Inspiration
Breast cancer screening is still framed as a one-size-fits-all schedule, even though the real decision is more complex. Age matters, but so do family history, breast density, prior BI-RADS findings, biopsy history, screening adherence, and whether someone can realistically follow through with a recommended route. We were inspired by the gap between guideline-based screening and truly personalized screening decisions.
ScreenRoute started from a simple question. The question: instead of giving someone a single risk score, what if we could compare several evidence-grounded screening routes side by side and make the tradeoffs visible? We wanted to build something that reflects the real screening journey: normal exams, callbacks, short-interval follow-up, benign biopsies, re-entry to routine screening, and the very real influence of access barriers. That led us to build ScreenRoute as an open, personalized breast cancer screening policy simulator rather than another static risk calculator.
What it does
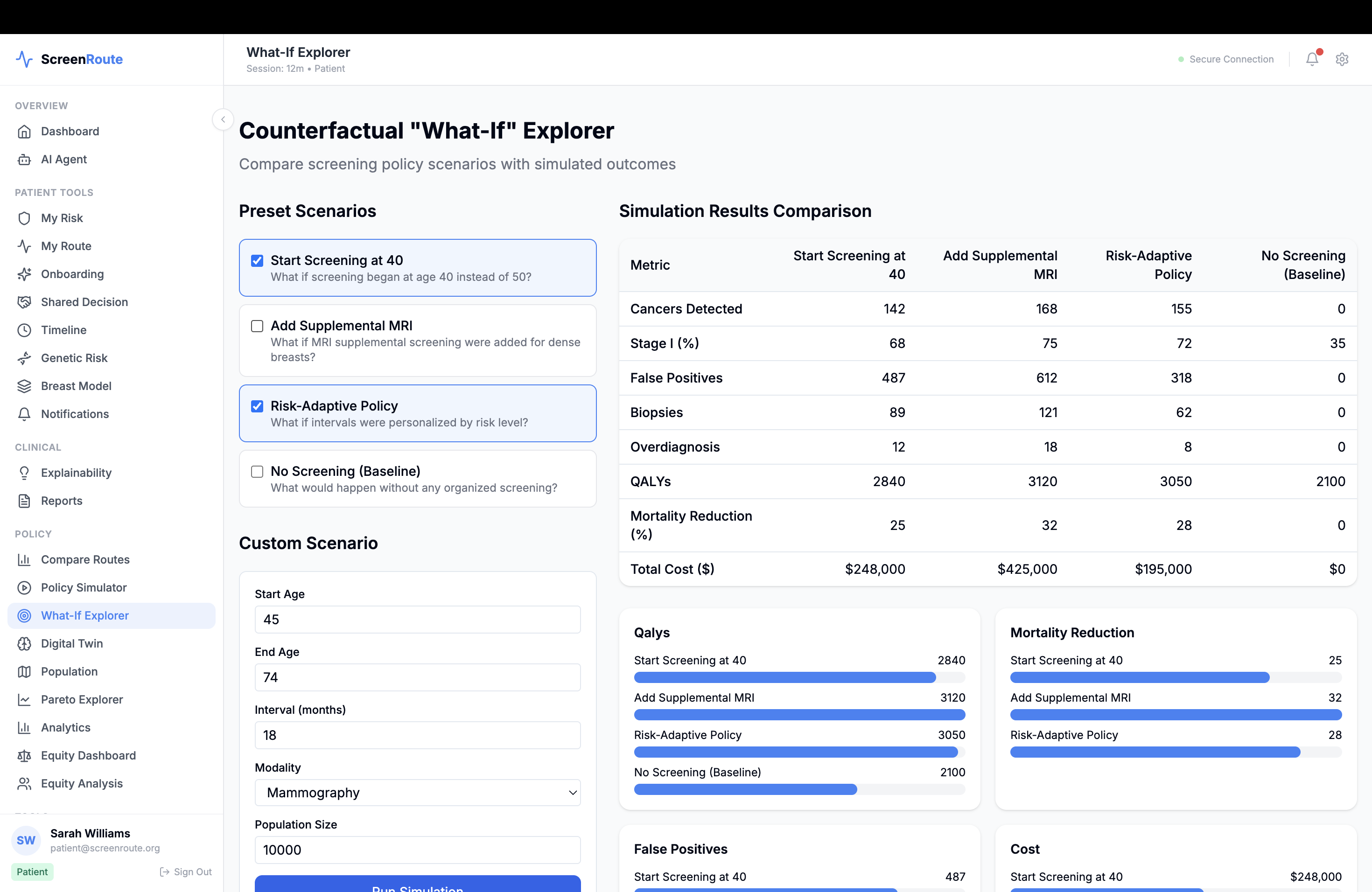
ScreenRoute is an open personalized breast cancer screening policy simulator. It compares plausible screening routes across benefit-harm frontiers using public and open research data, longitudinal screening history, imaging context, and access factors.
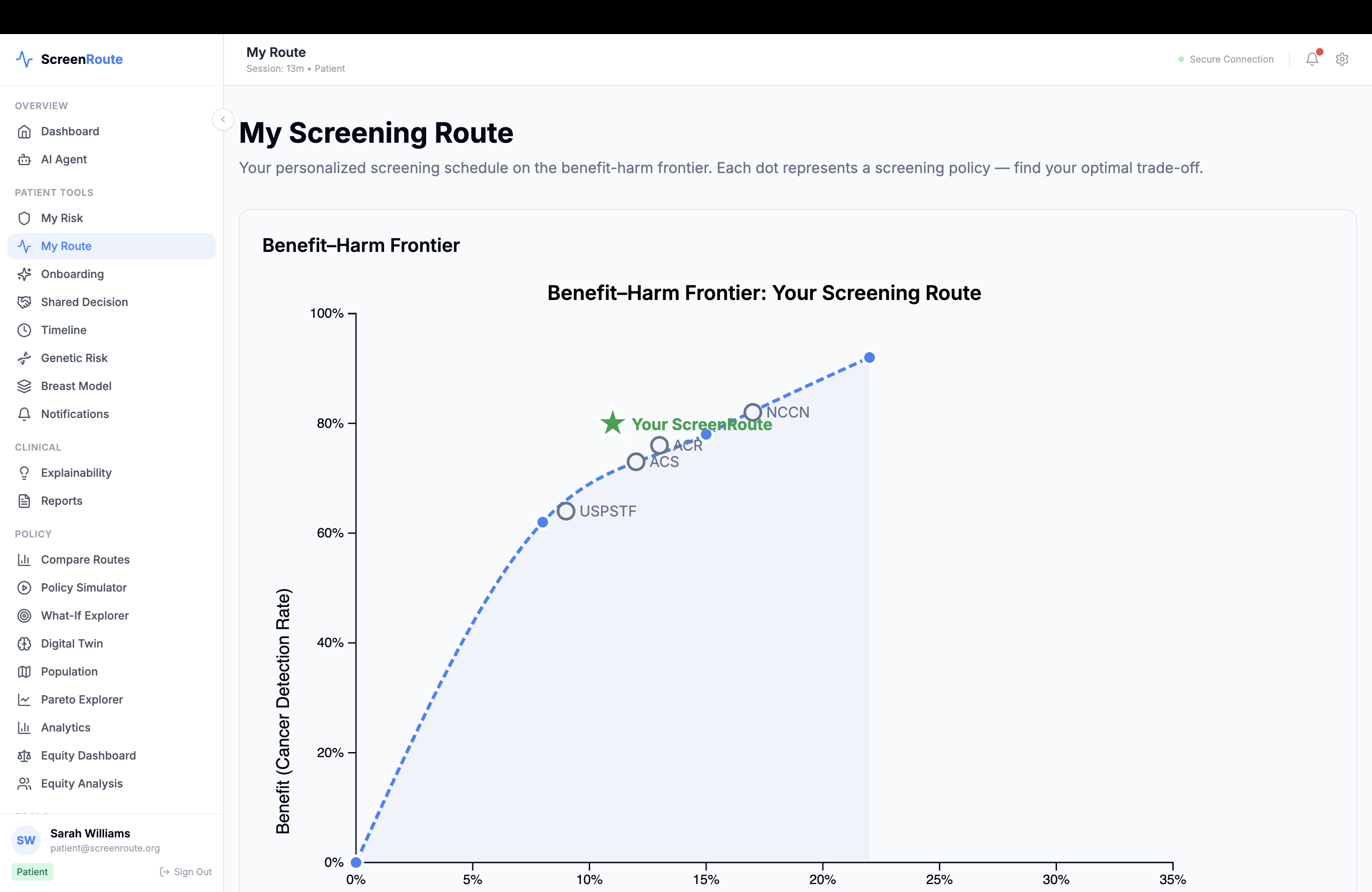
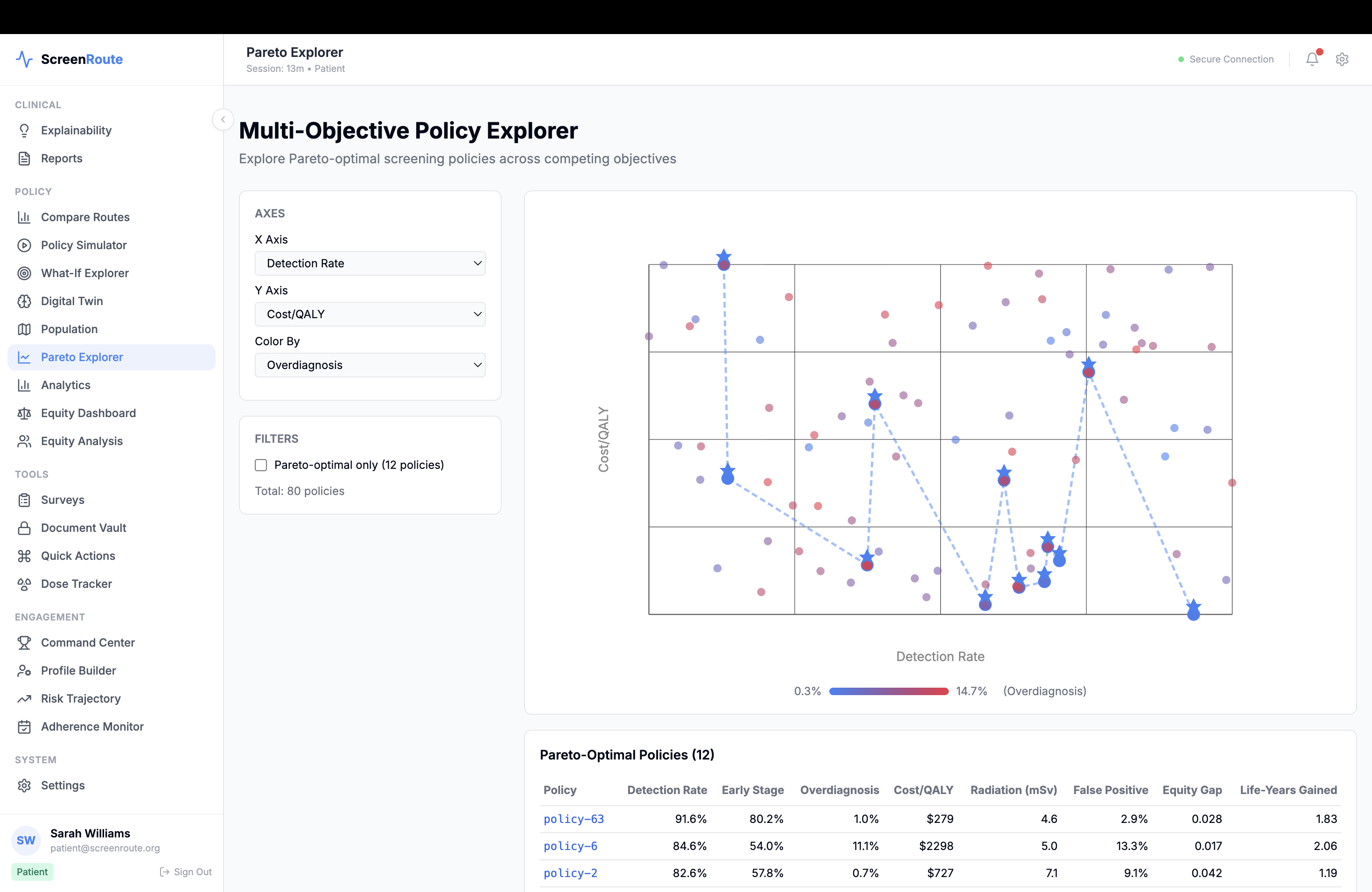
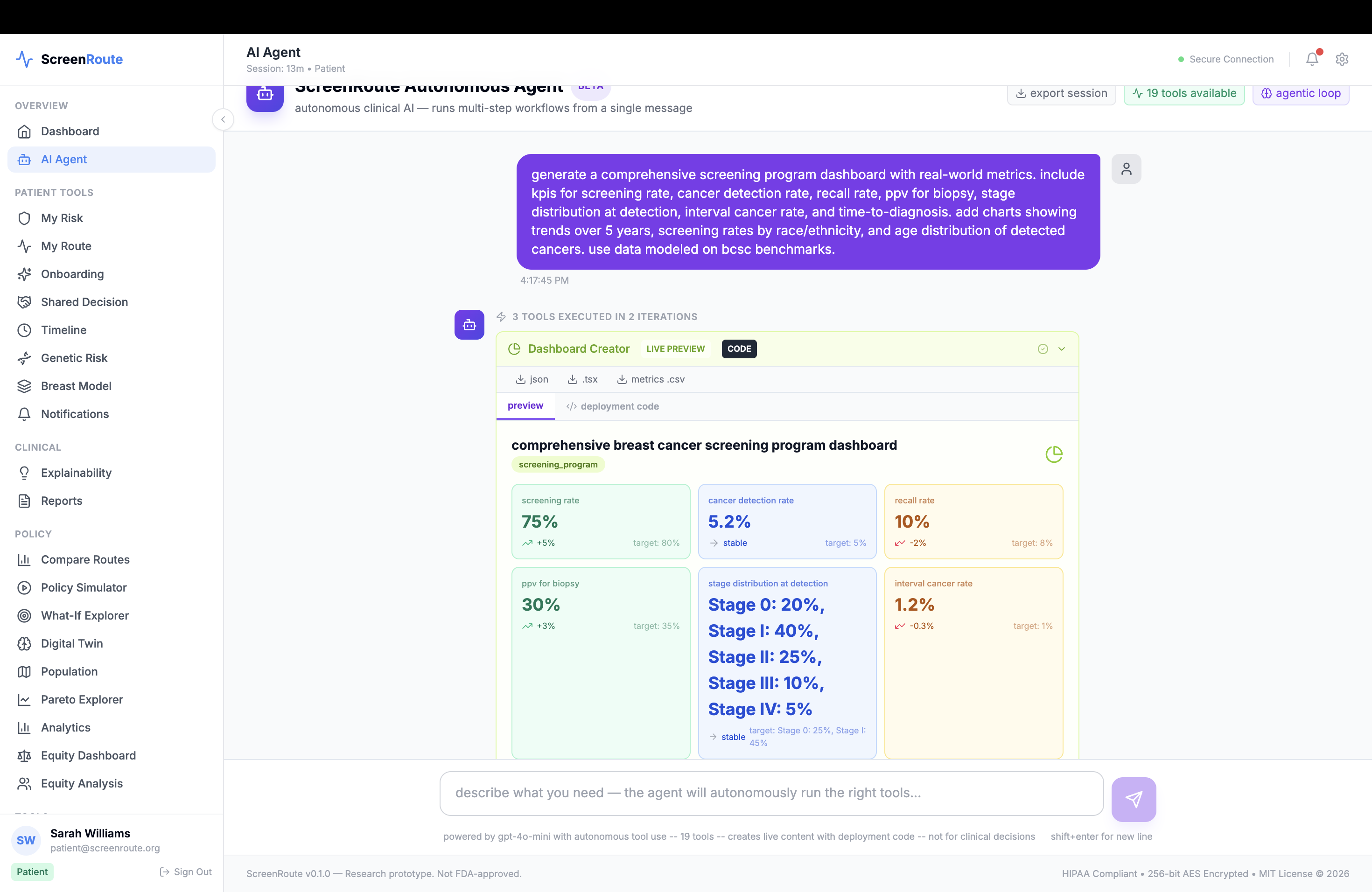
Instead of outputting one opaque recommendation, ScreenRoute shows a small set of candidate routes and explains why they differ. For each route, it estimates tradeoffs across outcomes such as early detection opportunity, advanced-cancer proxy risk, false-positive burden, benign biopsy burden, screening intensity, and real-world feasibility. It also shows which guideline family a route most closely resembles, where guidelines agree or disagree, and where uncertainty remains.
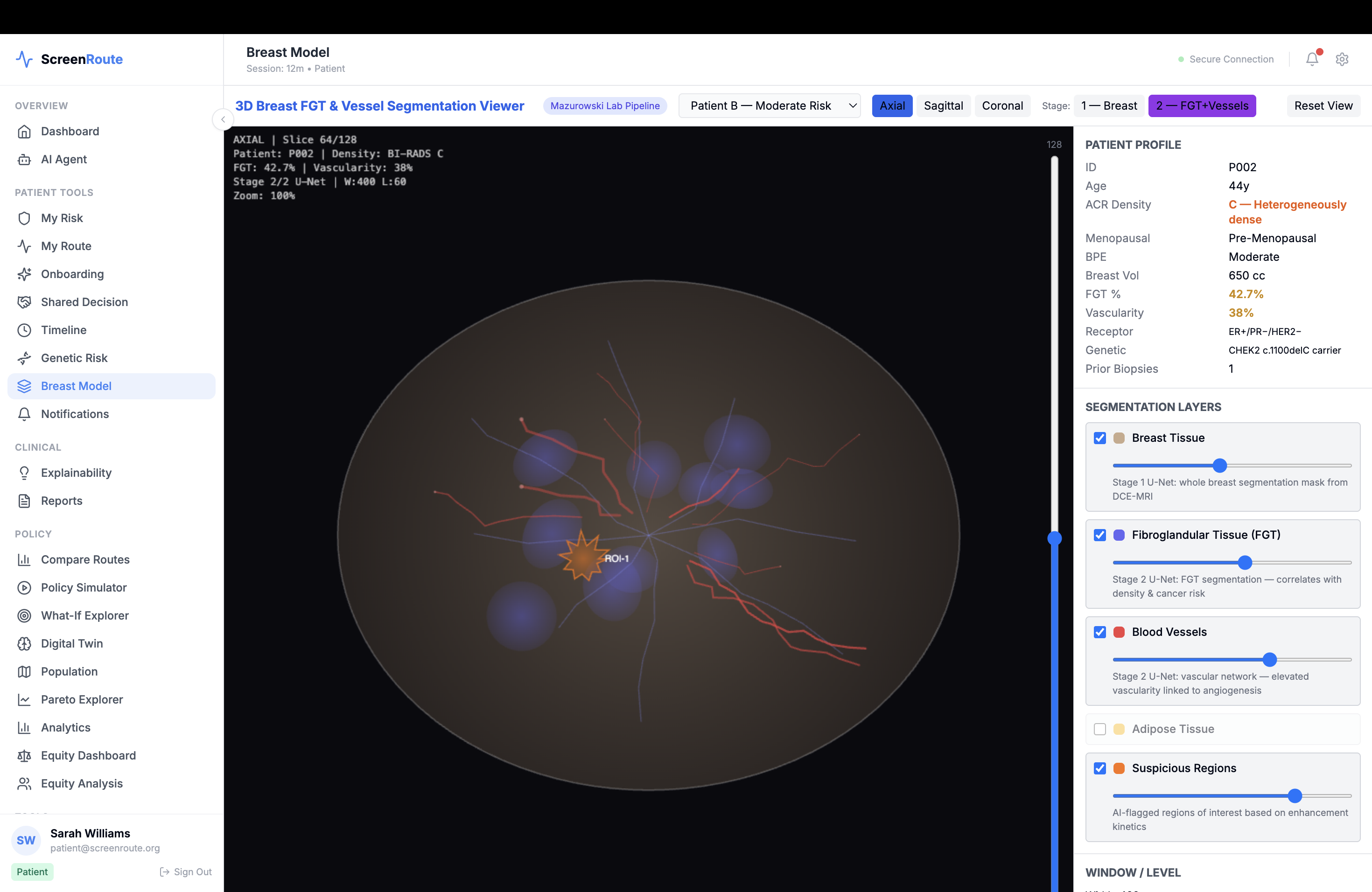
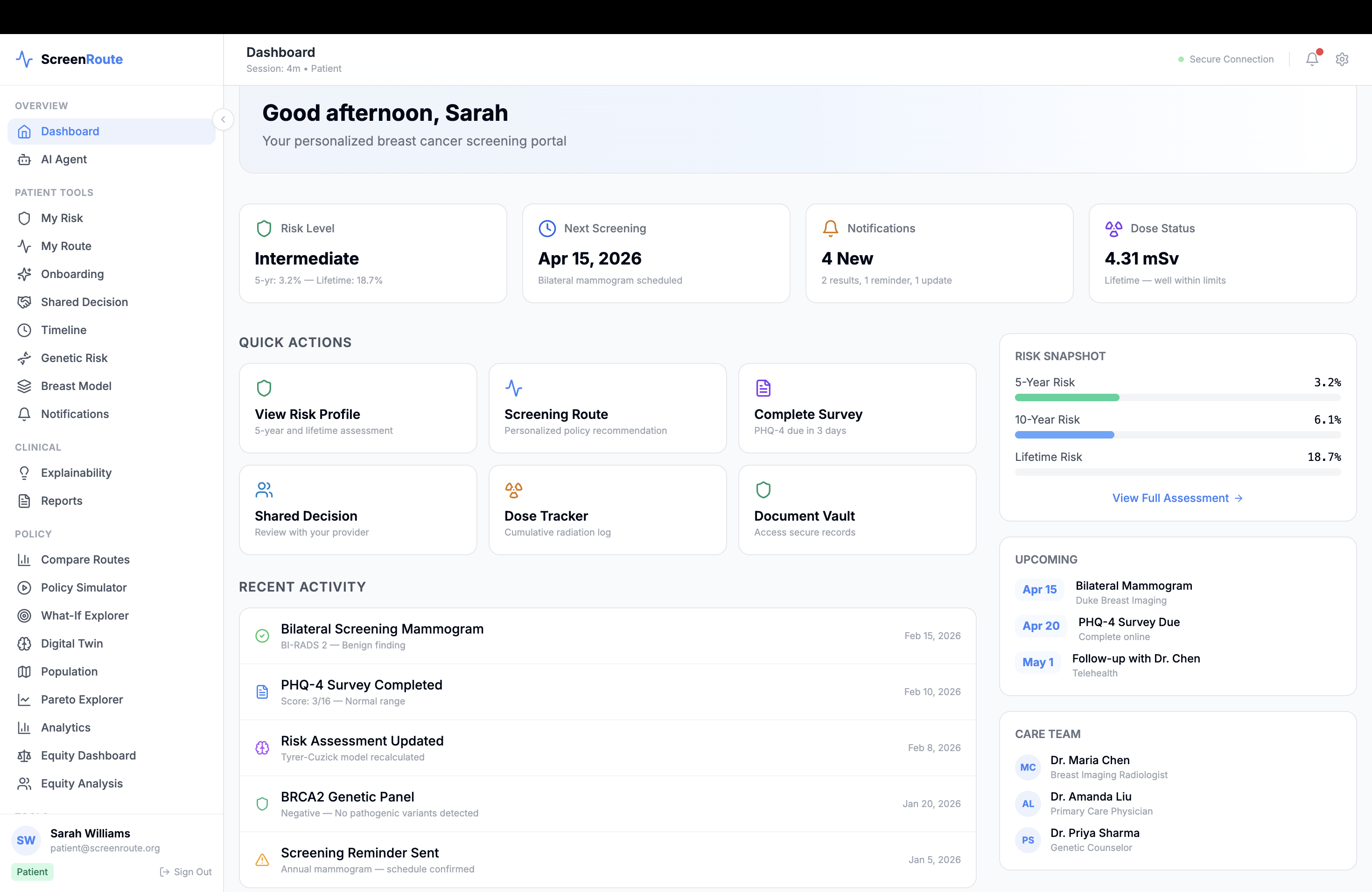
The platform includes a policy comparator, a patient screening twin that tracks longitudinal screening state, imaging and findings views, population and county-level access context, and simulation tools for running personalized and population-level route comparisons.
How we built it
We built ScreenRoute as a full-stack clinical simulation platform. The frontend uses Next.js, React, TypeScript, Tailwind, D3, Recharts, and Cornerstone.js to power interactive frontiers, timelines, guideline comparisons, and DICOM viewing. The backend uses FastAPI, SQLAlchemy, PostgreSQL with TimescaleDB, Redis, and Celery for APIs, longitudinal data storage, and asynchronous simulation workflows.
At the modeling layer, we combined several ideas instead of relying on a single model. We used public baseline risk frameworks such as BCSC-style and Gail/BCRAT-style baselines, then layered on longitudinal history encoding, imaging-derived features, causal reasoning, and multi-objective optimization. We modeled the screening episode as a longitudinal state machine with states such as routine negative screening, callback, BI-RADS 3 short-interval follow-up, diagnostic workup, benign biopsy return, and high-risk routing. On top of that, we built a policy engine that compares evidence-grounded action families like annual mammography, biennial mammography, short-interval follow-up, diagnostic workup, and MRI-plus-mammography for clearly high-risk scenarios.
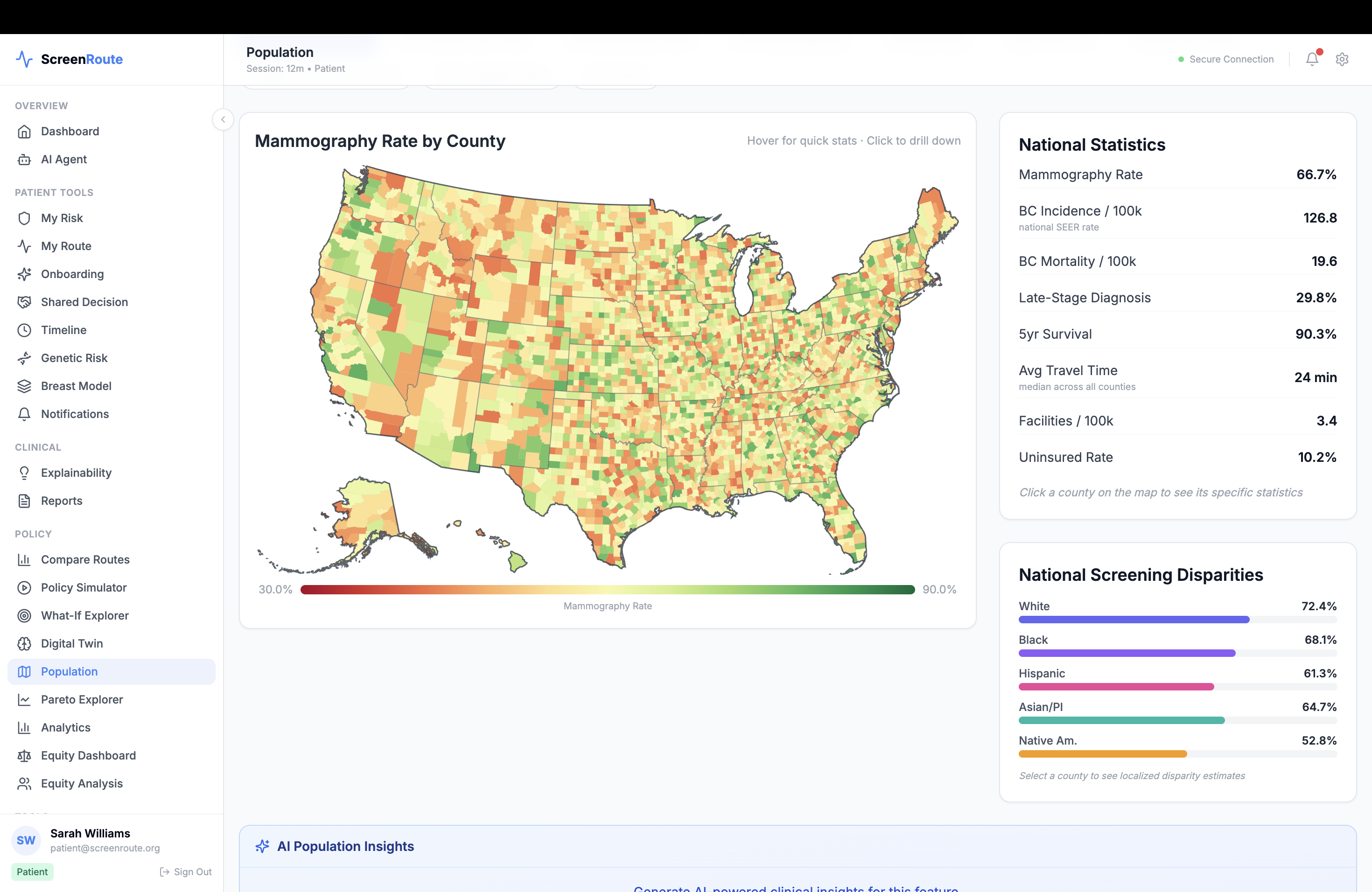
We also integrated clinical standards and healthcare interoperability from the start. ScreenRoute supports FHIR R4 resources, SMART on FHIR, CDS Hooks, DICOM workflows through Orthanc, OMOP concept mappings, and report parsing for BI-RADS and density extraction. To make the simulator useful beyond an individual case, we added county-level context such as screening prevalence and social-need indicators so the system can reason not just about theoretical benefit, but about whether a route is realistically achievable.
Challenges we ran into
One of the biggest challenges was honesty. Public screening datasets are powerful, but they do not directly tell us what would have happened under every alternative schedule for every individual. That meant we had to design ScreenRoute as a semi-synthetic policy simulator rather than overclaiming trial-grade counterfactual truth. Building something ambitious while staying scientifically responsible was a constant design constraint.
Another challenge was integrating very different data and standards into one coherent system. Population calibration data, longitudinal mammography histories, lesion-level imaging datasets, FHIR resources, DICOM studies, and county-level access signals all live in different formats and operate at different levels of granularity. Aligning them into a single screening-state representation was hard.
We also had to balance sophistication with clarity. It is easy to build a model that outputs a number; it is much harder to build a system that explains why one screening route looks better than another, shows uncertainty, and still feels usable to clinicians, researchers, and judges in a short demo.
Accomplishments that we're proud of
We are proud that ScreenRoute does not stop at risk prediction. It compares screening policies. That shift from “What is this person’s risk?” to “Which route creates the best balance of benefit, harm, and follow-through?” is the core accomplishment of the project.
We are also proud of the longitudinal screening twin and state-machine design. Instead of treating screening as a one-time event, ScreenRoute models the actual sequence of prior exams, density changes, callbacks, biopsies, and re-entry to surveillance. That makes the simulation feel much closer to real-world care.
Another accomplishment is the benefit-harm frontier itself. The app makes tradeoffs visible rather than hiding them in a single score, and it ties those tradeoffs back to guideline families and access context. We also built the platform to be open, extensible, and clinically grounded, with support for interoperable standards, simulation engines, explainability tooling, and public-data benchmarking.
What we learned
We learned that personalized screening is not just a modeling problem; it is a decision-making problem. A better risk score alone is not enough. What matters is how that information changes a screening route over time.
We also learned that prior findings and longitudinal history matter more than a static snapshot. A prior BI-RADS 3 episode, a callback pattern, or a benign biopsy history can change what the best next route looks like, even when two people have similar baseline risk factors.
Finally, we learned that access is part of the policy, not an afterthought. A route that looks optimal on paper may be a poor recommendation if transportation barriers, local screening uptake, or screening burden make follow-through unlikely. Personalization has to include feasibility.
What's next for ScreenRoute
Next, we want to strengthen calibration and benchmarking across more public and open research datasets, expand subgroup auditing, and release a more reproducible benchmark stack for route comparison. We also want to deepen uncertainty estimation and improve how confidence bands and evidence limitations are communicated in the UI.
On the product side, we plan to refine the policy comparator, patient screening twin, and county-level population explorer into a cleaner clinical research workflow. We also want to continue improving FHIR, CDS Hooks, and DICOM interoperability so the platform can plug more naturally into real health data environments.
Longer term, our goal is to make ScreenRoute a transparent, open research platform for personalized screening-policy simulation: breast cancer first, done well, with the possibility of expanding to other screening domains only after the breast cancer version is scientifically strong, interpretable, and trustworthy.
Built With
- bcrypt-(passlib)
- dowhy
- fastapi
- fhir
- hmac-sha256-audit-signing
- jwt-(python-jose)
- lightning
- mapie
- monai
- networkx
- nextjs
- pyro-ppl
- pytorch-2.3
- scikit-learn
- timm
- transformers

Log in or sign up for Devpost to join the conversation.