-
-
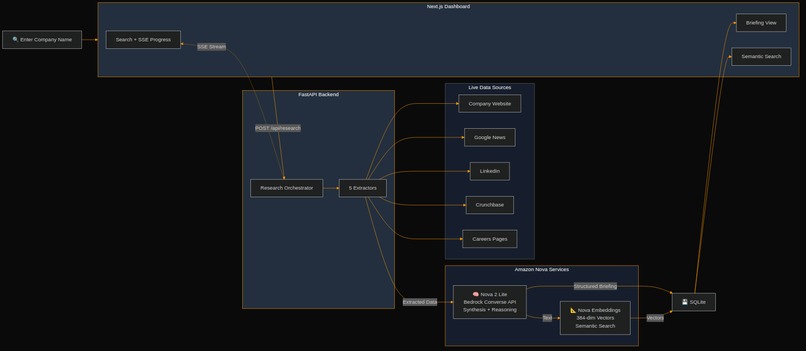
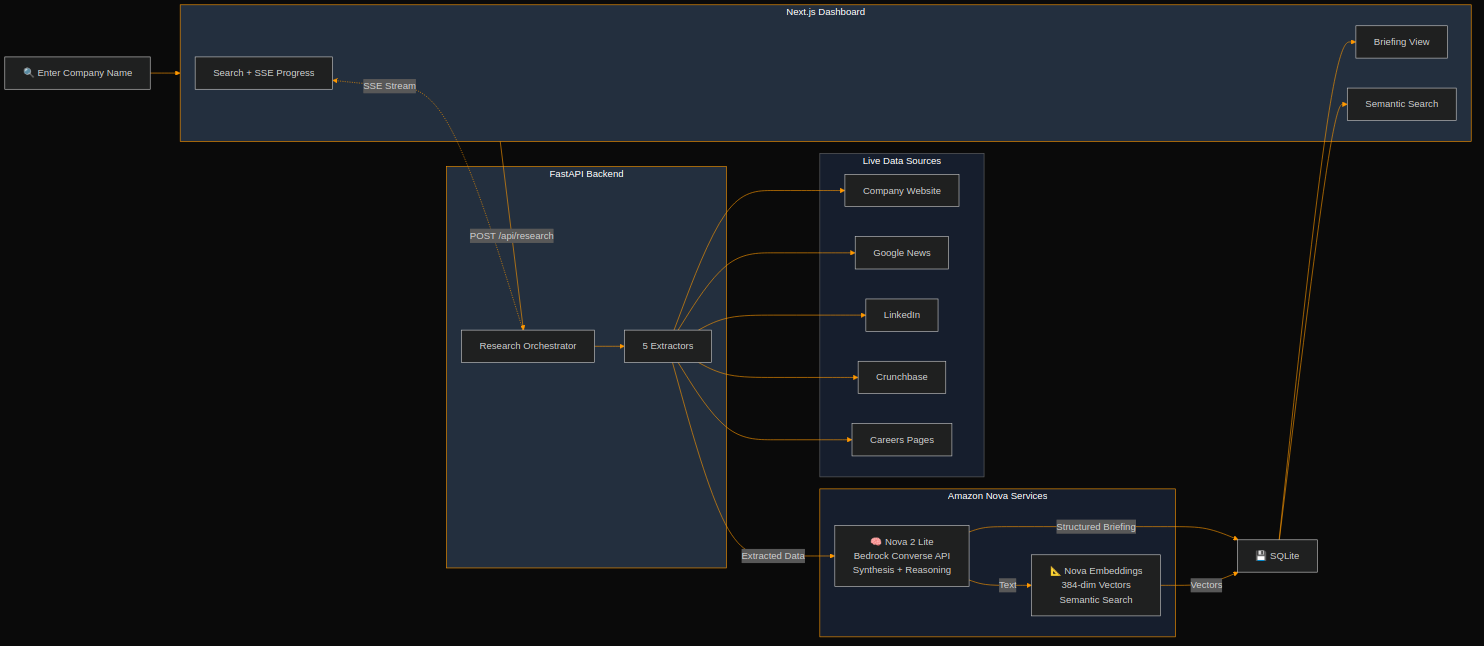
Architecture
-
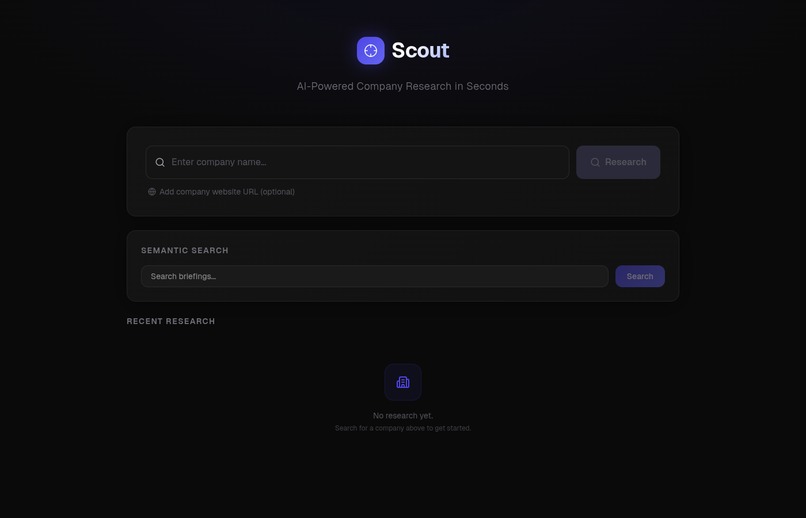
Front page
-
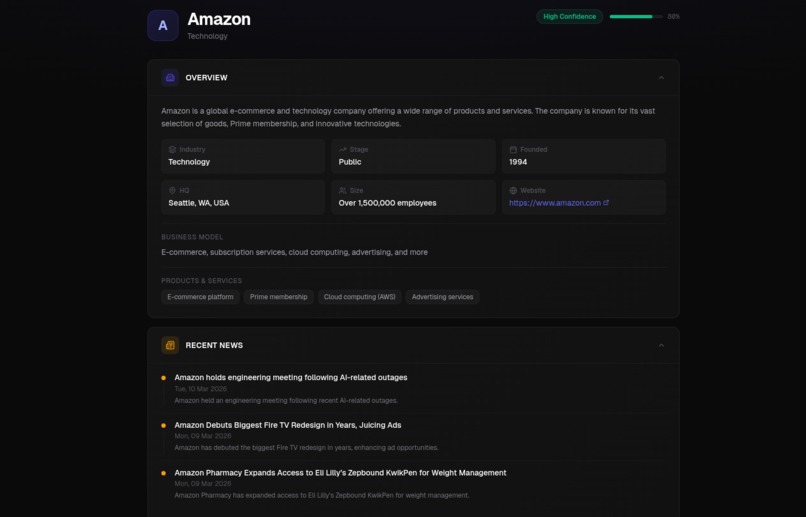
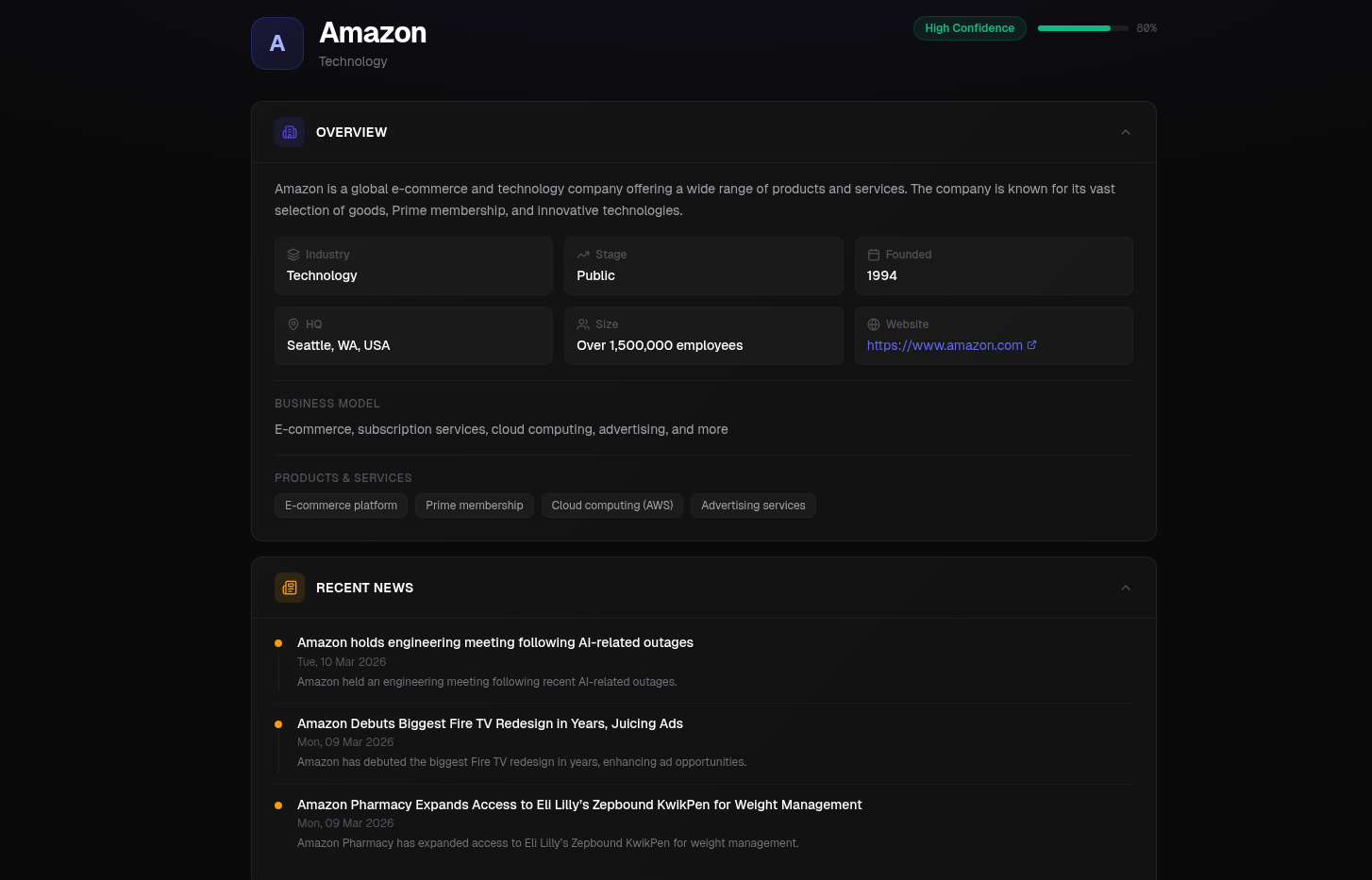
Example company research (amazon!)
Scout: AI Company Research Agent
AmazonNova
Please try it out! https://frontend-murex-eta-95.vercel.app/
Inspiration
Every sales rep I've watched does the same thing before a call: 30 minutes of frantic tab-switching between LinkedIn, Crunchbase, Google News, and the company website, copy-pasting into a doc they'll glance at once. For a 20-person team making 5-8 calls a day, that's 50-80 hours a week spent on research that should take seconds. I wanted to build the tool that makes that entire ritual obsolete.
What It Does
Type a company name. In 90 seconds, Scout sends AI agents to browse real websites (the company homepage, LinkedIn, Crunchbase, Google News, and job boards) then synthesizes everything into a structured briefing with key people, recent news, tech stack, growth signals, and tailored talking points. Every briefing is automatically embedded for semantic search, so your research library gets smarter over time.
Deep Nova Integration: Two Amazon Nova Services Working Together
Scout is built around two Amazon Nova services that form a complete reasoning-and-memory pipeline:
1. Nova 2 Lite: AI Synthesis (Bedrock Converse API)
After five browser agents extract raw data from the web, Amazon Nova 2 Lite (model ID: us.amazon.nova-lite-v1:0) synthesizes everything into a structured JSON briefing. Called via boto3's client.converse() with temperature 0.1 and maxTokens 2048, Nova 2 Lite cross-references data across sources, resolves conflicts, identifies growth signals, and produces a structured output with:
- Executive summary
- Key people and leadership
- Recent news highlights
- Tech stack fingerprint
- Growth signals
- Competitive landscape
- Three tailored conversation starters
2. Nova Multimodal Embeddings: Semantic Search (Bedrock InvokeModel API)
Every briefing is automatically embedded using Amazon Nova Multimodal Embeddings (model ID: amazon.nova-multimodal-embedding-v1:0) via client.invoke_model(). This creates 384-dimensional embedding vectors stored alongside each briefing in SQLite.
- Indexing: Uses
GENERIC_INDEXpurpose, every briefing is embedded on creation - Search: Uses
TEXT_RETRIEVALpurpose, query text is embedded and compared against all stored briefings via pure Python cosine similarity - No external vector DB needed, lightweight, self-contained semantic search
Example: Searching "find companies in AI safety" ranks Anthropic highest, not because the word "Anthropic" appears in the query, but because the embedding space captures semantic meaning.
How It Works
- The user enters a company name in the Next.js 14 frontend.
- The backend creates a research job and returns a job ID. The frontend subscribes to a Server-Sent Events stream for live progress.
- Five browser agents launch in parallel, each targeting a different source: the company website, Google News, LinkedIn, Crunchbase, and career/job pages.
- Each agent extracts structured information from real websites, no stale training data.
- When all five agents finish, the combined data is sent to Nova 2 Lite via the Bedrock Converse API for synthesis.
- Nova 2 Lite produces a structured JSON briefing.
- The briefing is immediately embedded using Nova Multimodal Embeddings and stored for semantic search.
- The frontend renders the full briefing with real-time progress updates.
How I Built It
Backend: FastAPI (Python 3.11+). Research orchestration runs as a background task via FastAPI's BackgroundTasks, pushing ProgressEvent objects to an asyncio.Queue that the SSE endpoint drains.
Nova 2 Lite synthesis: boto3 bedrock-runtime client, client.converse(), model us.amazon.nova-lite-v1:0, temperature 0.1, maxTokens 2048. The prompt includes all extracted data as formatted text and requests JSON output matching a strict Pydantic schema. Post-processing strips markdown fences before JSON parsing.
Nova Multimodal Embeddings: boto3 bedrock-runtime client, client.invoke_model(), model amazon.nova-multimodal-embedding-v1:0. Indexing uses GENERIC_INDEX purpose; search queries use TEXT_RETRIEVAL purpose. Cosine similarity computed in pure Python, no external vector database.
SSE pipeline: The frontend connects to GET /api/research/{id}/stream immediately after the POST. The backend pushes events at each extraction stage (progress 15%, 30%, 50%, 65%, 80%), at synthesis start (90%), and at completion (100%). A None sentinel closes the stream.
Graceful degradation: If any extractor fails (LinkedIn blocks the request, Crunchbase paywalls the data), the pipeline continues. The synthesis prompt receives explicit "[FAILED: reason]" markers and adjusts the confidence score accordingly. Minimum viable output requires only the company website and Google News.
Storage: aiosqlite for async SQLite access. Pydantic models serialize to JSON columns. Full research history and all embedding vectors queryable via GET /api/history.
Frontend: Next.js 14 with server components, Tailwind CSS, and a custom SSE hook for real-time progress rendering.
Challenges I Faced
Nova Act is geo-restricted to US-based developers. Since I'm based in Australia, I couldn't get an API key. Rather than give up, I built a three-tier fallback system: Nova Act (when available), HTTP extraction with BeautifulSoup + Bedrock synthesis (current production mode), and mock data (for development). The extractors are architected identically regardless of mode. Swapping in Nova Act is a one-line config change when access opens up.
Getting five parallel web extractors to degrade gracefully was harder than expected. LinkedIn blocks automated requests, Crunchbase paywalls data, and company websites have wildly different structures. The synthesis prompt had to handle partial data intelligently, marking failed sources explicitly so Nova 2 Lite adjusts confidence accordingly rather than hallucinating missing information.
What I Learned
Building semantic search from scratch (no Pinecone, no external vector DB) taught me how much you can do with Nova Multimodal Embeddings + cosine similarity in pure Python. The 384-dimensional vectors are surprisingly good at capturing meaning. Searching "AI safety companies" correctly ranks Anthropic first without any keyword matching. Sometimes the simplest architecture wins.
I also learned the value of designing for failure from the start. Every extractor can fail independently without taking down the pipeline. This graceful degradation pattern, where the AI explicitly knows what data it's missing, produces more honest and trustworthy output than systems that silently fill gaps.
Impact
Scout compresses 30-60 minutes of manual research into approximately 90 seconds. For a 20-person sales team, that recovers 50-80 hours per week. The briefings are consistent and comprehensive: every research job checks the same five sources and produces the same structured output. The talking points are grounded in real findings (specific news articles, actual job postings, confirmed tech stack) not generic templates.
The semantic search layer means the research library compounds in value over time. As more briefings accumulate, "find companies with recent funding rounds" or "show me enterprise software companies in fintech" surfaces the right results instantly.
Extensions
I'd love to spend more time to make this system more robust, and extra hands on help with this!
Try It Out: Live Deployment
Scout is fully deployed and running in production:
- Frontend: https://frontend-murex-eta-95.vercel.app, enter any company name and get a full research briefing in ~90 seconds.
- Backend API: https://scout-api.astraedus.dev, live on AWS EC2 with interactive Swagger docs at https://scout-api.astraedus.dev/docs
- Source code: https://github.com/astraedus/scout
Both are running in production with real Amazon Bedrock integration: Nova 2 Lite (us.amazon.nova-lite-v1:0) for synthesis and Nova Multimodal Embeddings (amazon.nova-multimodal-embedding-v1:0) for semantic search.
Built With
- act
- amazon
- bedrock
- events
- fastapi
- next.js
- nova
- python
- server-sent
- sqlite
- typescript




Log in or sign up for Devpost to join the conversation.