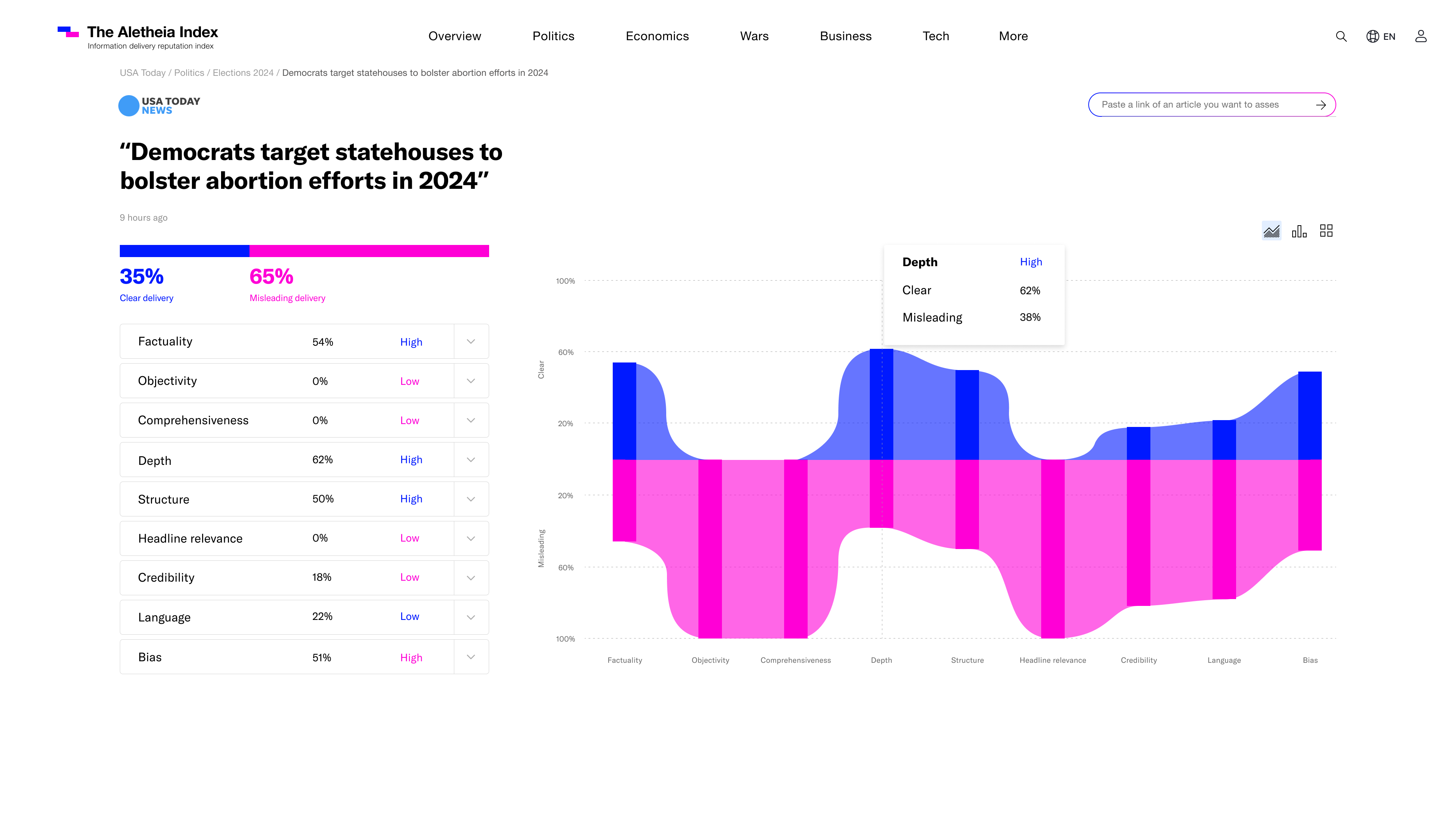
The Aletheia Index article view - breakdown of the params analysis of trust and mislead of the delivery of information. with overall score.
-
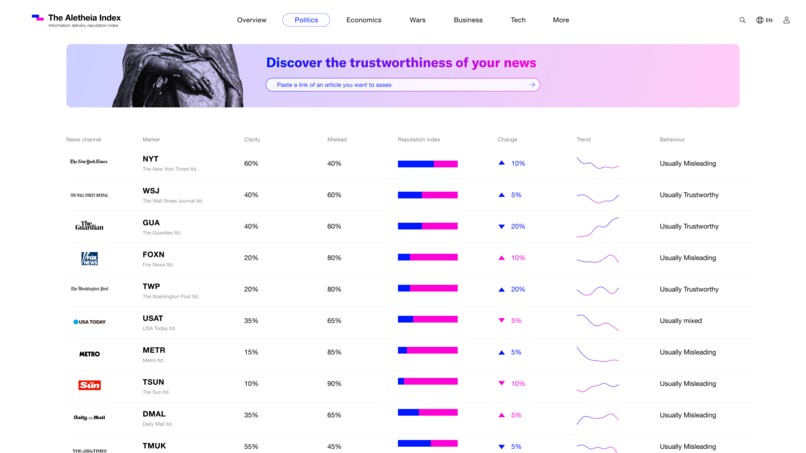
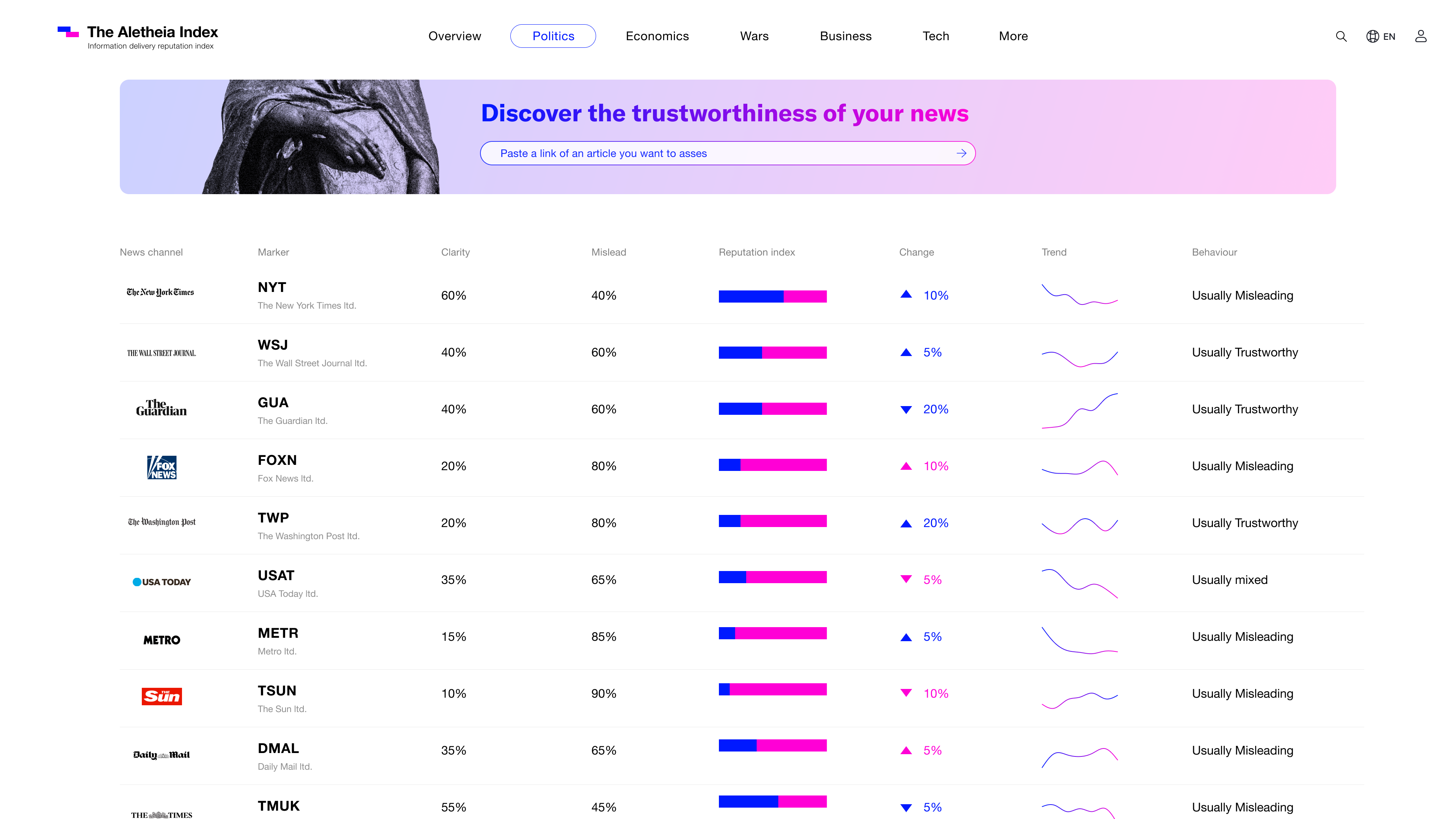
The Aletheia Index Section view - Overtime behavior and reputation measure of the entire news outlet (based on many articles analysis).
-
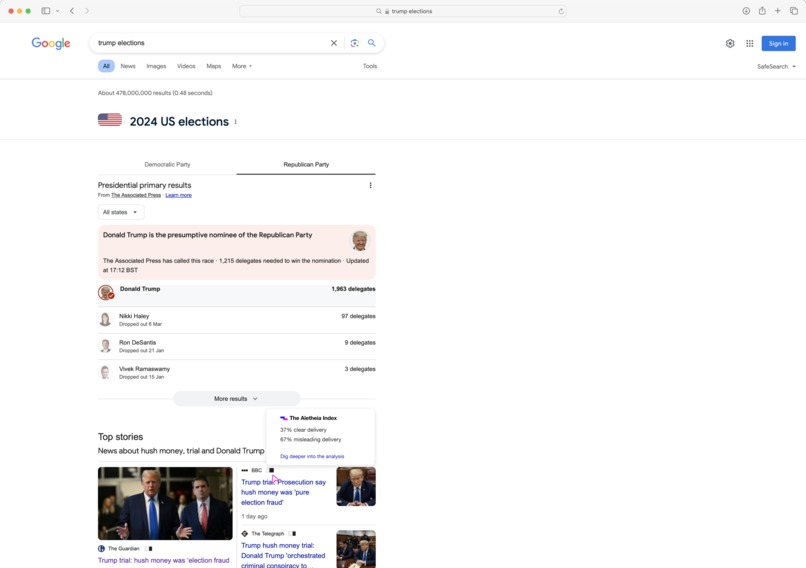
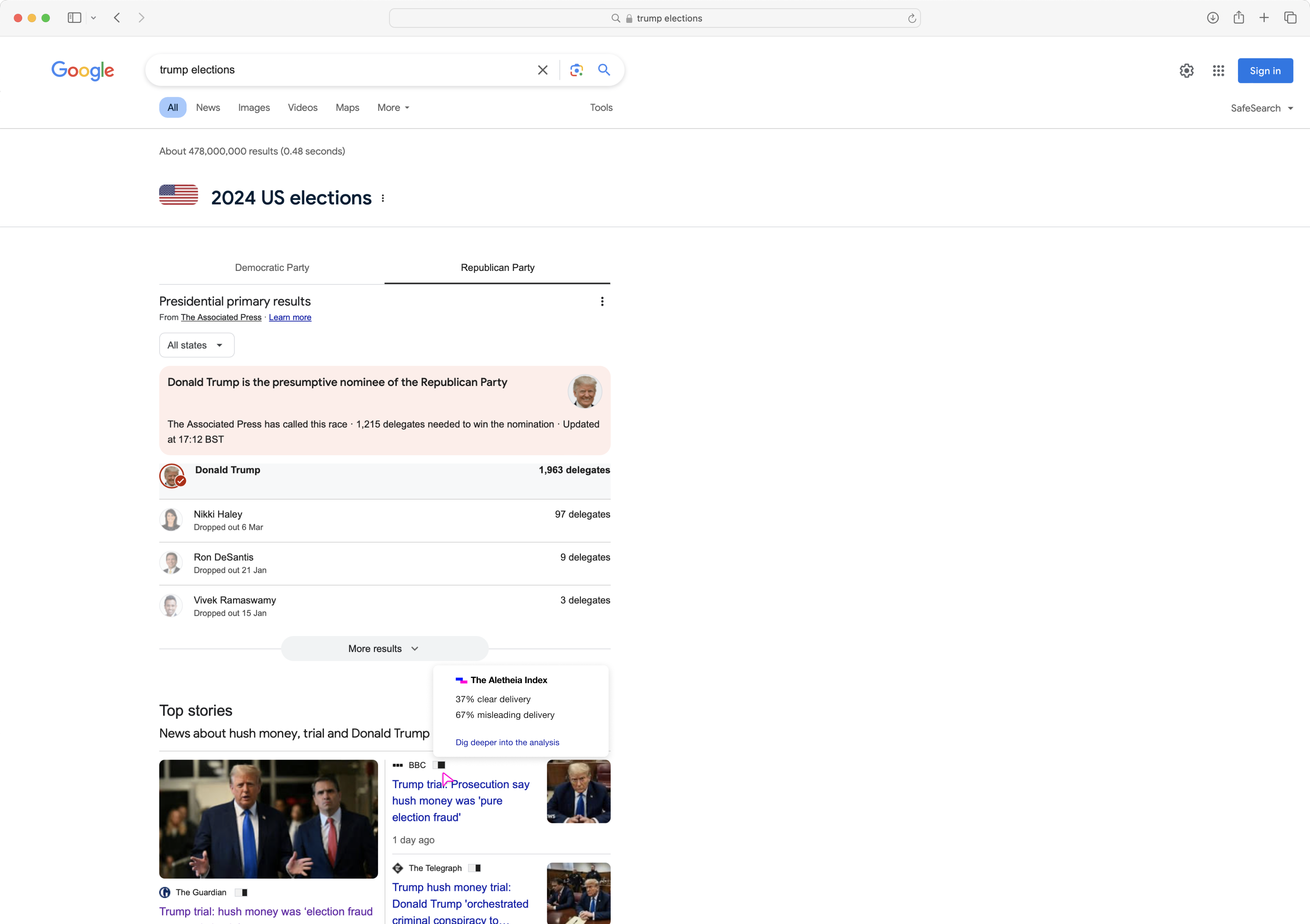
The Aletheia Index Integrated view of information measure in search of information.
Inspiration
Have you ever heard the same story but told in a different tone? Using different words? And emphasizing other parts of the storyline? Did it make you draw a different picture in your head of what happened? Was your opinion formed distinctly differently based on the various story versions?
Well, that’s misinformation for you. Same piece of data delivered in a different way. Misinformation happens when meaning is inferred from the layer of delivery added on top of the information, whether real or fabricated.
Looking at worldly events, we see how skewed information influences decision making and turns into actions that shape reality. How the growing scale of false narratives, results in rejection of accurate information and distrust in reliable sources. In a world of overload, we remain powerless facing the constant flow of information in every corner of our lives. And on the other hand, with no agreed accountability mechanisms as to the trust of the information we spread and consume.
This inspired us to form The Aletheia Index project.
What it does
A platform to measure mislead and misinformation coming from official media news channels.
The Aletheia index exposes (the code functionality) and visualizes (the UI app platform) the intent behind media outlets information delivery, by analyzing the metadata around the information instead of trying to evaluate and fact check it.
While many misinformation platforms tackle the content news channels spread (is it real, fake, AI generated, based on facts, and so on) and try to place the media outlet on a political spectrum map, The Aletheia Index doesn’t try to take the role of the “judge and jury” when it comes to the content. We assume a reality where news outlets have the liberty to spread whatever information they find relevant according to their standards and views. What interests us is how they choose to do it. The way information is delivered reflects the news media intent and goal, it is the heart of misinformation and mislead of perception. The language the article uses, its presented points of view (wide vs targeted), its semantic structure, etc.
The Aletheia Index aims to empower the individual information consumer (and potential spreader) with the knowledge and tools to apply criticality to the information they consume. Track the media behavior in a tangible way to assess its intent and create a space for accountability in the information realm.
The Aletheia index is essentially an information value market, and its parameters are the mislead and clarity of the information delivery. Which reflects the value of the media outlet in the public space.
How we built it
Programming Language: Python Web Framework: Flask
Libraries and Frameworks: [1] Scrapy: An open-source and collaborative web crawling framework for Python, used here to scrape and extract data from web pages. [2] tldextract: Extracts parts from a domain name to obtain the second-level domain and top-level domain, useful for cleanly separating the platform name from a URL. [3] spaCy: A library for advanced Natural Language Processing in Python, used for tokenization, lemmatization, and text preprocessing. [4] SciPy: Used here for its sparse matrix functionality to handle data structures efficiently. [5] NumPy: Essential for handling large arrays and matrices of numerical data. [6] Pandas: Provides high-performance, easy-to-use data structures and data analysis tools. [7] TextBlob: Simplifies text processing in Python, used for sentiment analysis. [8] scikit-learn: Utilized for machine learning tasks such as feature extraction with TF-IDF and topic modeling with LDA. [9] gensim: Used for unsupervised topic modeling and natural language processing using modern statistical machine learning. [10] textstat: A library to help extract statistical information from texts, used here to determine readability scores.
APIs and Models: [1] spaCy's English Model (en_core_web_sm): A small-sized model for basic NLP tasks. Data Handling and Serialization: [2] Google Cloud AI Platform & Google Cloud Prediction Service Client. [3]Vertex AI Auto ML regression[For Model training with Tabular dataset]
Challenges we ran into
The biggest challenge was to define the features pool and test to assign the right weight to each feature. Another challenge was integrating APLs from Google Cloud, we hadn’t realized at the beginning that it was not accessible in the UK, so in our project, for the feature extraction, we could use more API from Gemini, but because of the limitation, we haven’t got any chance to use it more.
Accomplishments that we're proud of
That it works!!!
Feature definition: We succeeded in pinpointing through machine models the human understanding the processing of linguistic and content information. By translating metaphysical parameters like objectivity and bias to tangible counts of adjectives used in a text and the sentiment output from the language(as an example). Integration: The combination of different processing models together for one unified analysis was a pleasant success that produced the holistic view of the hypothesized outcome score of mislead.
The first hypothesis proved itself - the analysis of the delivery of information is indeed more misleading and uses less clear linguistic delivery methods in partisan media outlets (with disregard their political spectrum position). Used language and specifically adjectives heighten mislead and contribute to misinformation greater than parameters such as facts and established sources.
What we learned
We have learned how to interpret Google Cloud AI APIs into the project, and are getting familiar with the Vertex model training process and model deployment.
Through defining the params of the features of the individual article we also learned how to improve them and connect the logic to outside processing of information. This understanding will help us in the next steps of refining the params and making them more accurate and complete (by default more trustworthy as a standard).
What's next for The Aletheia Index
We aim to keep refining the analysis of the information delivery metadata to create a professional and industry level trustworthy index. We strive for in depth collaborations with experts in the field of journalist ethics and code of standards, NLP and data/ML scientists and are reaching to stakeholders for these bridges. We intend to expand the index from singular articles analysis to the sections they reside in and eventually the entire newspaper, in order to create a tangible identity of the media body and track its behavior.
From the technical POV, we want to train the model with more data, test the importance of the features we selected and get the accurate weight for each param when calculating the overall score. For the demo building - a complete e2e scenario starting from the refined params to the overall score. And ensure a smooth interaction between the FE and BE.


Log in or sign up for Devpost to join the conversation.