-
-
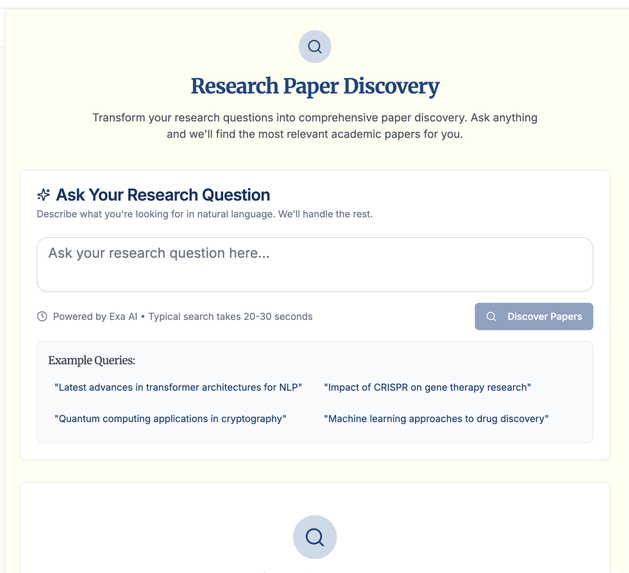
Research Paper discovery via Exa AI
-
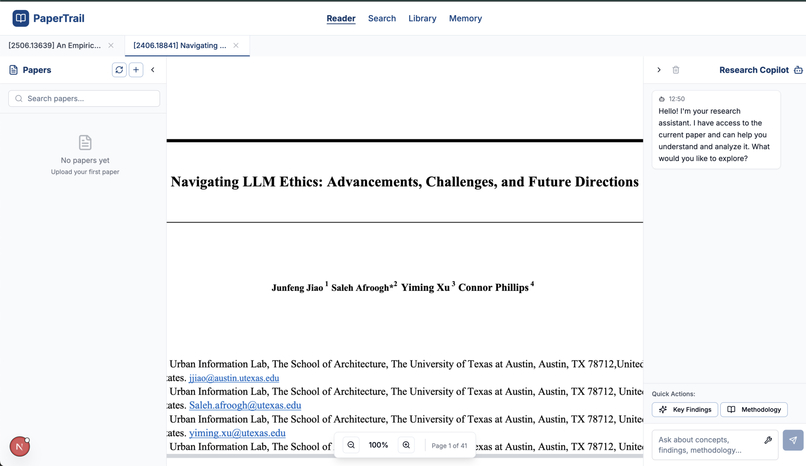
Research paper PDF viewer
-
Paper-Trail Home Page
-
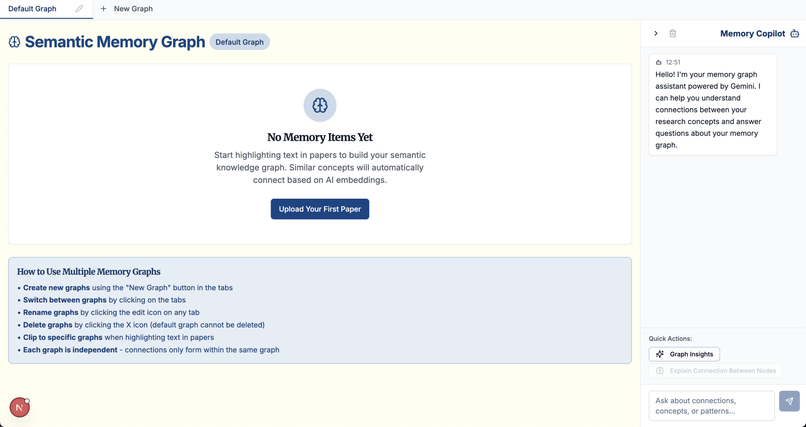
Semantic Memory Graph page
Inspiration
Humanity's greatest breakthroughs are born from the patient, often arduous, process of research. We began this journey by sitting down with professors at NYU, Baruch College, and Cornell, listening to their stories. They spoke of a universal struggle: the constant, jarring context-switching that fragments focus and stifles deep thought. A single unfamiliar concept can trigger a cascade of distractions, a new tab, a detour to an AI chatbot, a frustrating hunt to find where you left off. But as we dug deeper, we realized the problem was more profound. The emerging generation of AI tools was helping researchers talk to their documents, which was a great first step. But they weren't helping them think through them. A simple Q&A can define a term, but it can't reveal the subtle web of connections an author weaves between chapters, or how one paper's methodology silently refutes another's. True synthesis isn't about getting answers from a single source; it's about seeing the architecture of ideas across an entire field. This realization led us to two core principles. First, we needed to go beyond linear text and create a visual map of knowledge, which led to our Semantic Memory Graph. Second, we understood that the ultimate goal of research is communication. This inspired our most ambitious feature: the ability to transmute any paper into a concise, animated video summary. We set out to build a tool that supports the full cycle of research, from discovery and synthesis to creation and communication.
What it does
Paper-Trail is an all-in-one research command center designed to manage the entire lifecycle of academic work, from discovery and reading to synthesis and communication. It moves beyond simple document storage to become an active, intelligent partner in the research process.
The Intelligent Reading Environment:
At its core, Paper-Trail provides a sophisticated and seamless reading experience designed to maintain a researcher's flow state.
Multi-Tab PDF Viewer: Users can open and manage multiple research papers simultaneously in a clean, tabbed interface, similar to a web browser. This eliminates the need for juggling multiple PDF windows and allows for easy cross-referencing.
Project-Based Organization: All papers and notes are organized into projects, allowing users to keep their work for different subjects or collaborations neatly separated and accessible.
Smart Paper Ingestion: Getting papers into the system is effortless. Users can either drag-and-drop PDF files directly or use our advanced web scraper, powered by BrowserBase and Puppeteer, to import papers from complex academic sites like PubMed with a single URL.
AI Reading Co-Pilot:
Integrated directly into the reader is a powerful AI assistant, designed to be an ever-present research companion.
Context-Aware Chat: Highlight any text, equation, or diagram in a paper, and a chat window appears, ready to assist. Powered by Google's Gemini, the co-pilot can explain complex concepts, summarize dense paragraphs, or even rephrase arguments in simpler terms.
Eliminate Context Switching: By bringing the AI directly into the document, we eliminate the workflow friction of switching to a separate tab or application, keeping the user focused and immersed in the material.
The Semantic Memory Graph (The Synthesis Engine):
This is where Paper-Trail moves beyond simple Q&A. It transforms a user's library from a static list of files into a dynamic, visual web of knowledge.
Visualize Connections: Using Cytoscape.js, Paper-Trail builds an interactive knowledge graph that maps the hidden relationships between all the papers in a user's library. Nodes can represent papers, authors, or key concepts.
Deep Semantic Understanding: To power the graph, we built a sophisticated data pipeline. We use Google ADK to annotate each node with rich, domain-relevant metadata. We then create TextClip objects for key textual spans, embedding them with OpenAI’s API to compute fine-grained semantic similarity. This allows for intelligent link generation and even narrative summarization across multiple papers.
Session-Based Interaction: The graph is not static. It features a unique session-based system that dynamically updates to highlight nodes and connections related to the paper you are currently reading, making discovery relevant and immediate.
Automated Video Summaries (The Communication Engine):
This is our flagship feature, where research is not just understood, but transformed. With a single click, any dense academic paper can be transmuted into a concise, one-minute animated video summary.
Natural Language Trigger: From the AI Co-Pilot chat, the user can simply type a prompt like, "Generate a video explaining the main findings of this paper."
The AI-Powered Pipeline: This triggers a sophisticated backend microservice that orchestrates a symphony of AI tools:
Content Analysis (Claude): Anthropic's Claude reads the entire paper and generates a coherent, educational script and a scene-by-scene configuration for the video.
Animation Generation (Manim): The powerful Manim animation engine uses the script to create precise, visually engaging animations of key concepts, equations, and data, using LaTeX for perfect mathematical rendering.
Voice Synthesis (LMNT): The LMNT API takes the script and generates a high-quality, natural-sounding voice-over.
Video Assembly (MoviePy & FFmpeg): Finally, our backend programmatically stitches all the animated clips, audio tracks, and transitions together into a polished, shareable MP4 file.
Instant Accessibility: The finished video is delivered directly back to the user in the chat, ready to be viewed, downloaded, or shared, making complex knowledge instantly accessible to a wider audience.
How we built it
Our project is a combination of two powerful codebases, Paper-Trail and Manim Video Generation, which work together to create a seamless research-to-video pipeline. We leveraged a comprehensive stack of modern technologies to bring this vision to life.
Languages: We used TypeScript & JavaScript for the Paper-Trail frontend and Next.js backend, Python for the core language for the Manim video generation microservice, and LaTeX for precise mathematical and scientific formula rendering in the generated videos.
Frameworks & Platforms: We used Next.js v15 & React v19 for building the fast, server-rendered Paper-Trail web application, FastAPI as the high-performance Python framework for our video generation backend, Manim as the powerful animation engine for creating mathematical visualizations, and Tailwind CSS, Radix UI & Shadcn UI as a suite of tools for crafting a beautiful, responsive, and accessible user interface.
Cloud, Databases & Deployment: We used Vercel for deploying and hosting the Paper-Trail frontend, Google Cloud Platform (Vertex AI, Gemini API) to power our core AI capabilities, MongoDB Atlas as our primary NoSQL database for storing all application data, Browserbase for robust, headless browser automation to scrape research papers, Weights & Biases Weave for comprehensive monitoring and tracing of our video generation pipeline, and LMNT as the cloud service for generating high-quality text-to-speech voice-overs.
APIs & AI Services: We integrated a suite of AI services including Google Generative AI, OpenAI API, and Anthropic API for various analytical tasks. Exa API is used for advanced web search, while the Browserbase API and LMNT API handle web automation and voice synthesis, respectively.
Key Libraries & Tools: For PDF Processing, we used PDF.js and jsPDF on the frontend, and PyMuPDF on the backend. For Visualization, Cytoscape.js powers our knowledge graph, and Recharts is used for other charts. To enrich our Semantic Memory Graph with deeper semantics, we leveraged Google ADK to annotate each graph node with domain-relevant metadata. We also created TextClip objects representing key textual spans for each node, embedding them using OpenAI’s embedding API. This allowed us to compute fine-grained semantic similarity between concepts, supporting more intelligent link generation and narrative summarization across papers. For Video Editing, MoviePy and FFmpeg are used to programmatically stitch video clips and audio together. For State Management & Validation, Zustand and Zod ensure a predictable and robust state management system in our frontend.
Challenges we ran into
Building a project of this complexity was a journey filled with tough but rewarding challenges. The Semantic Memory Graph: Creating truly meaningful connections between papers proved incredibly difficult. The initial vector embeddings we received from Gemini for our knowledge graph were hard to work with, making it a challenge to establish a coherent similarity matrix. We also had to use an LLM to intelligently select which text chunks from a paper should be imported into the graph, a process that was initially slow and computationally intensive. This led us to develop a novel session-based memory graph, which dynamically connects the graph view to the user's current reading session.
The Video Pipeline: The video generation backend was a beast of its own. Stitching the individual Manim/Veo clips and audio together seamlessly required precise timing and error handling. Building a robust and scalable API to orchestrate Manim, Claude, and Veo/LMNT was a significant architectural challenge that pushed us to adopt a full microservice approach.
Core Application Features: Early on, we struggled to implement a multi-tabbed interface that would allow users to switch between papers like in a web browser. This was due to initial hurdles in getting MongoDB to store and retrieve paper sessions correctly, which we had to re-architect. Data Extraction: Reliably extracting PDFs from the web is non-trivial. We had to write highly specific, custom instructions for BrowserBase to navigate the complex DOM structures of academic websites like PubMed and consistently locate the correct PDF links.
Accomplishments that we're proud of
We are incredibly proud of creating a tool that feels truly cohesive and intelligent. However, our biggest achievement is the production-ready video generation pipeline. Designing and implementing the separate microservice architecture was a complex task, but it resulted in a system that is scalable, resilient, and highly performant. The fact that a user can simply type a natural language prompt and receive a full-fledged animated video summary a minute later is something we're extremely excited about.
What we learned
This project was a deep dive into full-stack development and practical AI integration. We learned a tremendous amount about: Microservice Architecture: The importance of process isolation for resource-intensive tasks and how to design clean APIs for communication between services. AI Orchestration: How to chain multiple AI models together (Claude for analysis, LMNT for voice) to create a complex, multi-step workflow. We learned how to move beyond simple prototypes to think about scalability, error handling (like our Veo API key fallback), and the end-user experience.
What's next for Paper-Trail
Our vision is to evolve Paper-Trail from a powerful analysis tool into a proactive scientific partner, an AI that performs meta-analysis across entire fields to identify gaps and suggest novel hypotheses. We will transform the knowledge graph into a real-time collaborative space where research teams can build shared intelligence, ultimately making Paper-Trail the operating system for modern discovery.
Built With
- browserbase
- claude
- cytoscape.js
- date-fns
- fastapi
- ffmpeg
- gcp
- gemini
- git
- google-cloud
- javascript
- lmnt
- manim
- mongodb
- moviepy
- next.js
- pdf.js
- postcss
- puppeteer
- pymupdf
- python
- radixui
- react
- recharts
- shadcnui
- tailwindcss
- typescript
- uvicorn
- vercel
- vertexapi
- weave
- zod
- zustand


Log in or sign up for Devpost to join the conversation.