Inspiration
The inspiration for this project came from the need to efficiently send out research emails and collect professor email addresses. Instead of sending specific emails to each person, the idea was to streamline the process by asking for coffee chats, which seemed more effective.
What it does
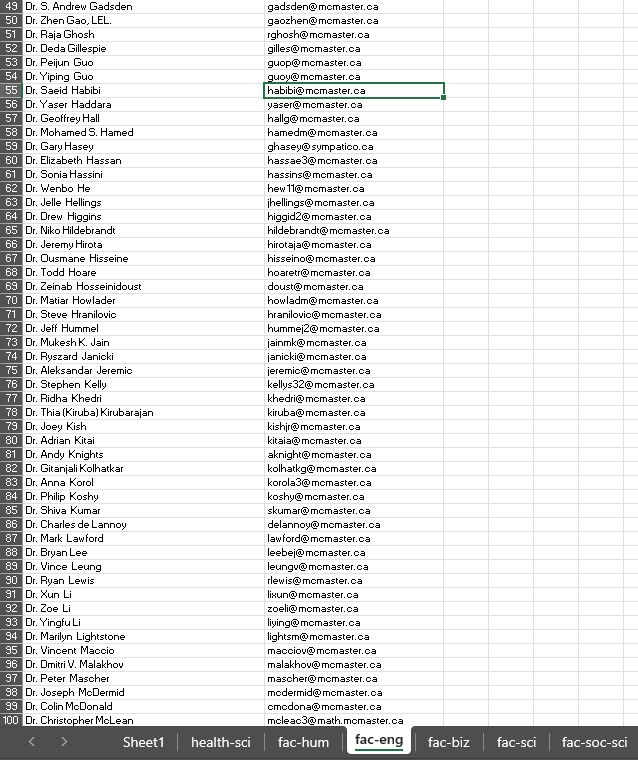
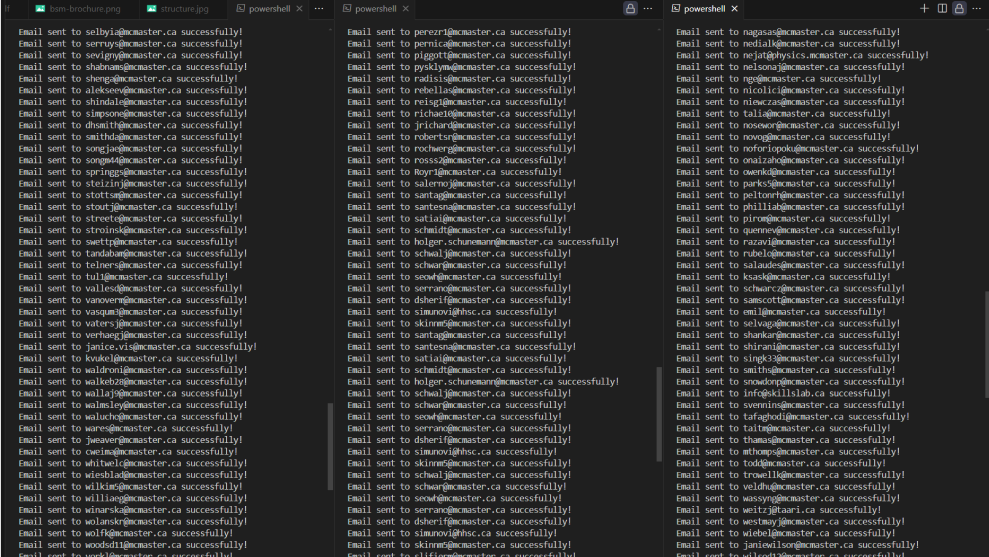
ScraPy automates the process of sending out research emails and collecting professor emails. It uses web scraping techniques to gather email addresses and automates the email-sending process.
How we built it
- Technology Stack: The project is built using Python.
- Web Scraping: Utilizes
BeautifulSoupandrequestslibraries. - Email Automation: Uses
smtplibto automate email sending. - Data Management: Stores collected emails in CSV files.
- Setup: Requires setting up a virtual environment, installing necessary packages, and configuring email settings.
Challenges we ran into
- Dynamic Content: Handling websites that use JavaScript to load content dynamically.
- Anti-Scraping Measures: Overcoming measures put in place by websites to prevent scraping.
- Email Deliverability: Ensuring emails are not marked as spam.
Accomplishments that we're proud of
- Successfully automating the email-sending process.
- Efficiently scraping professor email addresses.
- Implementing error handling to manage various issues.
What we learned
- Advanced web scraping techniques and ethical scraping practices.
- Automating tasks using Python.
- Handling and processing large datasets efficiently.
What's next for ScraPy
- Implementing an AI agent to tailor emails specifically to each professor.
- Enhancing the scraping techniques to handle more complex websites.
- Adding more features to improve the overall functionality and efficiency of the tool.
For more details, you can visit the README file.

Log in or sign up for Devpost to join the conversation.