-
-
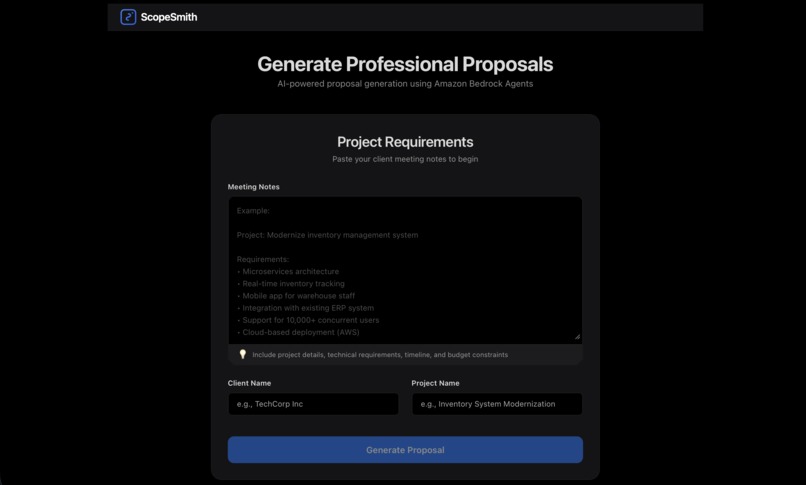
Home page
-
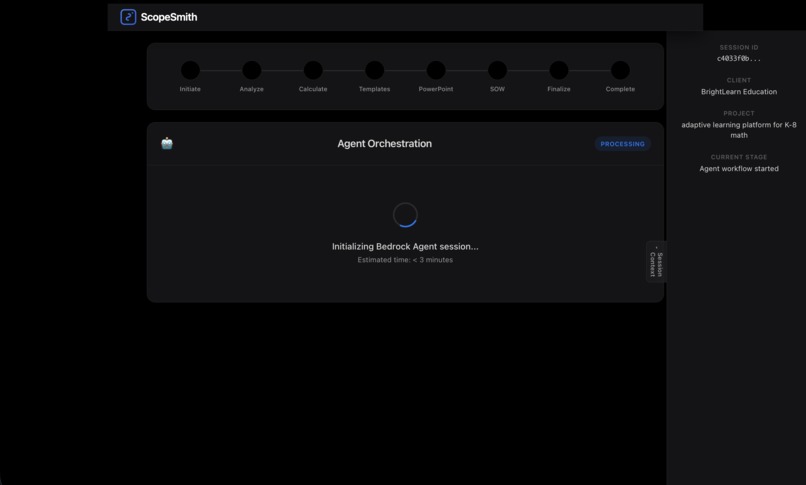
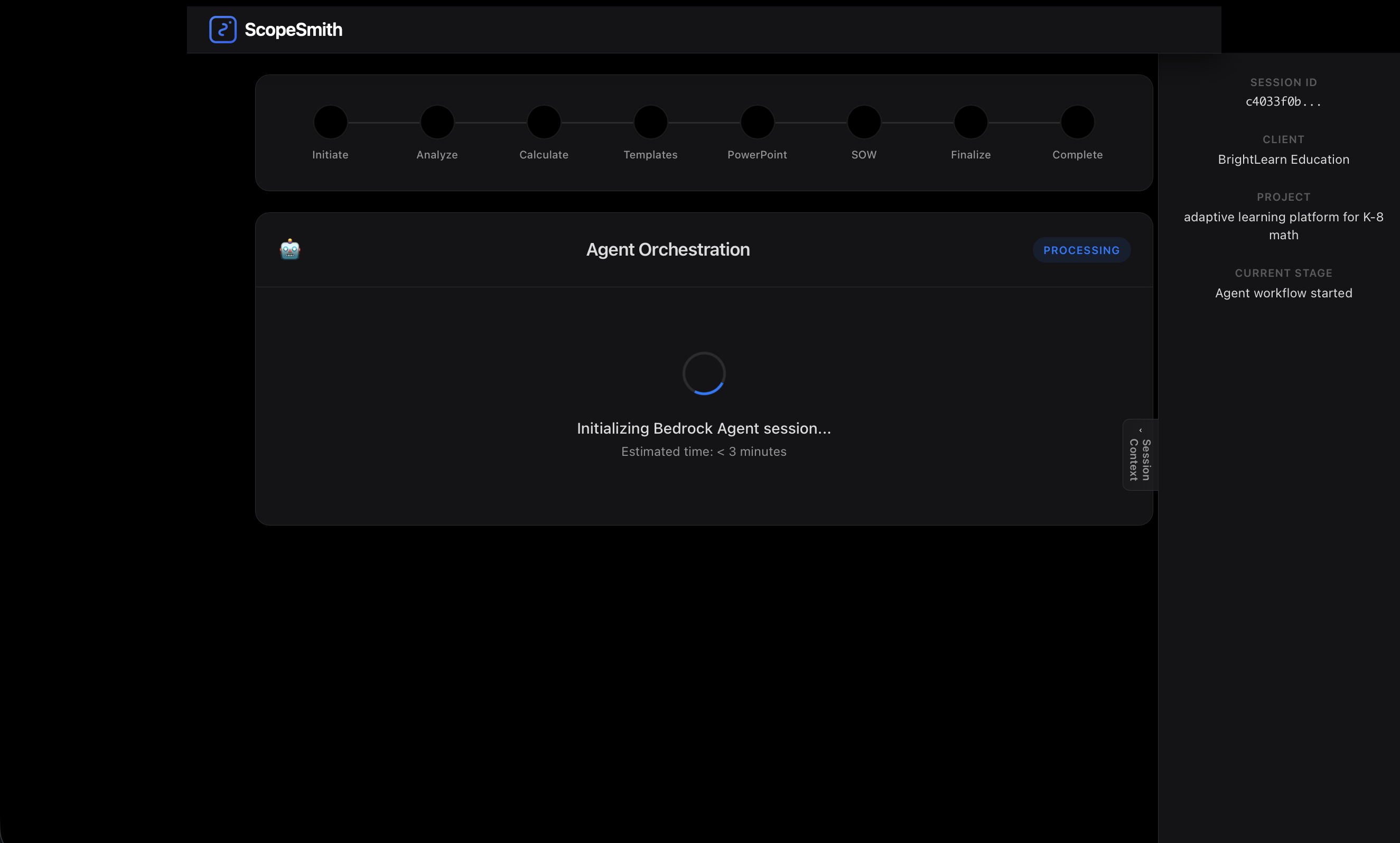
agent initiated
-
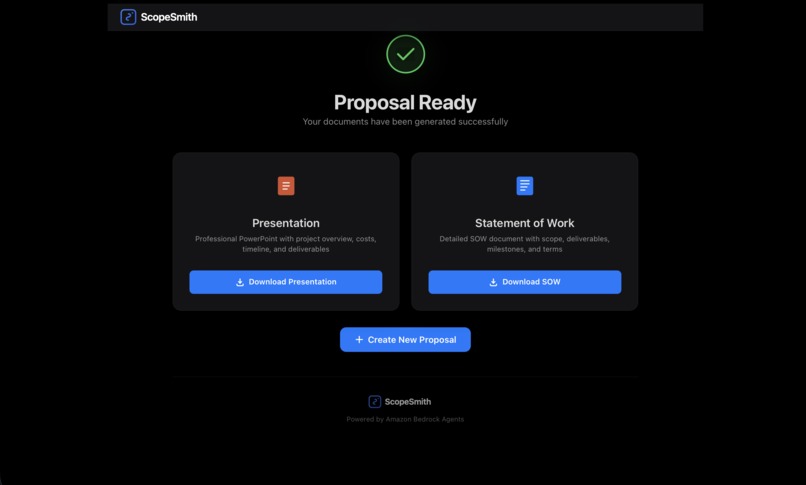
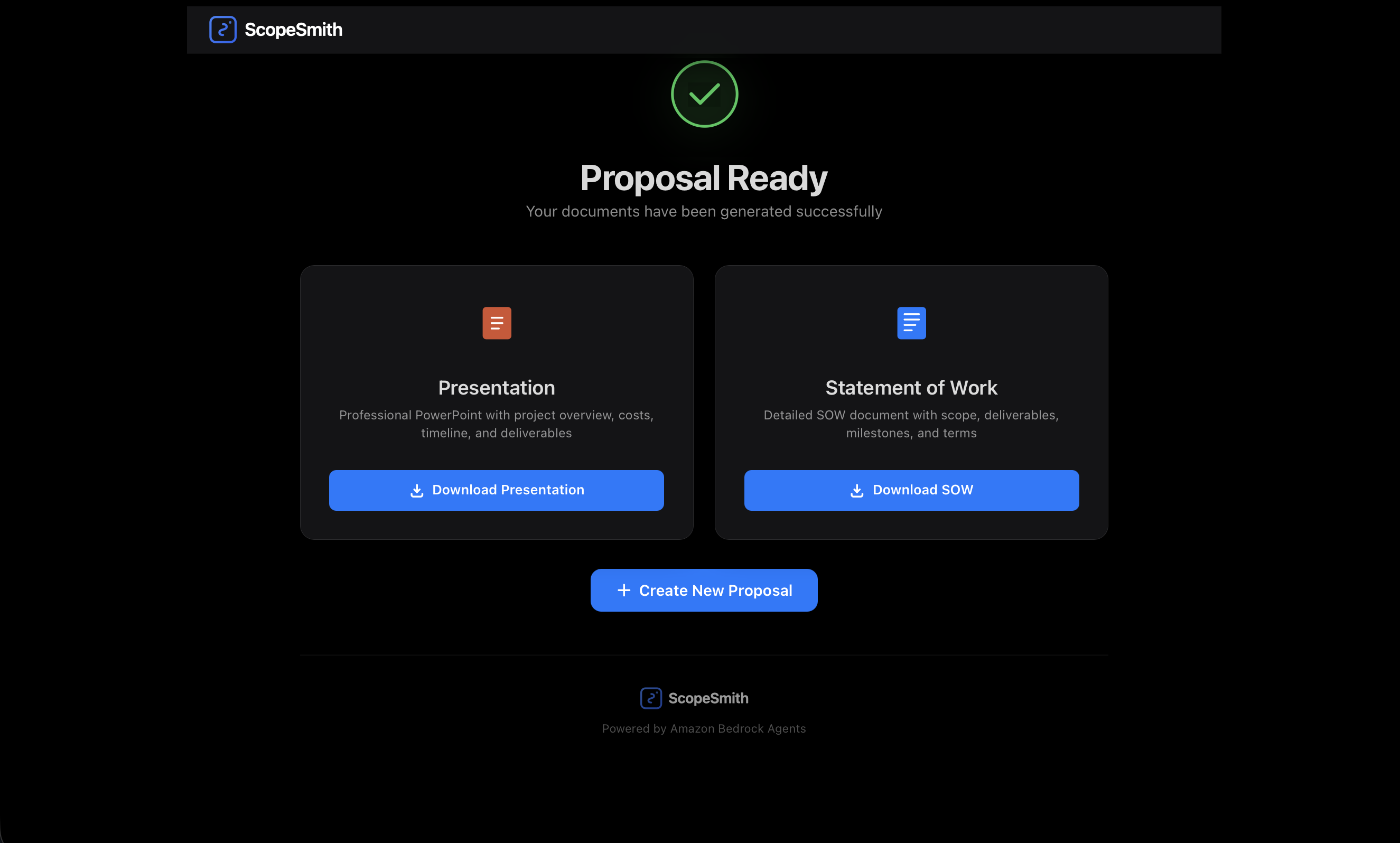
final success page
-
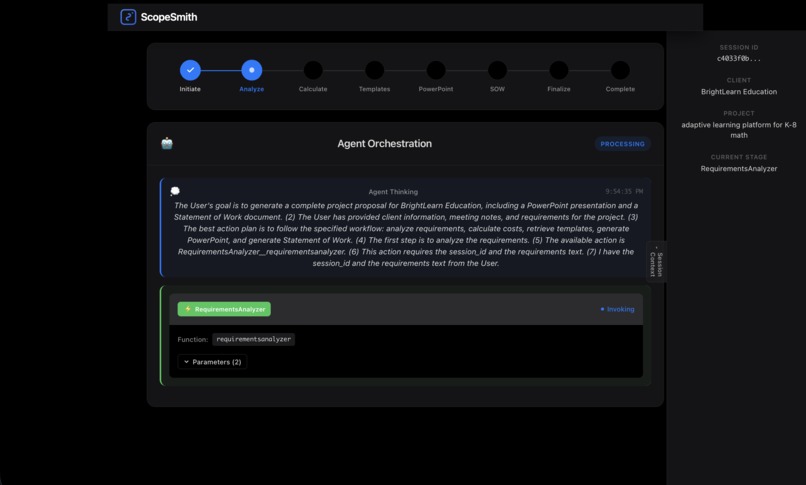
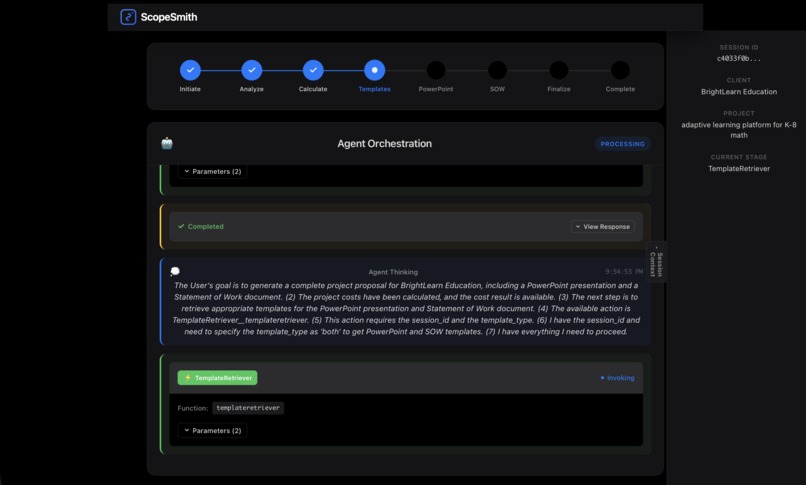
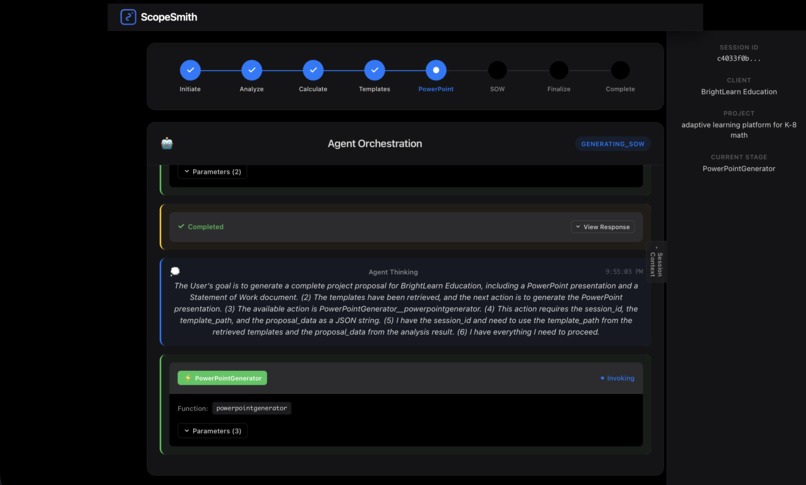
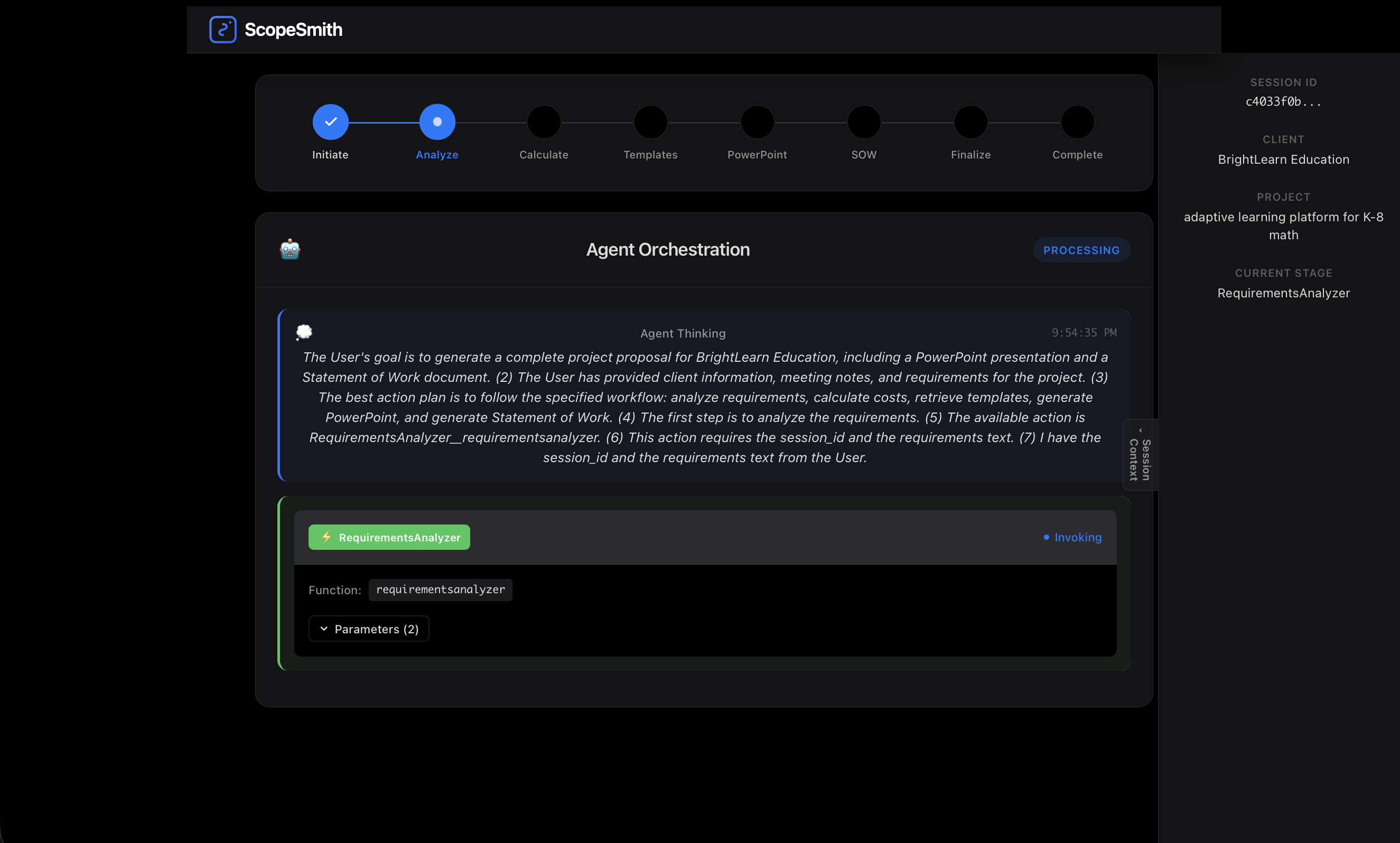
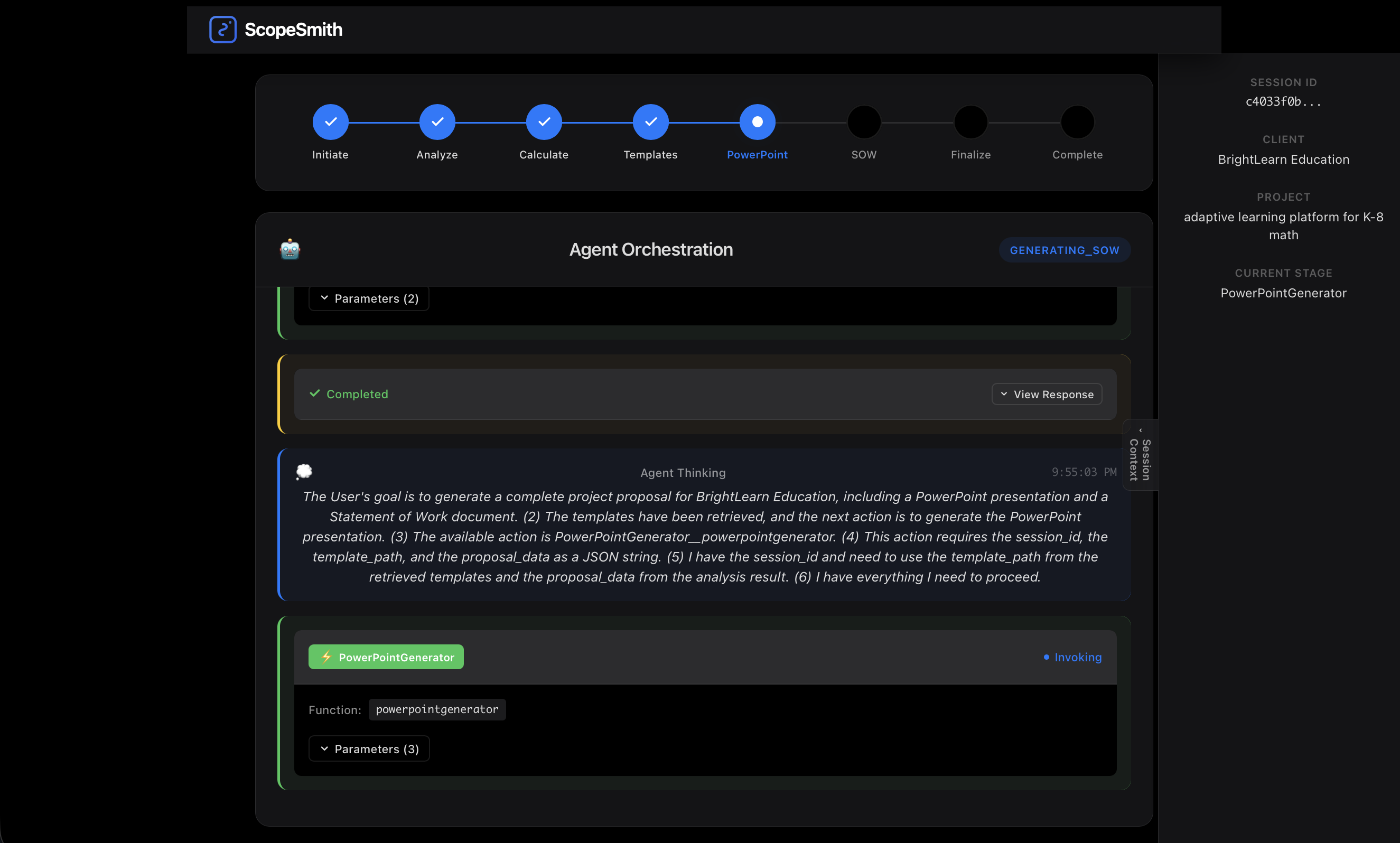
agent orchestration process
-
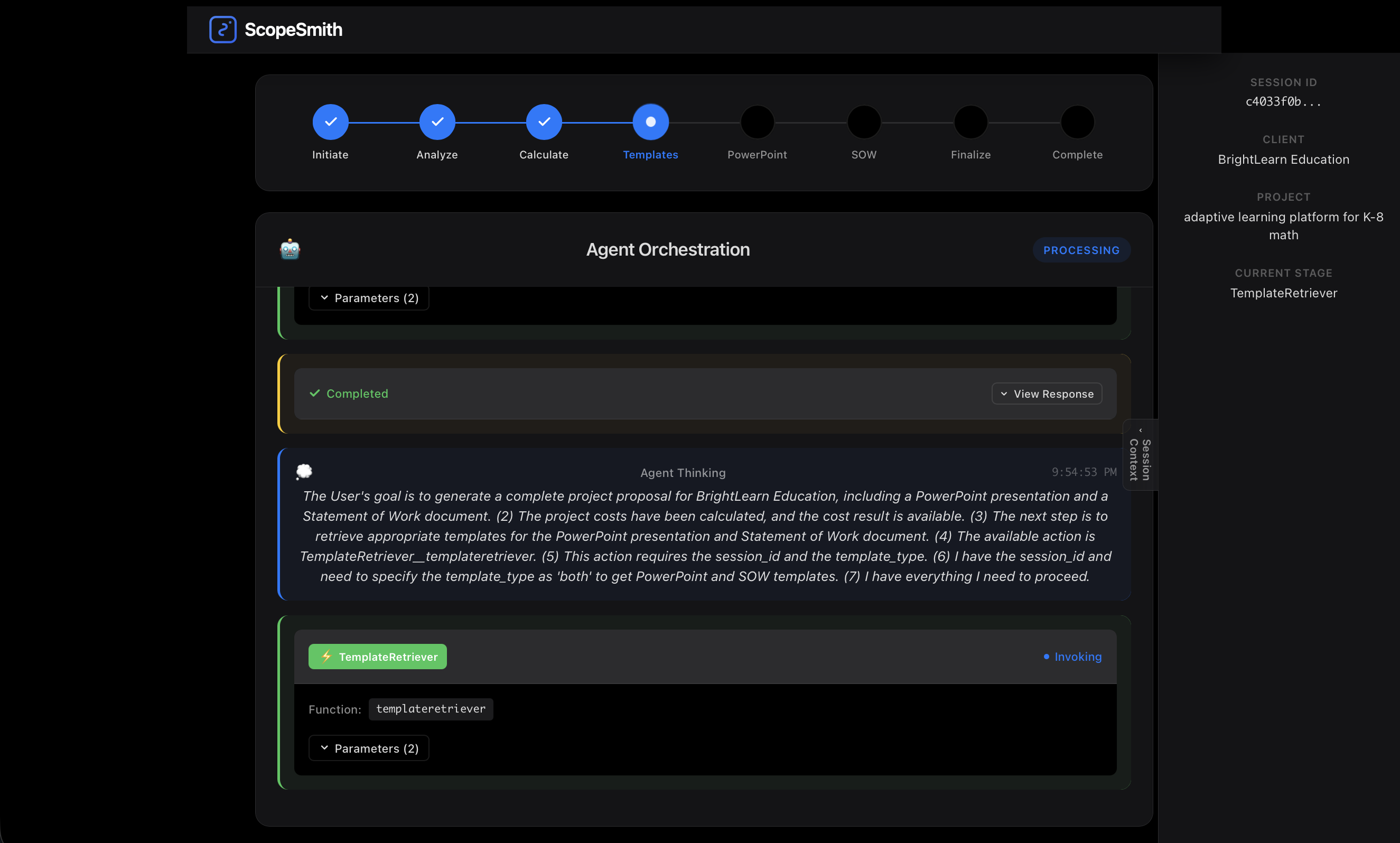
step by step process
-
step by step process
-
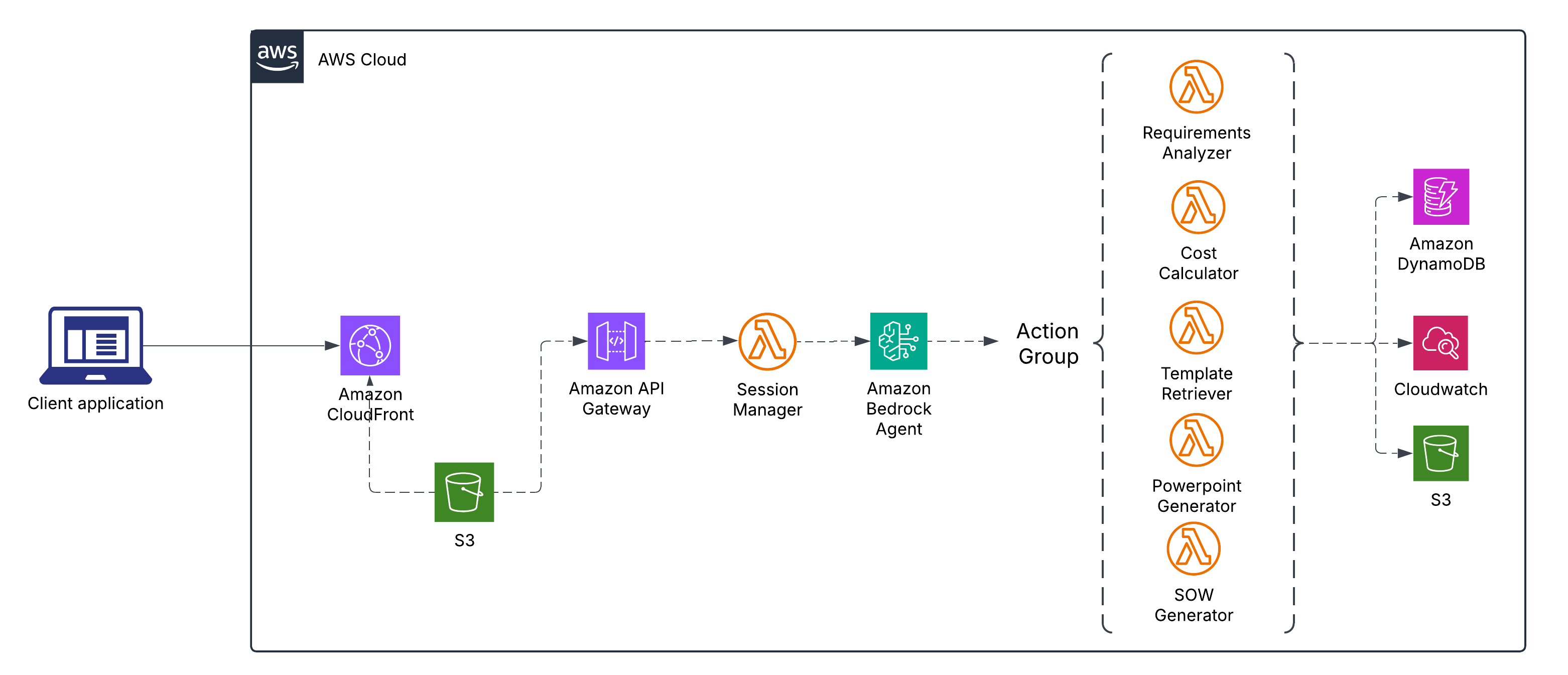
Architecture Diagram
ScopeSmith: AI-Powered Proposal Generation
AWS AI Agent Hackathon Project Story
What It Does
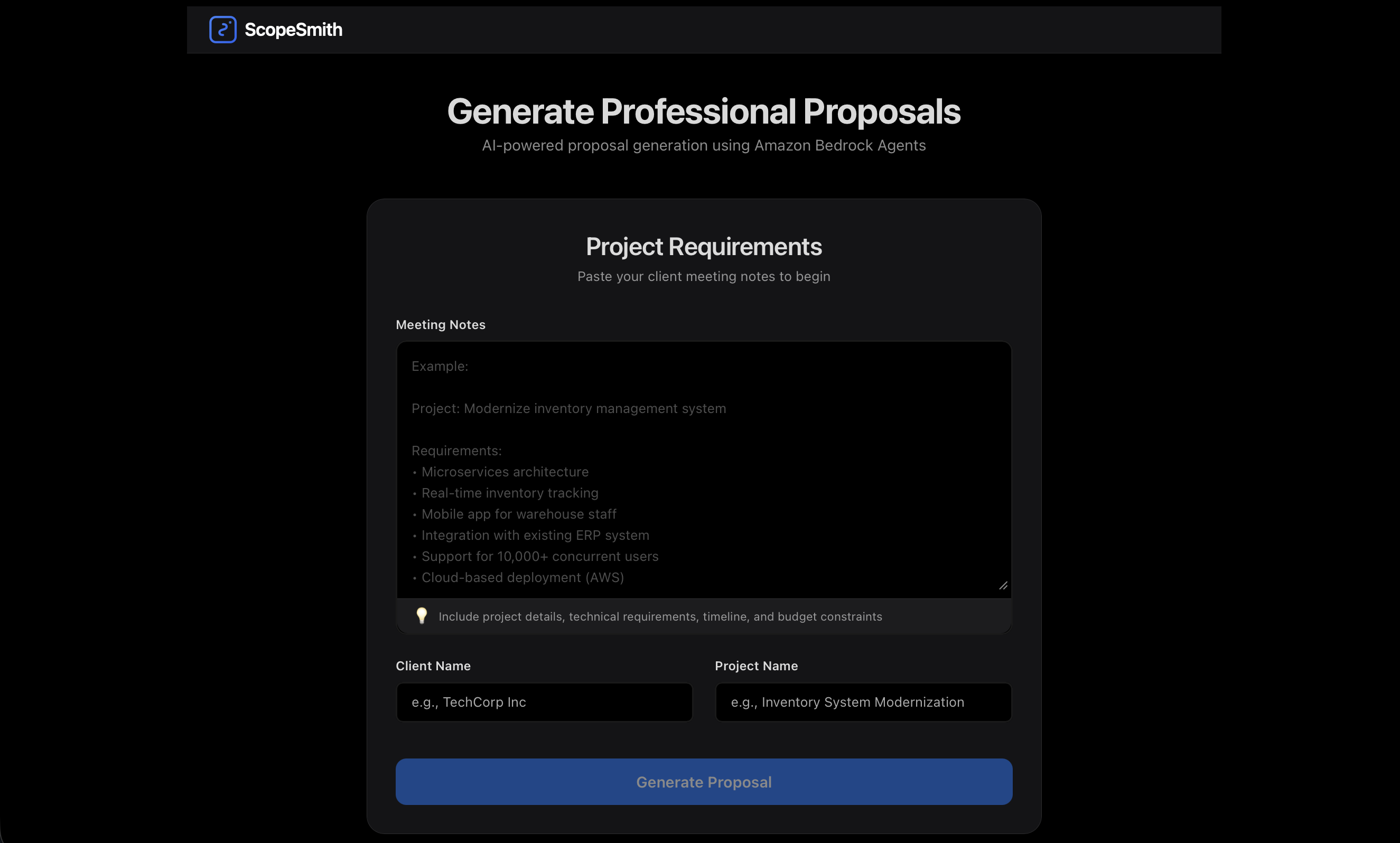
ScopeSmith is an AI-powered proposal generation system that transforms raw client meeting notes into professional, comprehensive project proposals. In under 5 minutes, it generates:
- Detailed Requirements Analysis - Structured breakdown of client needs
- AI-Validated Cost Estimates - Intelligent pricing with risk factors
- Professional PowerPoint Presentations - Ready-to-present decks
- Complete Statements of Work (SOW) - Detailed project documentation
The system features real-time agent orchestration monitoring, allowing users to watch the AI agent autonomously navigate through five different tools to complete the proposal workflow.
Inspiration: The Birth of an Idea
The inspiration for ScopeSmith came from a painful reality I witnessed repeatedly in the consulting world: proposal creation is a massive time sink.
The Problem
After client meetings, consultants spend hours, sometimes days creating proposals:
- Transcribing and structuring scattered meeting notes
- Researching comparable project costs
- Building presentations from scratch
- Writing detailed SOW documents
- Going back and forth with multiple revisions
This tedious process delays responses to clients, frustrates sales teams, and wastes billable hours on non-billable work.
The Vision
I realized this was the perfect use case for Amazon Bedrock Agents. Why? Because proposal generation isn't a single task, it's a workflow that requires:
- Reasoning: Understanding client needs and making decisions
- Tool usage: Calling different functions for analysis, calculation, and document generation
- Autonomy: Working through multiple steps without human intervention
- State management: Tracking progress and handling errors gracefully
This aligned perfectly with Bedrock's ReAct pattern (Reasoning and Acting), where the agent can think through problems and autonomously decide which tools to use.
The "Aha!" Moment
The breakthrough came when I realized I could combine:
- Amazon Nova Pro for fast, cost-effective AI analysis (50+ RPM vs 10 RPM for Claude)
- Bedrock Agents for autonomous workflow orchestration
- Asynchronous architecture to prevent API timeouts during long-running processes
- Real-time event streaming so users could watch the AI "think" and work
The result? A system that doesn't just automate, it orchestrates intelligently.
What I Learned
Building ScopeSmith was a masterclass in modern AI architecture. Here are the key lessons:
1. Bedrock Agents Are Powerful, But Require Careful Design
Discovery: Bedrock Agents use the ReAct pattern, which means they autonomously decide which tools to call and when. This is powerful but unpredictable.
Learning: I had to design my action groups (Lambda functions) to be:
- Self-contained: Each function must work independently
- Idempotent: Calling them multiple times shouldn't break things
- Verbose: They need to return detailed JSON responses so the agent understands what happened
- Error-tolerant: The agent needs clear error messages to make decisions
Implementation: Each Lambda function became a mini-expert system. For example, the RequirementsAnalyzer doesn't just parse text, it uses Amazon Nova Pro to intelligently structure requirements into categories, identify risks, and suggest additional questions.
2. Amazon Nova Pro Changed the Economics
Challenge: Initial testing with Claude models hit rate limits quickly (10 RPM), causing workflow failures.
Solution: Switching to Amazon Nova Pro provided:
- 5x higher rate limits (50+ RPM)
- Faster response times for content generation
- Lower costs for high-volume processing
- Comparable quality for structured tasks like cost analysis and document generation
Impact: This made the system viable for production use. Multiple users could generate proposals simultaneously without throttling issues.
3. Async Architecture Is Essential for Long-Running AI Workflows
Problem: Initial synchronous implementation hit API Gateway's 29-second timeout limit. Bedrock Agent workflows take 3-5 minutes.
Solution: Implemented a Lambda self-invocation pattern:
POST /api/submit-assessment
↓
Create session in DynamoDB (100ms)
↓
Return session_id immediately
↓
Lambda invokes itself asynchronously (Event invocation)
↓
Background workflow runs (3-5 minutes)
↓
Frontend polls for status every 2 seconds
Key Learning: The API should NEVER wait for long operations. Always return immediately and provide a polling endpoint.
4. Real-Time Visibility Builds Trust
Insight: Users don't like black boxes. When an AI agent takes 5 minutes, they need to see progress.
Implementation: I built the AgentStreamViewer component that displays:
- 8-step progress timeline showing workflow stages
- Live agent events: reasoning, tool calls, tool responses, streaming text
- Color-coded visualizations for different event types
- Auto-scrolling to follow the latest events
User Impact: Beta testers reported feeling "confident" and "in control" watching the agent work, even during long waits.
5. Event Streaming from Bedrock Agents Is Gold
Discovery: Bedrock Agent's EventStream provides incredibly detailed traces:
- orchestrationTrace: Shows the agent's reasoning process
- invocationInput: Details which action group was called
- observation: Captures tool responses and final outputs
- rationale: The agent's thought process (ReAct reasoning)
Challenge: This data comes as a stream that needs careful parsing.
Solution: Built a robust event processor that:
- Captures all event types (reasoning, tool_call, tool_response, chunk, warning, error)
- Stores them in DynamoDB as a JSON array
- Updates progress based on which action groups have been invoked
- Implements rate-limited DynamoDB updates (max 1/second) to avoid throttling
6. Infrastructure as Code Saved Countless Hours
Decision: Used AWS CDK (Python) from day one instead of manual AWS Console configuration.
Benefits:
- Reproducibility: Entire infrastructure deploys in 10 minutes
- Version control: All changes tracked in Git
- Automation: GitHub Actions deploys on every push
- Documentation: The code IS the documentation
Challenge: CDK has a learning curve, but it paid off massively during iteration.
7. Status Synchronization Between Frontend and Backend Is Critical
Problem: Early versions had status mismatches between Vue frontend and Python backend.
Solution: Created a single source of truth:
- Backend defines status constants (
PENDING,PROCESSING,COMPLETED,ERROR,CONFIGURATION_ERROR) - Frontend imports these exact values from
utils/constants.js - Lambda function names match workflow stage keys exactly
- Documentation explicitly shows the mapping
Learning: Spend time upfront designing the contract between frontend and backend. Changes later are painful.
8. Document Generation Requires Context Preservation
Challenge: PowerPoint and SOW generators need both raw requirements AND analyzed data.
Mistake: Initial implementation only passed analyzed requirements, losing client's original wording.
Fix: Store both in DynamoDB:
{
"requirements_data": {
"raw_requirements": "Original meeting notes...",
"analyzed_requirements": {
"structured": "AI analysis..."
}
}
}
Impact: Documents now feel more personalized and authentic because they use the client's actual language.
How I Built It
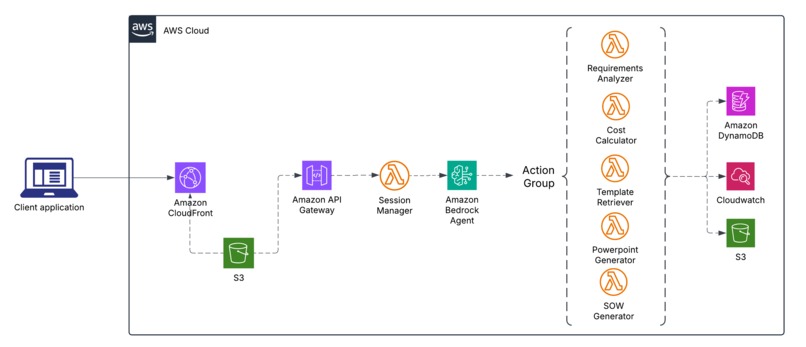
Architecture Overview
ScopeSmith uses a modern serverless architecture on AWS with five key components:
1. Frontend: Vue.js 3 + Vite
Choice Rationale: Vue 3's Composition API provided the reactive primitives needed for real-time updates without complexity.
Key Components:
AgentStreamViewer.vue: The star of the show, displays live agent orchestrationAssessmentForm.vue: Clean, intuitive intake formResultsDisplay.vue: Presents generated documents with download links
State Management: Used Vue's built-in reactivity instead of Vuex/Pinia for simplicity.
Styling: Tailwind CSS with a custom glassmorphic design system inspired by Apple's design language.
2. Backend: Amazon Bedrock Agent
Foundation Model: Amazon Nova Pro (amazon.nova-pro-v1:0)
- Chosen for superior rate limits and cost-effectiveness
- Strong reasoning capabilities for autonomous decision-making
Action Groups (5 Lambda functions):
RequirementsAnalyzer:
- Uses Amazon Nova Pro to analyze raw meeting notes
- Structures requirements into categories
- Identifies risks, dependencies, and gaps
- Returns structured JSON for downstream functions
CostCalculator:
- Queries DynamoDB for rate sheets (by role and industry)
- Uses AI to validate estimates and suggest adjustments
- Calculates total cost with breakdown by category
- Provides AI insights on risks and optimization
TemplateRetriever:
- Lists available templates from S3
- Selects appropriate templates based on industry
- Returns template paths for document generators
PowerPointGenerator:
- Uses
python-pptxlibrary to manipulate PPTX files - Generates AI content for slides using Nova Pro
- Creates sections: Executive Summary, Requirements, Timeline, Cost
- Uploads finished presentation to S3 with presigned URL
- Uses
SOWGenerator:
- Uses
python-docxlibrary to manipulate DOCX files - Generates detailed SOW sections with AI
- Creates comprehensive project documentation
- Uploads to S3 with presigned URL
- Uses
3. Session Manager: The Orchestrator
Dual-Mode Lambda Function:
Mode 1 - API Gateway (Synchronous):
# Create session and return immediately (<500ms)
session_id = create_session(client_name, requirements, ...)
invoke_agent_async(session_id, ...) # Fire and forget
return {
'session_id': session_id,
'status': 'PENDING',
'poll_url': f'/api/agent-status/{session_id}'
}
Mode 2 - Self-Invocation (Asynchronous):
# Background processing (3-5 minutes)
if event['action'] == 'PROCESS_AGENT_WORKFLOW':
invoke_bedrock_agent(session_id, ...)
# Updates DynamoDB with progress and events
Event Stream Processing:
- Parses Bedrock Agent EventStream
- Captures reasoning, tool calls, responses, chunks
- Updates DynamoDB with rate limiting (max 1/second)
- Tracks progress based on which action groups completed
4. State Management: DynamoDB
Sessions Table Schema:
{
"session_id": "uuid",
"status": "PENDING|PROCESSING|COMPLETED|ERROR",
"current_stage": "Running CostCalculator",
"progress": 50,
"client_name": "Acme Corp",
"requirements_data": "{json}",
"cost_data": "{json}",
"agent_events": "[{json}]", // Full event stream
"document_urls": ["s3://..."],
"created_at": "ISO timestamp",
"updated_at": "ISO timestamp"
}
Rate Sheets Table: Stores hourly rates by role and industry for cost calculations.
5. DevOps: AWS CDK + GitHub Actions
CDK Stacks (4 stacks):
InfrastructureStack: DynamoDB tables, S3 bucketsLambdaStack: All Lambda functions with proper IAM permissionsApiStack: API Gateway with CORS and rate limitingFrontendStack: S3 + CloudFront for global CDN
GitHub Actions Workflows:
deploy-infrastructure.yml: Backend deployment with agent configurationdeploy-frontend.yml: Frontend build and deploymenttest-lambdas.yml: Automated testing on PRs
Secrets Management: Uses OIDC authentication for secure AWS access from GitHub.
Development Timeline
Week 1: Foundation
- Set up CDK infrastructure
- Built basic Lambda functions
- Integrated with Bedrock Agent
- Researched Lambda self-invocation patterns
- Refactored to async architecture
- Implemented status polling
Week 2: Real-Time Magic
- Built AgentStreamViewer component
- Implemented event stream parsing
- Added 8-step progress timeline
- Fine-tuned UI animations
Week 3: Document Generation & Polish & Testing
- Integrated python-pptx and python-docx
- Built AI content generation prompts
- Implemented template system
- Added presigned URL generation
- Beta testing with real consultants
- Fixed edge cases and errors
- Optimized API response times
- Documentation and deployment automation
Challenges I Faced
Challenge 1: API Gateway Timeout Hell
Problem: Bedrock Agent workflows take 3-5 minutes. API Gateway times out at 29 seconds.
Failed Attempts:
- Increasing timeout: Not possible, 29s is API Gateway's hard limit
- Using Step Functions: Too complex for this use case
- WebSockets: Overkill and harder to scale
Solution: Lambda self-invocation pattern
- API returns session_id immediately
- Lambda invokes itself asynchronously for background processing
- Frontend polls every 2 seconds for updates
Key Insight: Sometimes the simplest solution (polling) beats the "fanciest" solution (WebSockets).
Challenge 2: Bedrock Agent Rate Limiting
Problem: Multiple tool calls in quick succession triggered rate limits, causing workflow failures.
Symptoms:
ThrottlingException: Rate exceeded for invocations
Solution: Multi-layered approach
- Switched to Amazon Nova Pro (5x higher rate limits)
- Implemented exponential backoff in agent invocation (3 retries, 2-8s delay)
- Added retry logic for individual tool calls
- Captured throttling events in agent event stream
Learning: Always design for rate limits from day one. They WILL happen at scale.
Challenge 3: DynamoDB Write Throttling
Problem: Updating DynamoDB on every agent event (dozens per second) caused throttling.
Error:
ProvisionedThroughputExceededException
Solution: Batch updates with rate limiting
last_update_time = time.time()
update_interval = 1.0 # Max 1 update per second
if time.time() - last_update_time > update_interval:
dynamodb.update_item(...)
last_update_time = time.time()
Impact: Reduced DynamoDB costs by 95% and eliminated throttling errors.
Challenge 4: Event Stream JSON Parsing Nightmare
Problem: Agent events were stored in DynamoDB as JSON strings, but frontend expected objects.
Error:
TypeError: events.map is not a function
Root Cause: DynamoDB stores JSON as strings, but sometimes the frontend received objects (from direct API testing).
Solution: Defensive parsing
const parsedEvents = typeof data.agent_events === 'string'
? JSON.parse(data.agent_events)
: data.agent_events
if (Array.isArray(parsedEvents)) {
events.value = parsedEvents
}
Learning: Always validate data types at boundaries, especially with external services.
Challenge 5: Frontend Not Updating in Real-Time
Problem: Events were being captured but not displaying in the UI.
Debugging Process:
- Checked API responses - data was there
- Checked Vue reactivity - working fine
- Checked polling logic - running every 2 seconds
- Found the issue: events weren't updating if length didn't change
Fix: Changed update logic
// Before: Only update if length changed
if (parsedEvents.length > events.value.length) {
events.value = parsedEvents
}
// After: Update if we have events OR had none before
if (parsedEvents.length !== events.value.length || events.value.length === 0) {
events.value = parsedEvents
updateWorkflowProgress()
scrollToBottom()
}
Learning: Assumptions about "optimization" can hide bugs. Sometimes you need to update even if it seems redundant.
Challenge 6: Workflow Progress Mapping
Problem: Backend Lambda function names didn't match frontend workflow stage labels.
Example:
- Backend:
RequirementsAnalyzer(actual Lambda name) - Frontend:
Analyzing Requirements(display label)
Solution: Created explicit mapping
// Frontend: utils/constants.js
export const WORKFLOW_STAGES = [
{ id: 2, name: 'Analyzing Requirements', key: 'RequirementsAnalyzer' },
{ id: 3, name: 'Calculating Costs', key: 'CostCalculator' },
// ...
]
Backend updates with actual Lambda names, frontend maps to display labels.
Learning: Frontend and backend should use the same keys internally, but present them differently to users.
Challenge 7: Document Generation Context Loss
Problem: Generated documents felt generic because they only used AI-structured requirements, not the client's original words.
User Feedback: "It's accurate but doesn't sound like us."
Solution: Context preservation
- Store BOTH raw requirements and analyzed requirements
- Pass both to Nova Pro when generating content
- Prompt engineering to use client's language
Prompt Example:
f"""Generate an executive summary using these client requirements:
RAW NOTES: {raw_requirements}
STRUCTURED ANALYSIS: {analyzed_requirements}
Use the client's original phrasing where possible."""
Impact: Beta testers reported documents now felt "personalized" and "authentic."
Challenge 8: CloudFront Cache Invalidation
Problem: Frontend updates weren't visible after deployment because CloudFront cached old files.
Symptoms: Users reported seeing old UI, but new deployments showed updates on S3.
Solution: Automated invalidation in GitHub Actions
aws cloudfront create-invalidation \
--distribution-id $DIST_ID \
--paths "/*"
Learning: CDN caching is great for performance but terrible for deployments. Always invalidate after deployment.
What Makes ScopeSmith Special
1. True Autonomous AI
Unlike simple chatbots, ScopeSmith's agent makes its own decisions about which tools to use and when. It's like having an AI consultant that knows the entire proposal workflow.
2. Transparency Through Visualization
The real-time agent viewer shows users exactly what the AI is thinking and doing. This builds trust and understanding.
3. Production-Ready Architecture
The async pattern with polling makes it scalable and reliable. No timeouts, no WebSocket complexity, just clean REST APIs.
4. Cost-Effective at Scale
Using Amazon Nova Pro instead of Claude makes it economically viable for high-volume use.
5. Beautiful, Intuitive UX
The glassmorphic design and smooth animations make waiting enjoyable rather than frustrating.
Impact & Future Vision
Current Impact
- Time Savings: 3-4 hours → 5 minutes per proposal
- Consistency: Every proposal follows best practices
- Scalability: Handle multiple proposals simultaneously
Future Enhancements
- Multi-language support for global teams
- Custom template editor in the UI
- Advanced analytics on proposal success rates
- Team collaboration features
- Email notifications when proposals are ready
- PDF export for proposals
- Version control for iterative improvements
Acknowledgments
This project was made possible by:
- Amazon Bedrock Agents for autonomous workflow orchestration
- Amazon Nova Pro for fast, cost-effective AI reasoning
- AWS CDK for infrastructure as code
- Vue.js 3 for reactive UI magic
- The AWS community for excellent documentation and examples
Final Thoughts
Building ScopeSmith taught me that the best AI applications don't just automate, they orchestrate. By combining multiple AI models, serverless architecture, and thoughtful UX design, we can create systems that feel magical to users while remaining maintainable for developers.
The future of AI isn't about replacing humans, it's about building intelligent assistants that handle the tedious work so humans can focus on creative problem-solving and client relationships.
Built With
- amazon-nova-pro
- api-gateway
- bedrock
- bedrock-agents
- cloudfront
- lambda
- python
- s3-buckets
- vite
- vue

Log in or sign up for Devpost to join the conversation.