-

Login Page
-
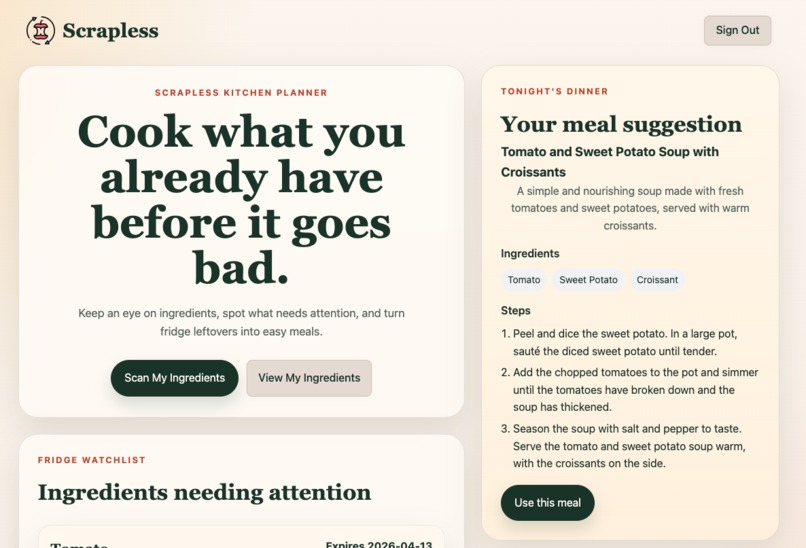
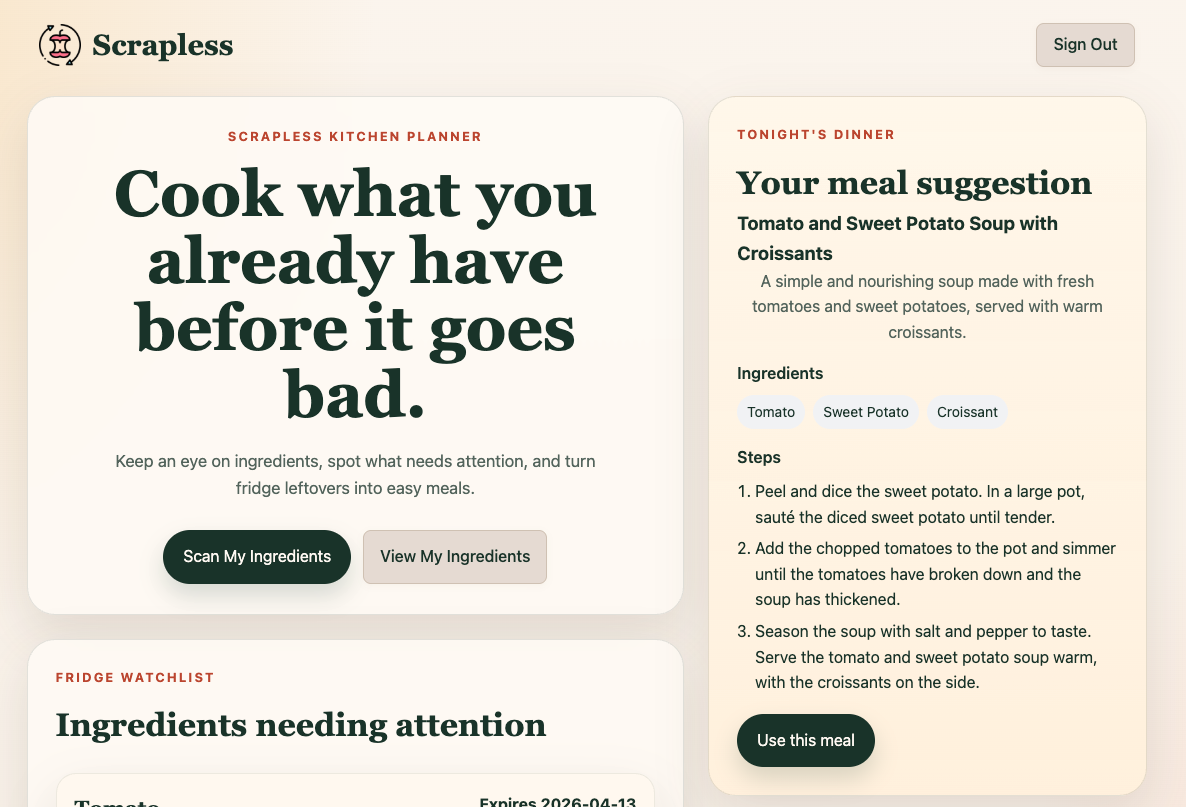
Home Page
-
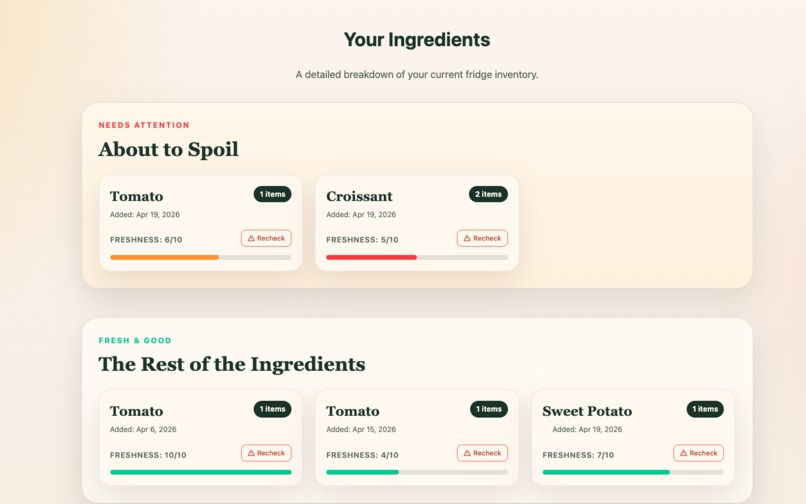
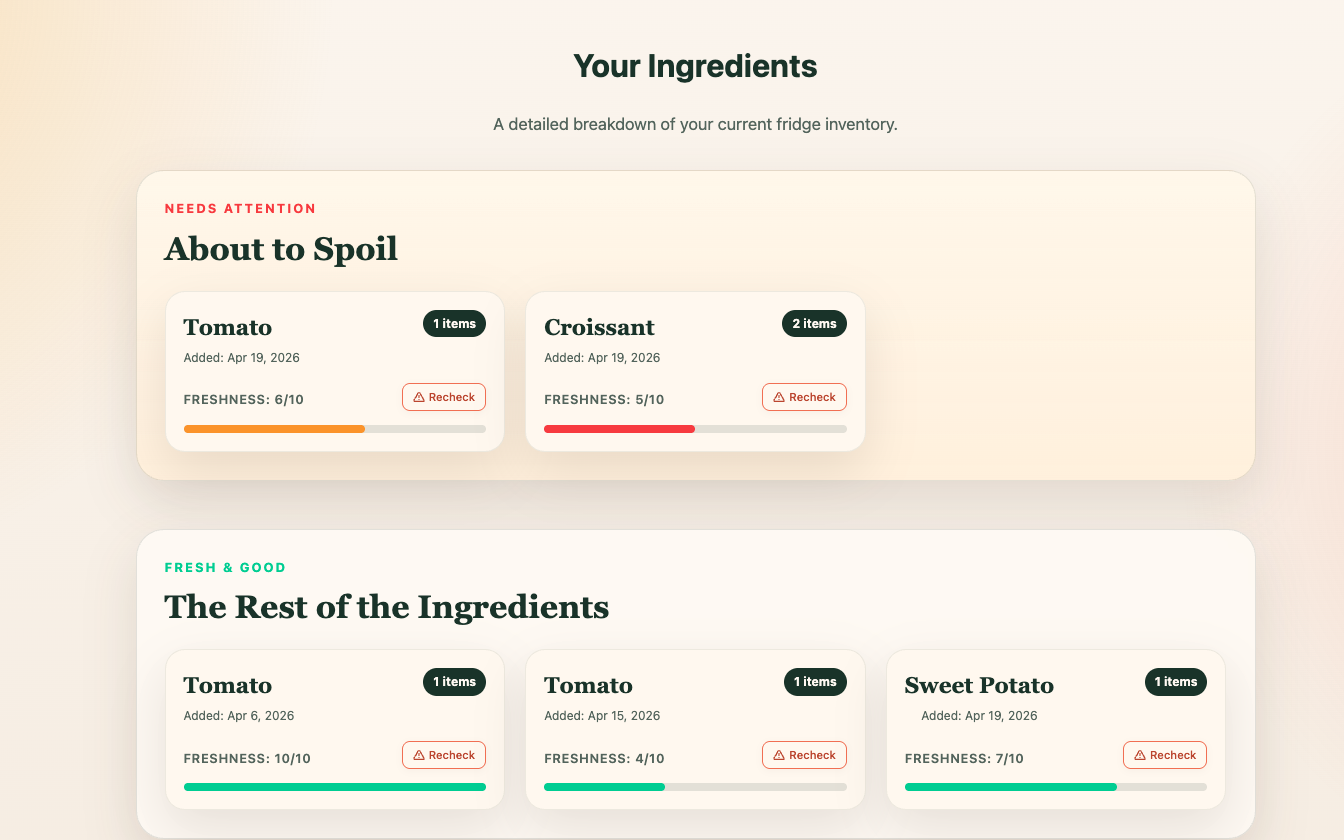
Detailed Ingredients
-
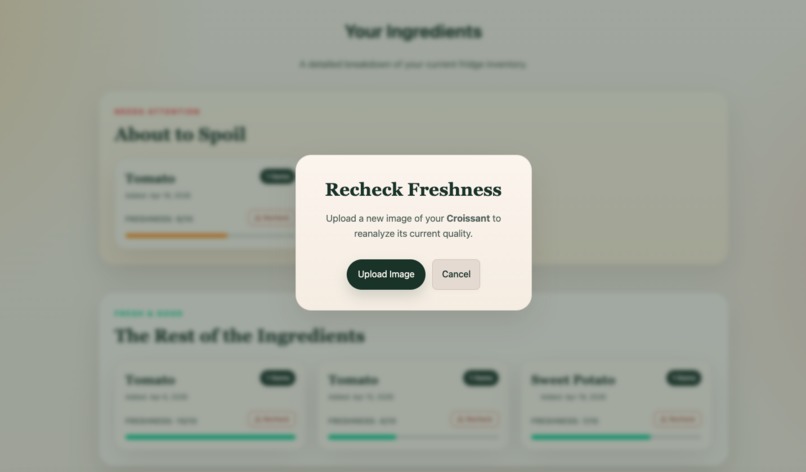
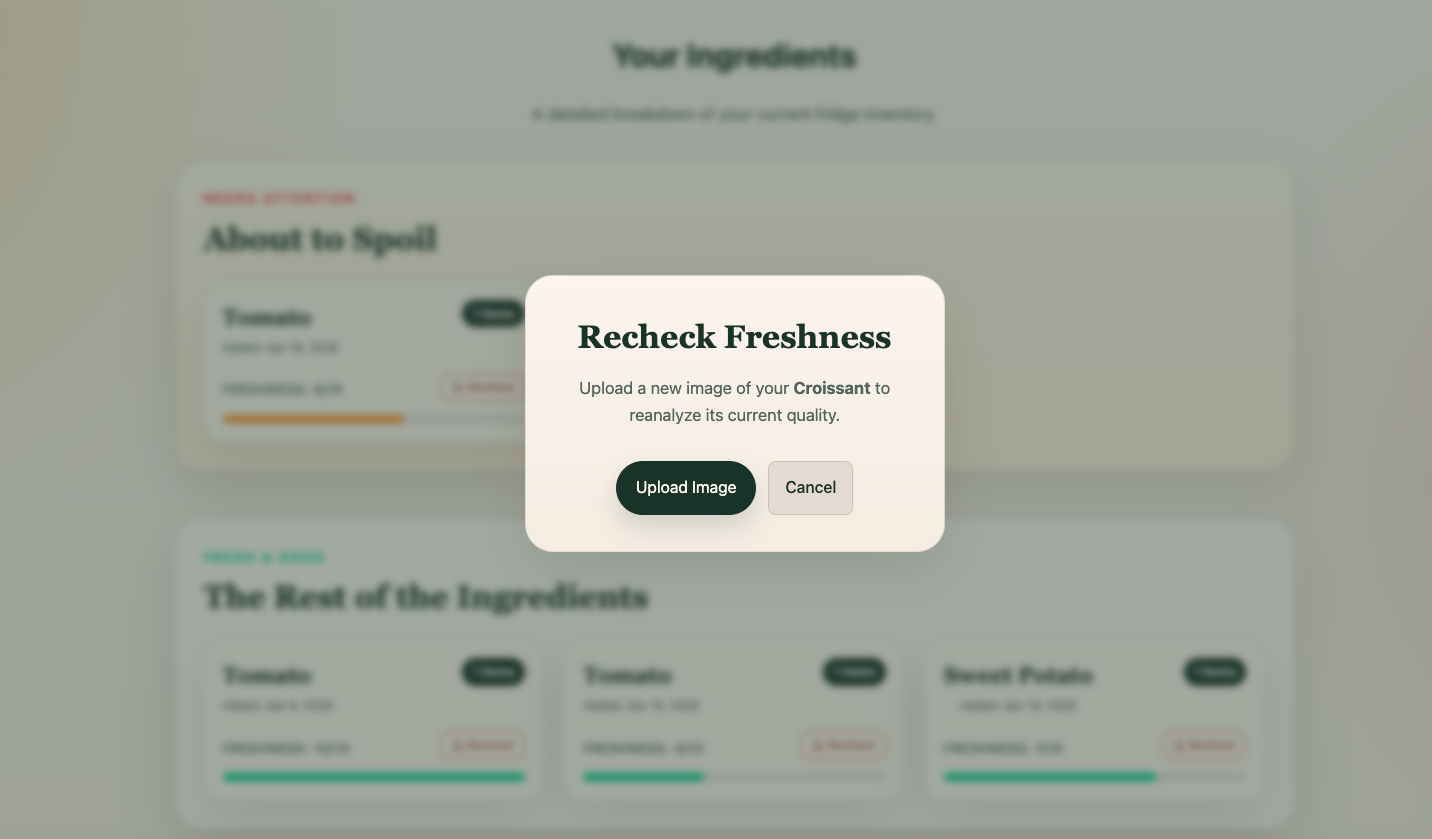
Recheck Freshness
-
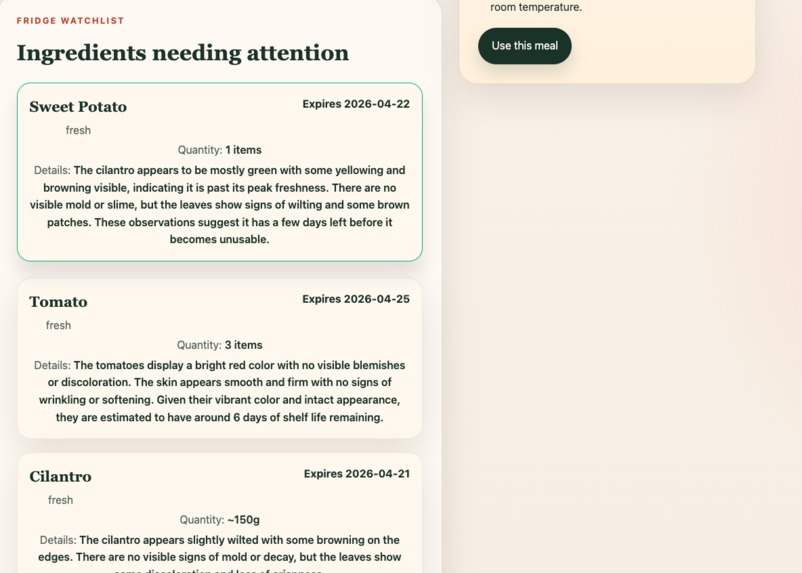
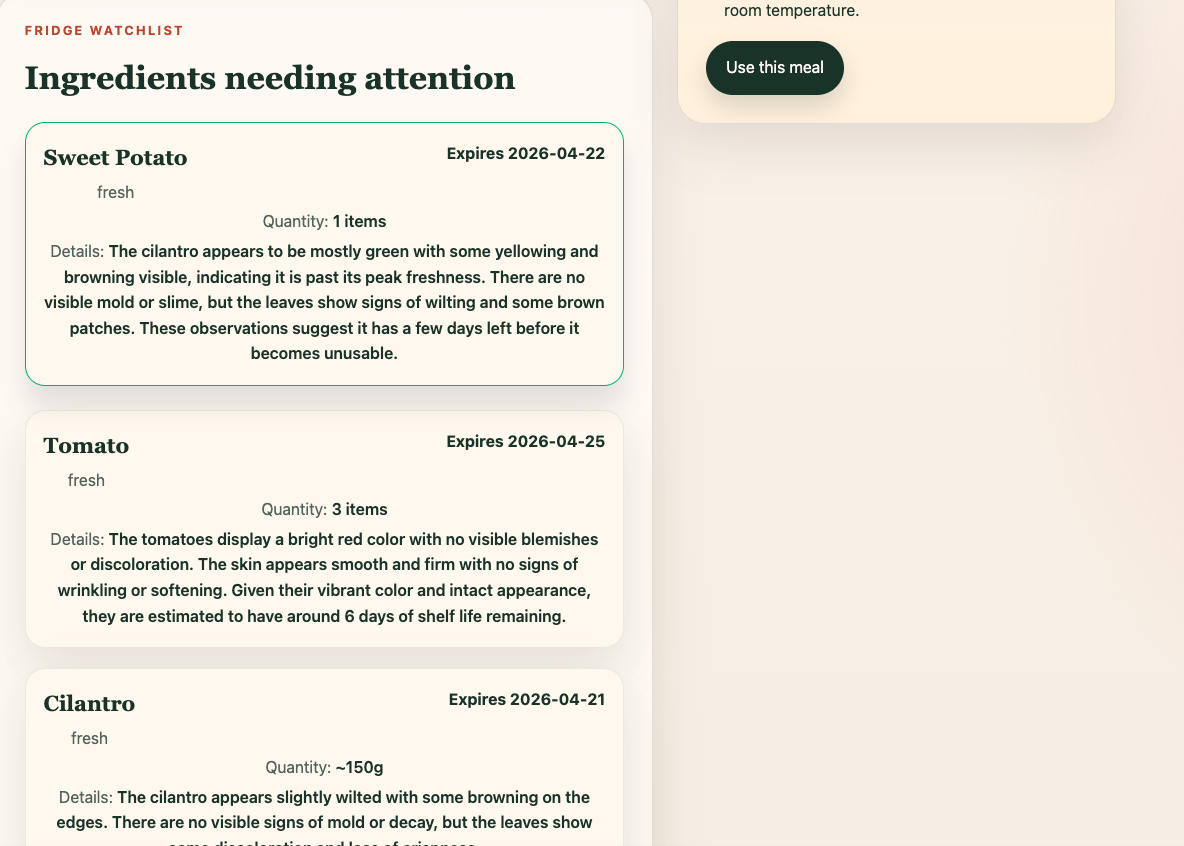
Top Ingredients Needing Attention
-
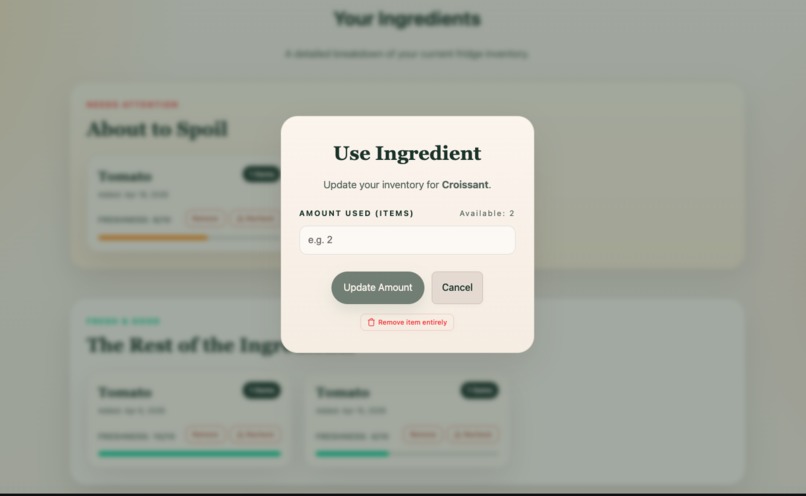
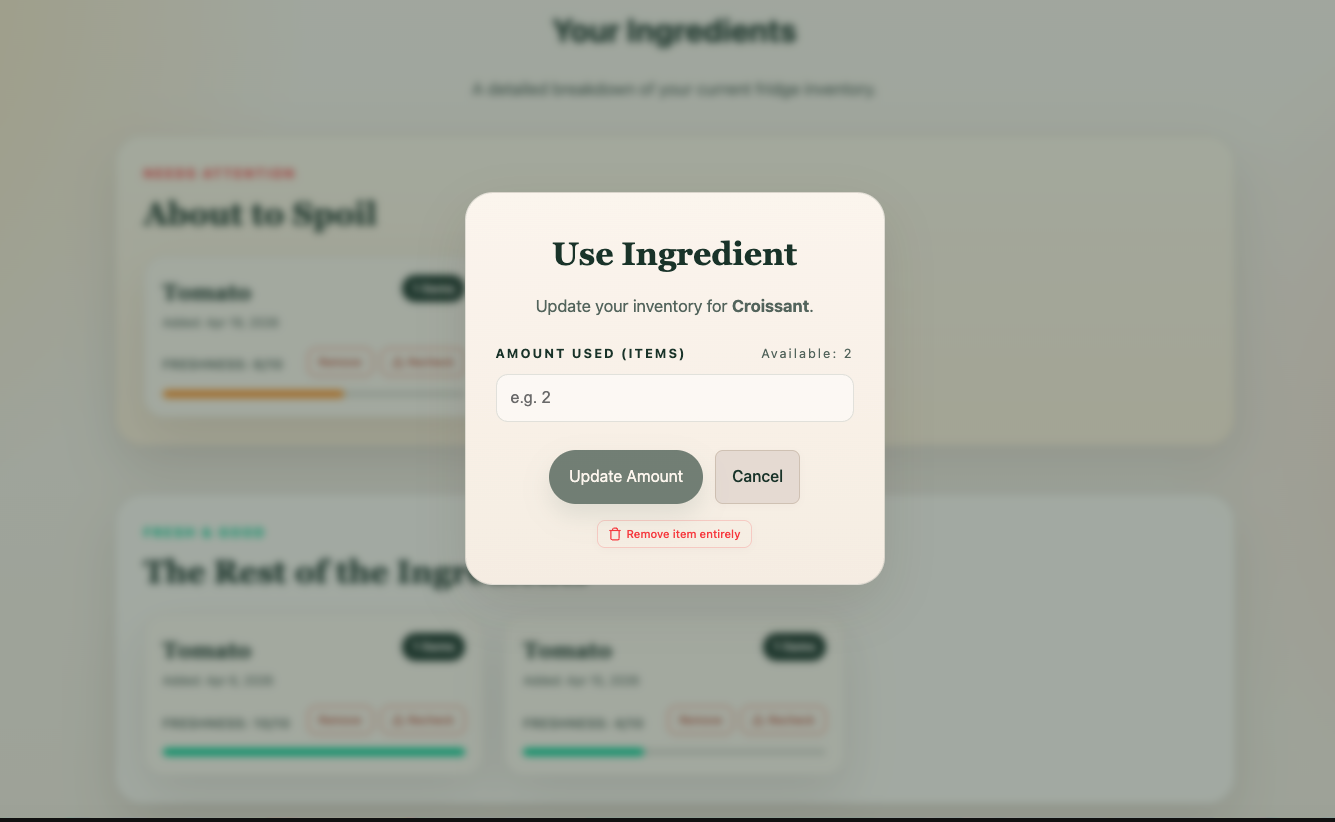
Use Ingredient

Inspiration
Food waste is a massive but often invisible problem. Most people don’t realize how much they throw away simply because they forget what’s in their fridge or don’t know what to cook with it. We wanted to build something practical, something that helps people make smarter, everyday decisions about the food they already have. Scrapless was inspired by the idea that small, consistent actions (like using ingredients before they expire) can have a meaningful impact on both cost and sustainability. Especially as college students, we wanted to make sure people are using all the ingredients they can before having to buy new ones.
What it does
Scrapless helps users track their ingredients and turn them into meals before they go bad. Users can upload ingredients, view freshness and expiration information to track their usability, and receive AI-generated meal suggestions tailored to what they already have. With a single click, they can “use” a meal, which updates their inventory and reflects what’s been used to make a meal. Ingredient freshness and expiration are dynamically updated to reflect spoilage over time. The goal is to make reducing food waste effortless and actionable.
How we built it
We built Scrapless using a full-stack architecture:
Frontend: React for a responsive, interactive UI
Backend: AWS Lambda + API Gateway for scalable serverless APIs, Python
Database: AWS DynamoDB to store user ingredients and metadata
AI Integration: Amazon Bedrock (Claude) to generate meal suggestions from available ingredients
Storage & Processing: Image and ingredient processing pipelines to structure user inputs
Deploying: AWS Amplify
Challenges we ran into
The biggest challenges came from debugging the integration of the frontend, backend, and API’s. If there was an issue with button functionality, we would not only have to check the frontend and backend, but also the cloud services in AWS. For example, ensuring that when an image is uploaded, the correct ingredients are added to the database and immediately reflected in the homepage UI requires multiple layers of coordination. We had initially attempted to use Amazon Rekognition to analyze user-uploaded images, but it proved to be slow and inefficient, so we switched to fully using Amazon Bedrock.
Accomplishments that we're proud of
Being able to understand AWS and pick out the right services to take advantage of allowed us to see the value in cloud computing. Additionally, we are all very proud of creating a meaningful product with a use case that may extend beyond being a project made for a hackathon, potentially helping others in the near future.
What we learned
One of the biggest things we learned from this project was how to build and integrate a full-stack application using cloud services. Instead of a traditional backend server, we used AWS Lambda functions connected through API Gateway with DynamoDB as the database, which helped us understand how modern applications can be broken into scalable, independent services that communicate through APIs. I also learned how important it is to design clear API contracts, since even small mismatches between the frontend and backend can break functionality, and how to properly manage asynchronous data flow to keep the UI consistent with the database.
What's next for Scrapless
- Recommending ways to conscientiously dispose expired/spoiled food items
- Be able to “Use” a meal, automatically deleting the items from the database
- Improve freshness predictions and prioritization
- Introduce shopping suggestions based on missing ingredients using Amazon Personalize
- Tailor meal recommendations by cuisine, nutrition, and other personal preferences
- Add user authentication on individual accounts for long-term tracking of food waste reduction
Built With
- amazon-amplify
- amazon-api-gateway
- amazon-bedrock
- amazon-dynamodb
- amazon-lambda
- amazon-web-services
- javascript
- lambda
- node.js
- python
- react


Log in or sign up for Devpost to join the conversation.