-
-
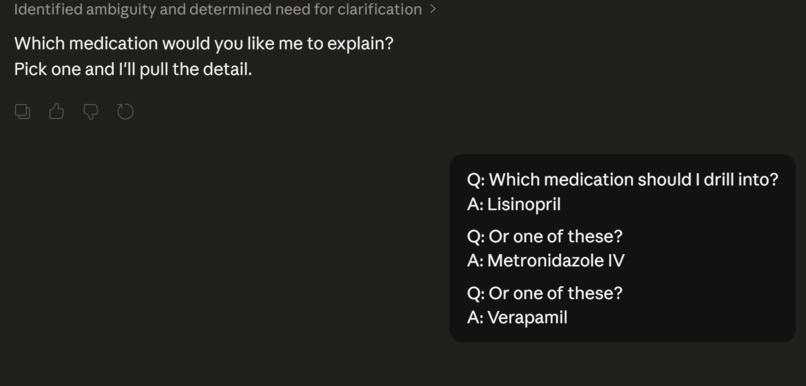
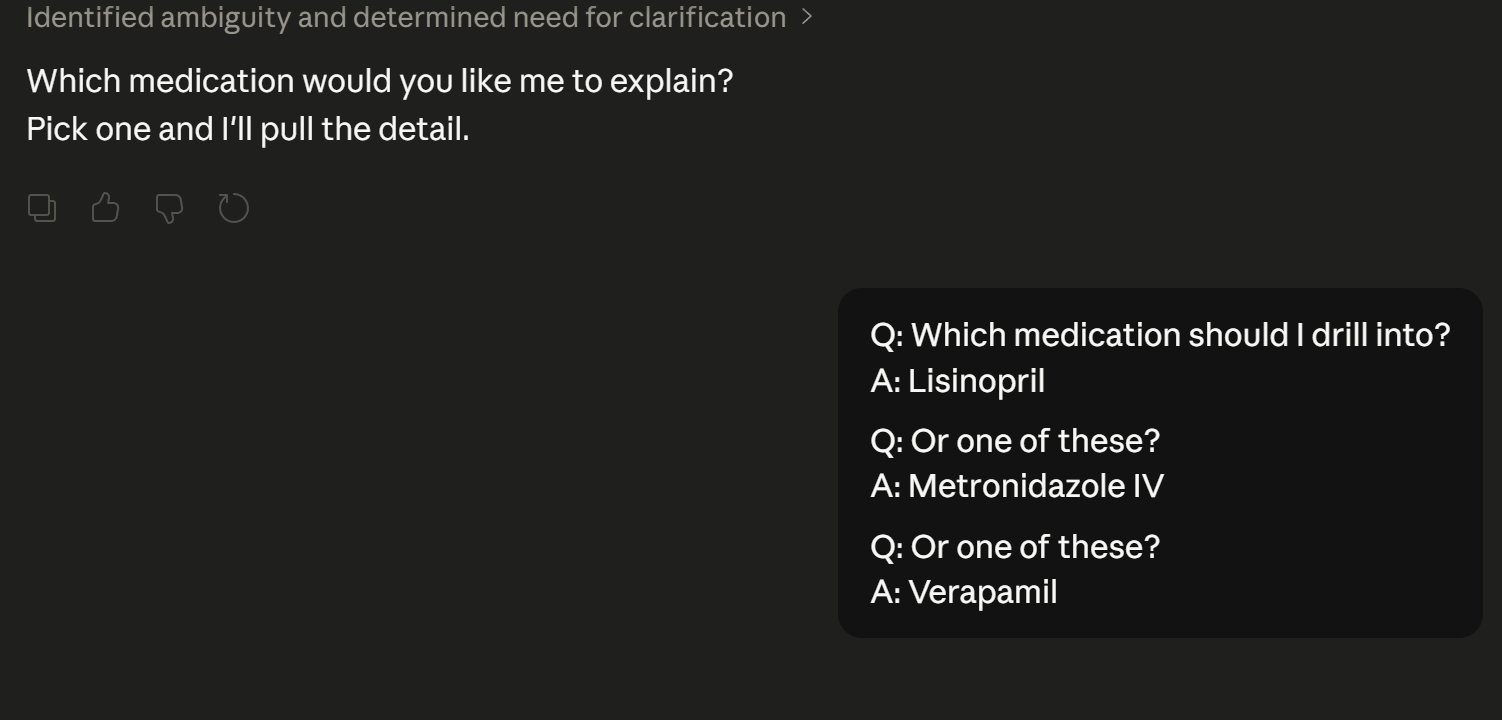
Asking if you would like to know which meds your refering too.
-
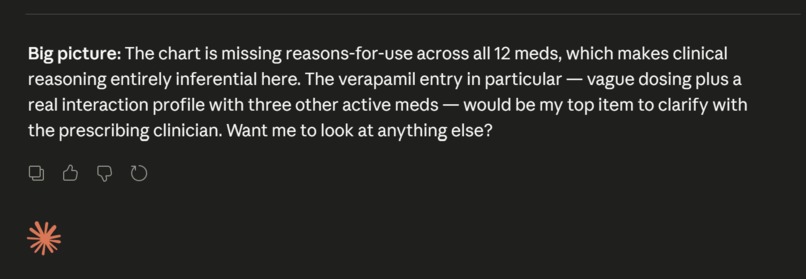
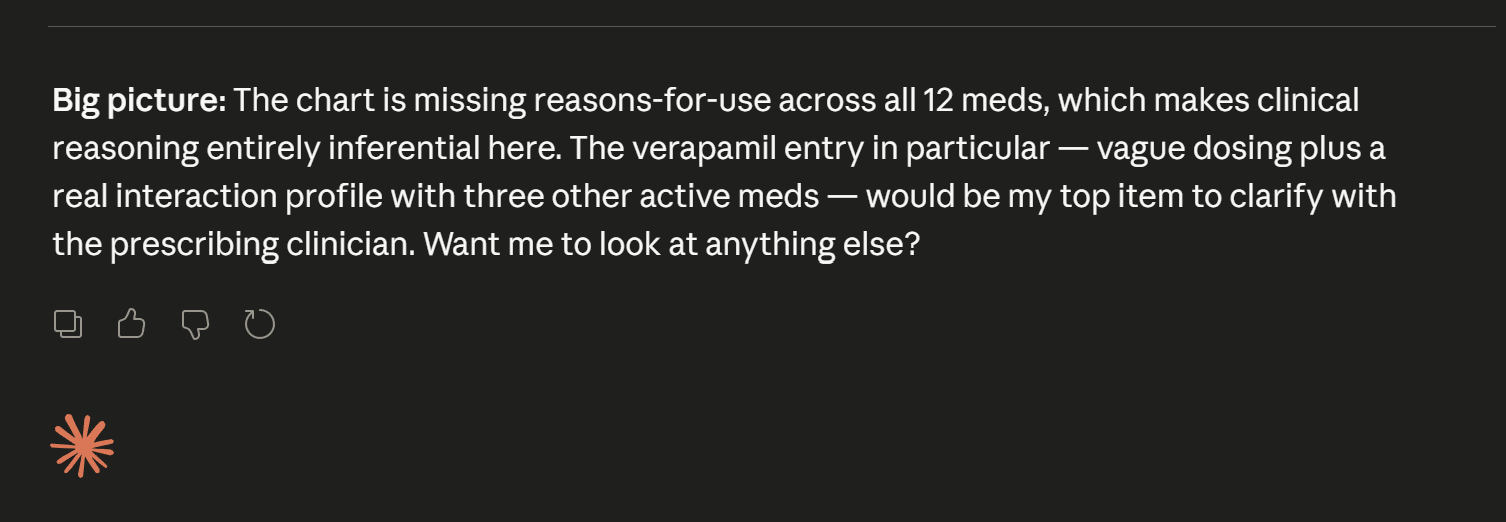
Asking if there is any more info you would like to search for.
-

First you ask to find the patients medication records
-
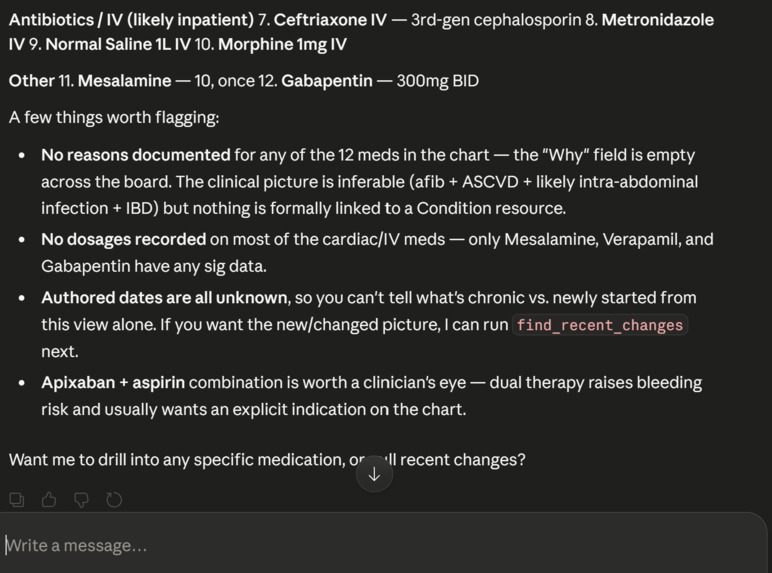
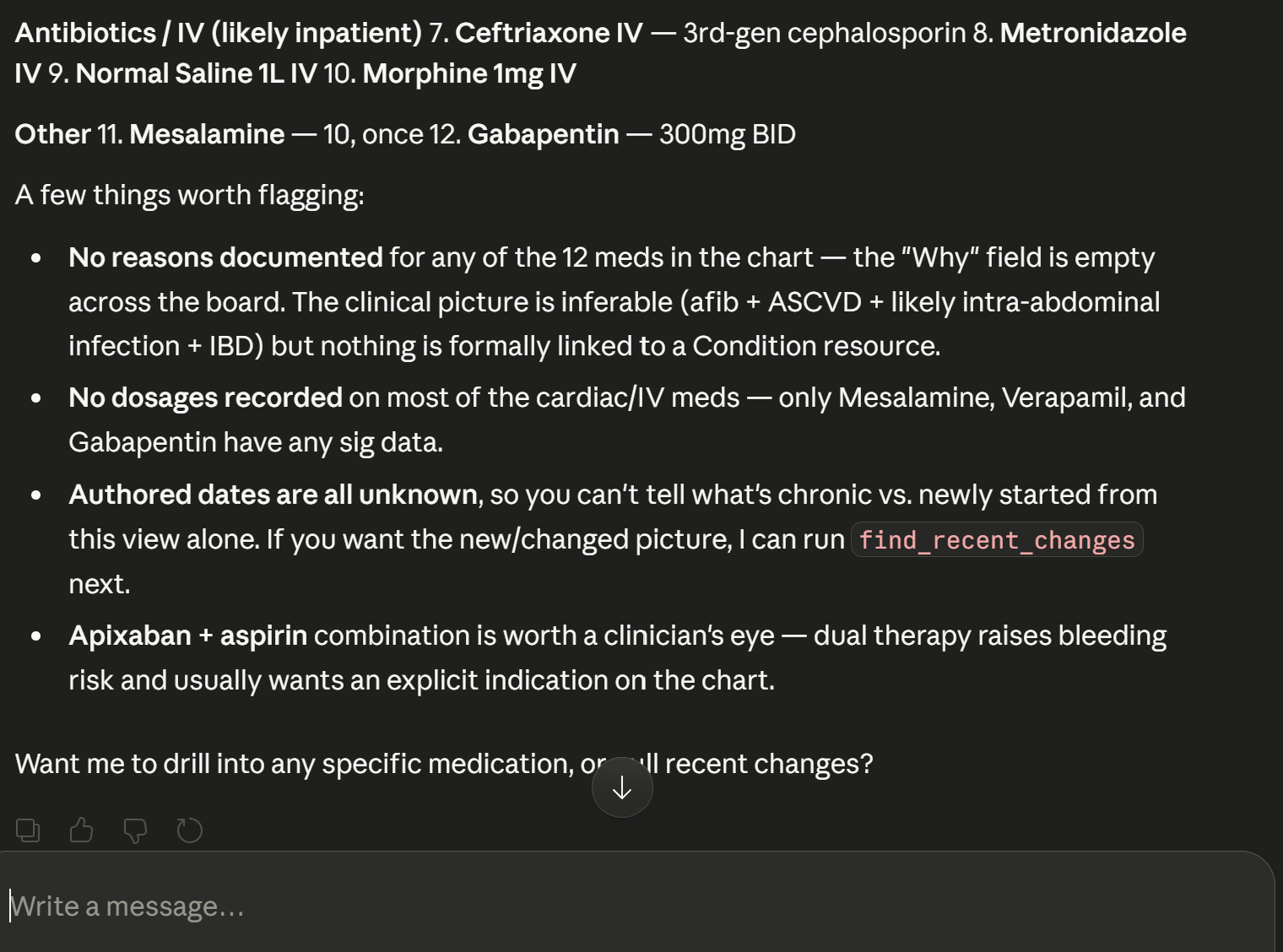
The Agent shows you what is in the records
-
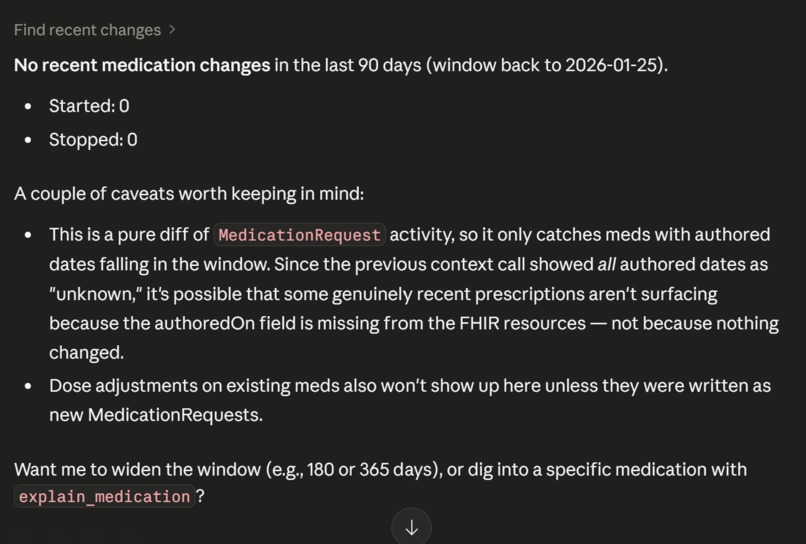
Agent showing more data
-
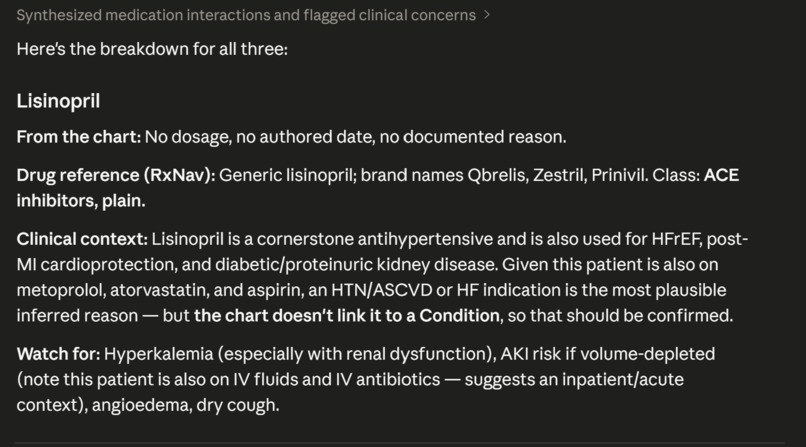
Gives explination on first one.
-

Third medication explination
-

Second explination



Scrub — Handle the repetitive tasks so clinicians can focus on the complicated stuff
Inspiration
I didn't start with a technology and look for a problem. I started with a conversation.
My mom is a nurse. When I told her I was building something for a healthcare AI hackathon, I asked her one question: "If an AI tool could do one thing for you, what would it be?"
She didn't ask for diagnosis. She didn't ask for decision support. She said:
"Something that could handle the repetitive tasks so I can focus on the more complicated stuff."
I asked her to walk me through what those repetitive tasks actually look like. She described medication reconciliation — the process of assembling a complete picture of what a patient is taking, why, who prescribed it, and when. She does this at every admission, every discharge, every visit. It takes 5 to 15 minutes per patient, depending on how many medications they're on and how many questions they have.
She works from a paper printout. When she needs drug information that isn't in the chart — what a generic name maps to, what therapeutic class something belongs to, whether a brand name she doesn't recognize is the same drug under a different label — she Googles it on her phone. Not because she's behind the times, but because that information isn't where she needs it when she needs it.
Every part of Scrub came directly from that conversation. The three tools, the output format, the design principles, the things it deliberately doesn't do — all of it traces back to what she told me about her actual workflow. I wrote her quotes down in a quotes.md file in the project repo and used them as a design checklist throughout the build.
What it does
Scrub is an MCP server that exposes three tools, each one replacing a specific repetitive task in clinical medication workflows:
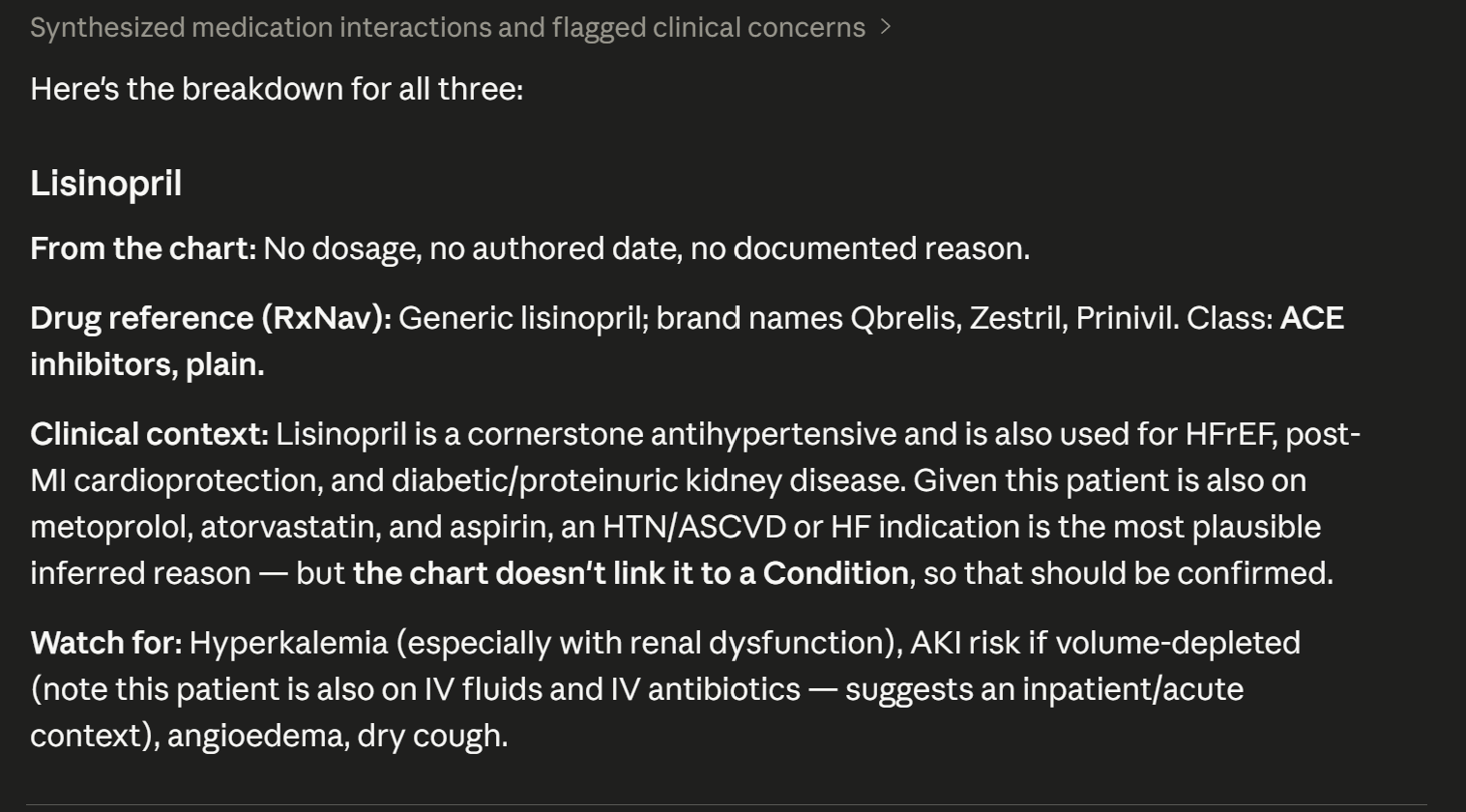
get_patient_med_context — The main tool. Takes a patient ID (via SHARP context), pulls every active medication from the FHIR server, links each one to its recorded reason for use (resolving Condition references), enriches each drug with generic/brand names and therapeutic classification from NIH's RxNav and RxClass APIs, and returns a structured one-page document. The output is formatted for print — because that's how my mom actually works. What takes 5–15 minutes by hand takes about 4 seconds.
explain_medication — A single-drug deep dive. When a patient asks "what's this pill for?", the clinician gets a grounded answer with the reason for use pulled from the chart and drug information sourced from NIH public databases — the same sources she'd end up on if she Googled it herself.
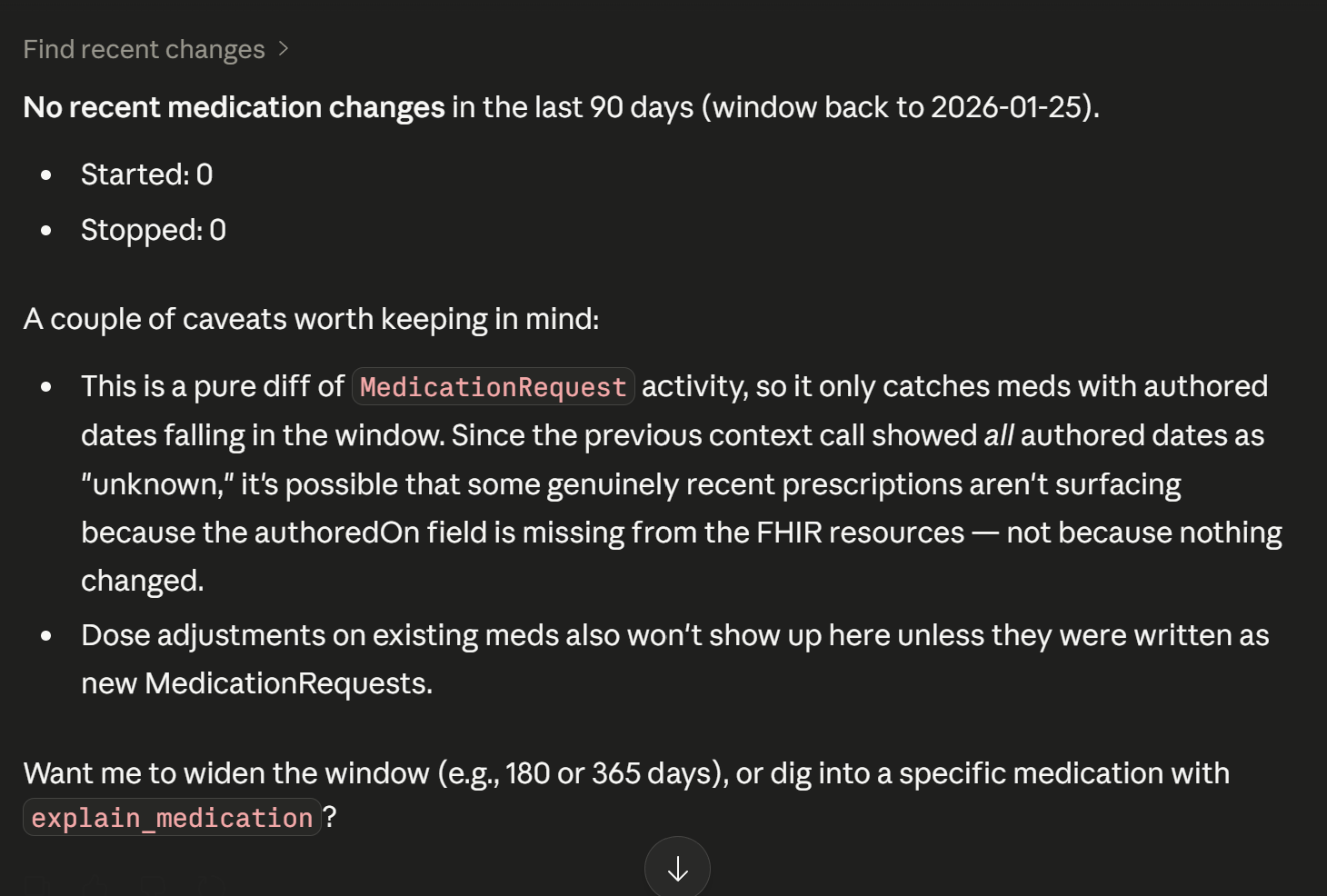
find_recent_changes — A mechanical diff of the medication list over the last N days. No interpretation, no judgment — just "these were started, these were stopped." Answers "what's changed since last visit?" without scrolling through encounter history.
The tools return both structured JSON (for agent consumption) and markdown (for human-readable rendering in a clinical workspace). Every piece of information links back to a FHIR resource ID the clinician can verify. The footer on every document reads: "Generated by Scrub from FHIR resources. Findings are advisory. Clinician review required."
How I built it
Stack: TypeScript, @modelcontextprotocol/sdk (stdio transport), raw fetch() for FHIR R4 REST calls, NIH RxNav and RxClass public APIs for drug enrichment. No database, no heavy FHIR client library, no framework. The entire server is about 600 lines across 10 source files.
Architecture: Scrub receives SHARP context (patient ID, FHIR base URL, auth token) from the platform, makes authenticated FHIR calls to pull MedicationRequest and MedicationStatement resources, normalizes them into a common shape, enriches each one via RxNav, resolves linked Condition references for the "why," and returns a structured document. It's stateless — no data is stored between calls, no patient information persists. The same code runs against HAPI's public sandbox in development and would run against a production EHR's FHIR endpoint without modification.
Development workflow: I built two smoke-test scripts early — one that hits HAPI to find synthetic patients with active medications and scores them by data richness, and one that verifies RxNav enrichment against known drug codes. These let me validate the entire data pipeline before touching MCP wiring. Development and debugging happened in the MCP Inspector, with Claude Desktop used for end-to-end integration testing.
Design decisions driven by the interview:
Repetitive tasks only. The test for every tool: "Is this something my mom does the same way every time, or does it require clinical judgment?" If judgment, I didn't build it. Scrub never says "this patient should stop taking X." It says "this patient has been on X since [date], prescribed for [condition]" and lets the clinician decide.
Print-friendly output. My mom works from printouts. The markdown output is designed to render as a clean one-page document that a clinician could print, fold in half, and carry into a patient room — not a dashboard, not a chat response.
NIH sources for drug info. When my mom needs drug information, she ends up on NIH websites anyway. Scrub pulls from the same source programmatically — RxNav for generic/brand mapping and RxClass for therapeutic classification. No commercial drug databases, no API keys, no licensing.
Show your work. Every medication entry includes the FHIR resource ID and source type. Every enrichment block cites RxNav. The clinician can verify anything the tool asserts. This came directly from my mom saying trust is earned — "based on who you are and how long you've been there." A new tool earns trust by being transparent, not by being confident.
Challenges I faced
Dirty upstream data and the morphine bug. The most important lesson of the project. While testing against HAPI's public sandbox, I noticed that "Morphine 1mg IV" was being enriched with drug information for remifentanil — a completely different opioid. Investigation revealed the FHIR resource had been coded with the wrong RxNorm identifier (RxCUI 73032, which maps to remifentanil, not morphine). The display text said "Morphine" but the structured code pointed elsewhere.
This is not a synthetic-data-only problem. Real EHRs have exactly these kinds of coding mismatches at scale. For a clinical tool, confidently asserting that morphine is remifentanil isn't just wrong — it's dangerous.
The fix: a plausibility guard that checks whether the RxNav-returned generic name bears any resemblance to the drug's display name in the chart. If they don't match, Scrub rejects the enrichment entirely and returns "no enrichment available" rather than asserting incorrect information. The guard also applies to cached results, so a poisoned cache entry from a previous run can't bypass the safety check.
I turned this bug into a design principle: in healthcare AI, honestly uncertain is always better than confidently wrong. The guard catches an entire class of upstream data quality issues, and it's the kind of defensive coding that matters more than any feature.
FHIR search parameter naming. The find_recent_changes tool initially failed because I used authored as the search parameter name. FHIR's MedicationRequest resource uses authoredon (one word). A small typo, but FHIR returns a 400 with an OperationOutcome that doesn't make the issue obvious. Lesson learned: FHIR search parameter names don't always match the resource field names, and the error messages are not helpful.
HAPI sandbox data sparsity. The public HAPI FHIR sandbox is populated with synthetic data of wildly varying quality. Most patients have zero or one medication. Dosages, authored dates, and reason references are missing more often than not. I built a patient-scoring script that evaluates candidates by medication count and presence of reason references, then selects the best available test patient. For the demo I use two patients: one with 12 medications (showing the assembly value) and one with a single medication that has a real linked Condition (showing the reason-resolution feature).
MCP development environment on Windows. MCP development documentation is largely Mac-oriented. On Windows, several things required adjustment: PowerShell environment variable syntax ($env:VAR vs export VAR), the Microsoft Store version of Claude Desktop not reading config from the expected %APPDATA% path (requiring the direct-download installer instead), and the MCP Inspector's proxy authentication token workflow. None of these were blocking, but they added friction to a first-time MCP development experience.
What I learned
Interview first, build second. The 30-minute conversation with my mom was worth more than any amount of FHIR documentation reading. Every design decision I made traces back to something she said. "Handle the repetitive tasks" became the tool selection criteria. "Having everything in one place" became the one-page document output. "She just Googles it" became the RxNav enrichment layer. Engineers building healthcare tools without talking to clinicians build impressive software that solves imaginary problems.
MCP servers are parts, not products. The biggest mental shift was understanding that I wasn't building an app with a UI — I was building a capability that plugs into other apps. The "UI" is whatever client calls my tool: Claude Desktop, Prompt Opinion's workspace, or any future MCP-compatible platform. My job stops at "return a well-structured document." The rendering is someone else's problem, and they've already solved it.
Defensive coding is a feature, not overhead. The morphine plausibility guard is maybe 15 lines of code. It's also the single most important thing in the entire project from a clinical safety perspective. In healthcare AI, the happy path is easy. The failure modes are where trust is built or destroyed.
What's next
- Publish to the Prompt Opinion marketplace and test against their SHARP context implementation
- Add common drug alias handling (e.g., "Normal Saline" → "sodium chloride") to reduce false rejections from the plausibility guard
- Add related observation linking — for a patient on metformin, automatically pull their most recent A1C; for a patient on lisinopril, pull their most recent blood pressure
- Explore a
format: "html"output option for clinics that prefer on-screen rendering over print
Built with
TypeScript, Node.js, MCP SDK, FHIR R4, NIH RxNav API, NIH RxClass API, HAPI FHIR Public Sandbox
Built by
John Jake
Built With
- fhir
- fhir-r4
- hapi
- mcp-sdk
- nih-rxclass-api
- nih-rxnav-api
- node.js
- public
- typescript

Log in or sign up for Devpost to join the conversation.