-
-
Data visualizer
-

System architecture
Inspiration
A global pandemic has changed peoples lives in 2020. We are surrounded by statistical data about the virus - number of active cases, number of deaths, number of recovered patients... But how do people actually feel? How today's news affects people in different regions? How they react to the virus on social media? Let us model these scenarios from live data and help media companies to feel closer to the crowd.
What it does
The project is split into 2 main parts:
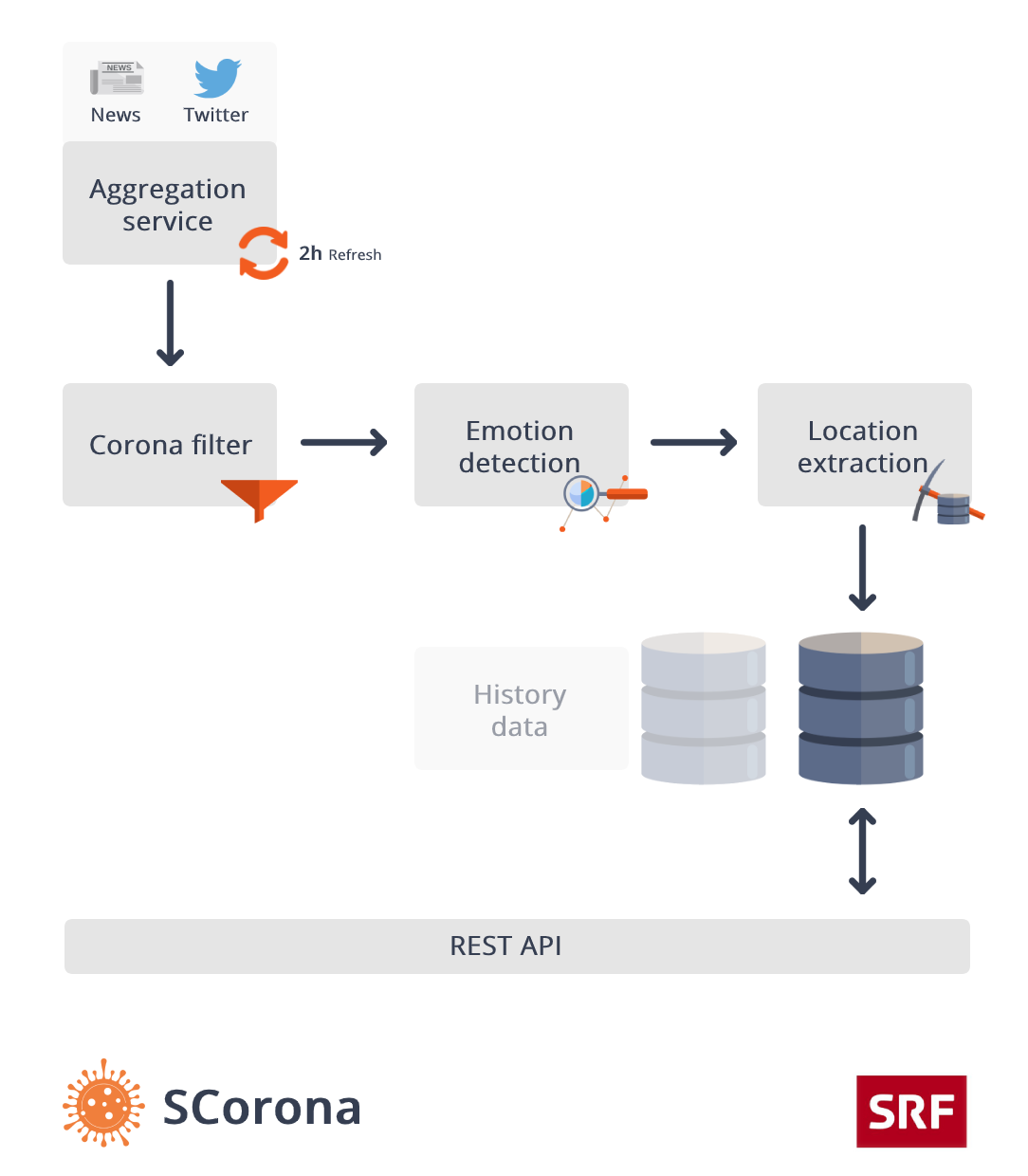
Data provider
- Aggregation service - Fetches every 2 hours news data from various sources and fetches prefiltered twitter posts.
- Corona filter - Removes all non-coronavirus related data samples.
- Emotion detection - Pre-trained model to classify positivity / negativity of each news item.
- Location extraction - Detects location information in each data sample (the UK only) and aggregates them by larger geolocation (UK counties).
- DB - Processed metadata are cached in the database until new aggregation fetch is performed.
- REST API - Provides access to processed data to allow further processing or visualization.
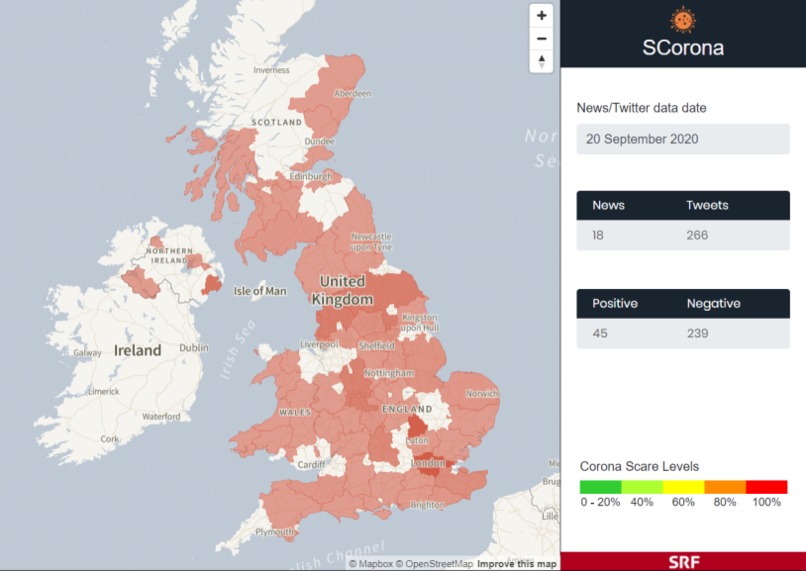
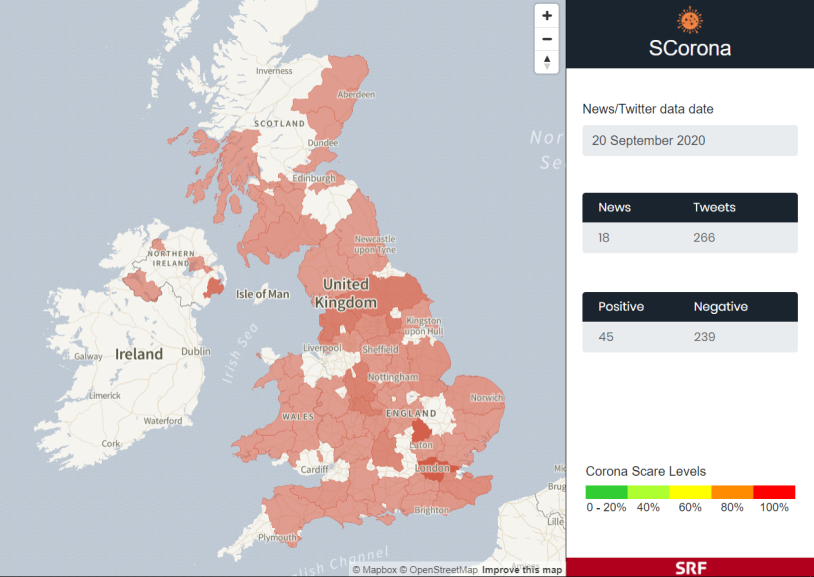
Data visualizer
Static web front-end to visualize live model of peoples emotional response to the global pandemic. A larger area (eg. county) has certain opacity and colour. The amount of opacity value corresponds to the intensity of news related to coronavirus in that area. Colour denotes average emotion in that area related to the virus - the value can be any between green and red (green being positive, red being negative).
How I built it
Data provider
The layer is written in Python.
- Aggregation service - RSS is used for news access (BBC, DailyMail, SkyNews). Additionally, full article bodies are fetched for more precise location extraction and possibly emotion detection. Twitter API is used for accessing twitter posts.
- Corona filter - Text scanning using numpy
- Emotion detection - Pre-trained XLNet - fine-tuned with 25000 samples of IMDb reviews (no more appropriate dataset available). Binary classifier (positive / negative).
- Location extraction - Offline city matching with correlation to counties. Majority voting when multiple cities occurred. Edge case handling (too many cities => correlate to the whole country).
- DB - MongoDB Atlas
- REST API - Python Flask. Fetching cached data from DB.
Data visualizer
Mapbox API with custom polygon layers. AJAX requests to REST API.
Challenges I ran into
The actual performace of XLNet model on news and twitter posts was mostly not very good (misclassification). Fine-tuning of the model took more than 5 hours, which slowed us down.
Accomplishments that I'm proud of
Working prototype and functional data processing pipeline with live data.
What I learned
How to work and fine-tune XLNet model. Difficulties of data analysis and data processing. Data storage in NoSql (MongoDB Atlas).
What's next for SCorona
History data (infrastructre prepare), more data sources and correlations (eg. increase/decrease of COVID-19 cases) and more available areas (outside the UK).

Log in or sign up for Devpost to join the conversation.