-
-
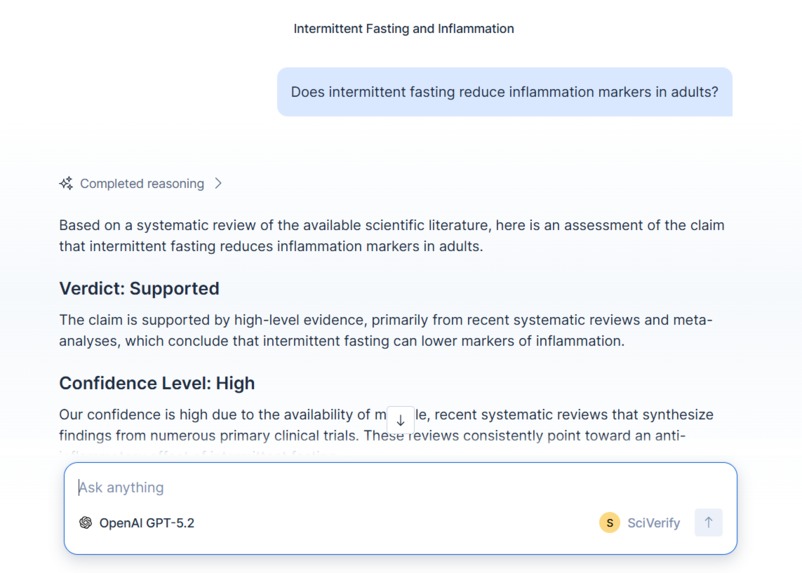
Does intermittent fasting reduce inflammation markers in adults?
-

What is the quality of evidence for intermittent fasting improving cardiovascular health?
-
Excaldraw architectural diagram

Inspiration
It started with a headline: "Intermittent fasting reverses ageing at the cellular level."
Is that true? Partially true? Based on one mouse study or fifty human trials? Finding out takes hours — searching PubMed, reading abstracts, weighing study quality, checking for retractions, noticing which studies are funded by whom. Most people don't have those hours. They either trust the headline or dismiss it. Neither is good.
During the pandemic, I watched misinformation about treatments spread faster than any peer-review process could correct it. The core problem wasn't that evidence didn't exist — it was that the process of finding, evaluating, and synthesising evidence was too slow and too expert-dependent for the speed at which claims travel.
I wanted to build something that could turn that hours-long verification process into a conversation — with every reasoning step visible and auditable. Not a fact-checker that outputs a binary true/false, but a reasoning microscope that shows you why the evidence points the way it does.
When I discovered the Elastic Agent Builder, I realised the infrastructure I needed already existed: semantic search for meaning-level retrieval, ES|QL for deterministic analytical queries, and an agent orchestration layer that could tie it all together with traceable tool invocations.
What I Built / What it does
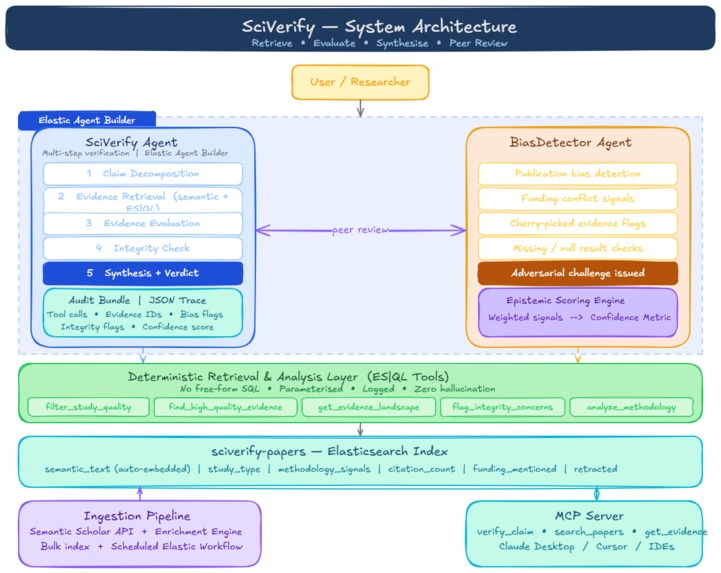
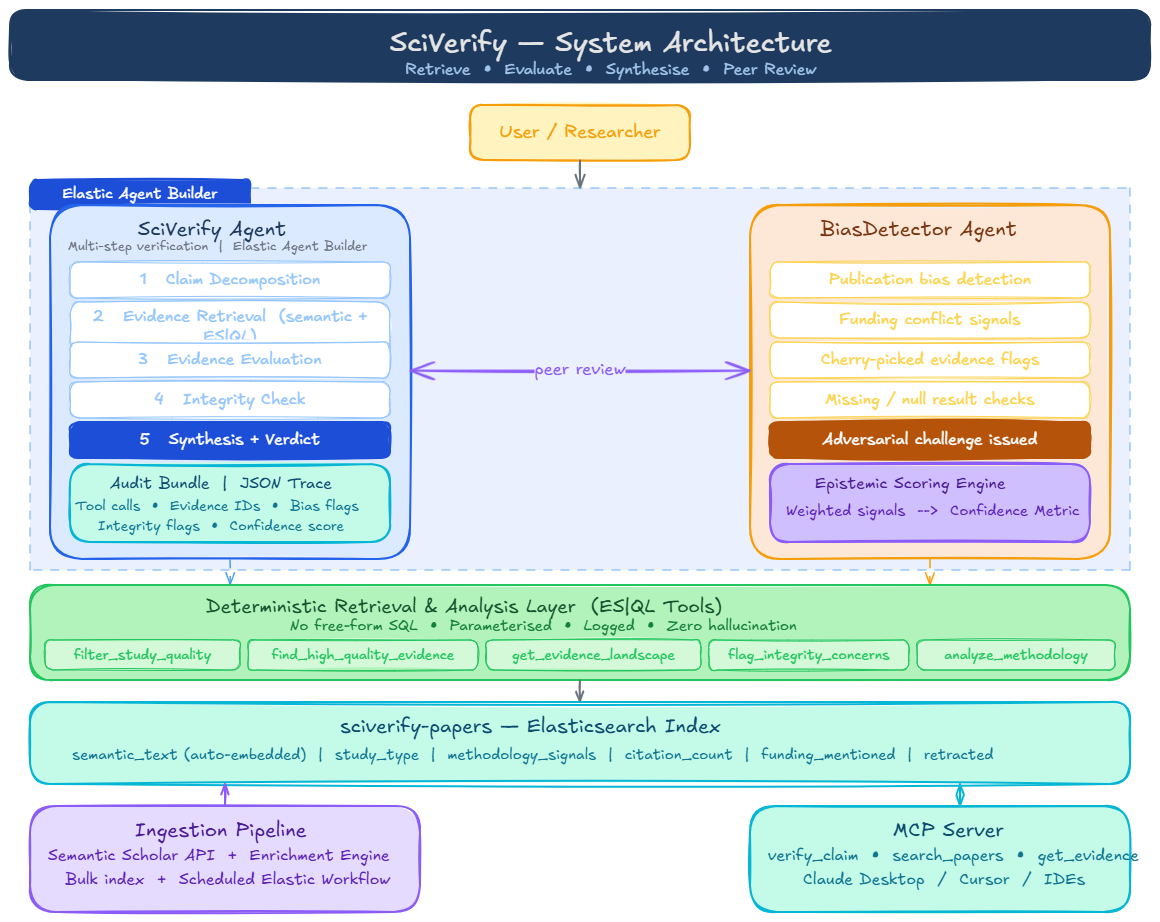
SciVerify is an agent-driven pipeline that verifies scientific claims against the peer-reviewed literature. You submit a claim in natural language, and the agent follows a structured five-step workflow:
Claim Decomposition — parse the claim into searchable facets (subject, intervention, outcome, population) Evidence Retrieval — hybrid semantic + structured search across an Elasticsearch index of scientific papers Evidence Evaluation — assess each paper for relevance, methodology strength, and direction of support Integrity Check — flag retractions, small sample sizes, low-citation outliers, and funding patterns Synthesis — deliver a structured verdict with confidence level, evidence map, epistemic gaps, and full reasoning trace The agent doesn't just retrieve papers — it reasons about them. It distinguishes a meta-analysis of 50 RCTs from a single observational study with 12 participants, and weights its confidence accordingly.
The Evidence Quality Model At the heart of SciVerify is the idea that not all evidence is created equal. The system uses a hierarchy inspired by the evidence-based medicine pyramid:
$$\text{Evidence Weight} \propto \text{Study Type Rank} \times \log(\text{Sample Size}) \times \text{Citation Impact}$$
Where study types are ranked:
$$\text{Meta-analysis} > \text{Systematic Review} > \text{RCT} > \text{Cohort} > \text{Case-Control} > \text{Case Report}$$
This isn't a literal formula the agent computes — it's the principle embedded in the agent's instructions and the tool design. The find_high_quality_evidence tool surfaces meta-analyses and RCTs first. The flag_integrity_concerns tool uses thresholds like:
$$\text{Low-impact flag} = \begin{cases} \text{true} & \text{if } \text{citations} < \theta \text{ and } \text{year} < y_{\text{stale}} \ \text{false} & \text{otherwise} \end{cases}$$
This lets the agent make nuanced assessments rather than treating all papers as equal.
Multi-Agent Architecture SciVerify doesn't rely on a single agent's judgment. I built a second agent — the BiasDetector — that acts as an adversarial peer reviewer. It shares the same toolset but operates with a fundamentally different mandate: find the weaknesses. It looks for publication bias, cherry-picked evidence, funding conflicts, and overconfident conclusions. This mirrors how real science works — claims get stronger when they survive scrutiny.
Data Pipeline The ingestion pipeline pulls paper metadata from the Semantic Scholar API and runs it through an enrichment engine before indexing into Elasticsearch:
Methodology signal extraction — regex patterns detect keywords like randomized, double-blind, placebo-controlled, longitudinal Study-type inference — combines Semantic Scholar's publication type taxonomy with abstract-derived signals Sample-size bucketing — extracts patterns like N = 150 or 500 participants and buckets them (small / medium / large / very-large) Funding detection — flags mentions of funding bodies (NIH, WHO, ERC, industry sponsors) Every enrichment field has a provenance record so you can trace exactly how each signal was derived.
How I Built It
I built SciVerify in Python, using Elasticsearch as both the search engine and the analytical backbone, and Elastic Agent Builder for agent orchestration.
The key architectural decisions:
Semantic search + structured analytics in one index. Elasticsearch's semantic_text field type handles embedding generation and vector search automatically. The same index also stores structured fields (study type, citation count, sample size bucket) queryable via ES|QL. This means the agent can do things pure vector search can't — like "show me only double-blind RCTs with >100 participants from the last 5 years."
Pre-defined, parameterised tools over unconstrained generation. The five custom ES|QL tools are deterministic. The agent decides when to invoke them, but the queries themselves are auditable and can't hallucinate data. This is critical for a system making claims about scientific evidence.
Versioned agent instructions. The agent's prompt is maintained as composable Python constants — identity, workflow, principles, response format — so changes produce meaningful diffs and can be tested programmatically.
Resilience patterns. The ingestion pipeline uses Tenacity for retry logic with exponential backoff and PyBreaker for circuit-breaking against external APIs. Structured logging via structlog and distributed tracing via OpenTelemetry provide observability.
Containerised and reproducible. A multi-stage Dockerfile, a Makefile for common tasks, and make doctor for environment validation mean anyone can get the system running from scratch.
Challenges we ran into
The "All Evidence Looks Equal" Problem The hardest challenge wasn't technical — it was epistemological. Early versions of the agent would retrieve 20 papers and present them as a flat list. A case report with 3 patients appeared alongside a meta-analysis of 50 trials, with no distinction. The agent needed to understand that evidence has weight, and that weight comes from methodology, sample size, and reproducibility.
Accomplishments that we're proud of
Solving this required designing the enrichment pipeline, the ES|QL tools, and the agent instructions as a coherent system. The tools surface quality-stratified evidence; the instructions tell the agent how to interpret it; the integrity checks provide the sceptical counterbalance.
Regex vs. Reality in Methodology Extraction Extracting methodology signals from abstracts using regex is inherently fragile. The pattern \brandomiz(ed|ation)\b catches most RCTs, but misses studies that describe their methodology differently. A paper might say "participants were allocated to groups using a computer-generated sequence" — that's randomisation, but no regex will catch it.
I accepted this as a known limitation and documented it explicitly. The enrichment pipeline is a heuristic layer, not ground truth. In a production system, I'd replace it with a fine-tuned NLP model for methodology classification.
Rate Limits and API Fragility The Semantic Scholar API has strict rate limits, and the free tier throttles aggressively during peak hours. Early ingestion runs would fail partway through, leaving the index in an inconsistent state.
I solved this with a combination of Tenacity's retry logic (exponential backoff with jitter), PyBreaker's circuit-breaking (stop hammering a failing API), and idempotent bulk indexing (re-running ingestion doesn't create duplicates).
Balancing Transparency with Usability SciVerify's design principle is radical transparency — every tool call, every filter, every reasoning step is visible. But too much transparency can overwhelm users. A wall of tool invocations and intermediate results is technically transparent but practically opaque.
The solution was the structured response format: verdict, confidence level, evidence summary, methodology assessment, epistemic gaps, integrity flags, and reasoning trace. The trace is there for anyone who wants to audit the full reasoning chain, but the verdict and summary provide the quick answer.
What I Learned Agent design is prompt engineering + tool design + data modelling. The agent's behaviour emerges from the interaction of all three. Change the tools and the agent reasons differently, even with the same prompt.
ES|QL is underappreciated for agent tooling. Pre-defined, parameterised queries give agents access to structured data operations without the risks of unconstrained SQL generation. This pattern — LLM decides when to query, but the query itself is deterministic — deserves wider adoption.
Epistemic humility is a design requirement, not a nice-to-have. A system that evaluates scientific claims must model uncertainty explicitly. SciVerify never says a claim is "proven" — it says the evidence supports it at a certain confidence level, and tells you exactly why.
Multi-agent adversarial review catches what single-agent systems miss. The BiasDetector consistently identifies weaknesses that the primary agent glosses over — confirmation bias in evidence selection, overweighting of large but poorly-designed studies, and failure to note funding conflicts.
The hardest part of building with LLMs is knowing where not to use them. The enrichment pipeline is deliberately LLM-free. Regex heuristics are less capable but fully deterministic and auditable. For signals that feed into trust calibration, determinism matters more than capability.
What's Next for SciVerify
The current version of SciVerify is a proof of concept — a powerful one, but still a starting point. To make it a truly robust tool for navigating scientific literature, I plan to focus on three key areas:
Direct Integration with Retraction Watch: Currently, SciVerify relies on Semantic Scholar metadata for retraction flags, which can be delayed or incomplete. Integrating the official Retraction Watch database would provide a definitive, real-time source of truth for retracted papers, ensuring critical failures in scientific integrity are flagged immediately.
Moving Beyond Regex for Methodology Extraction: While the current regex-based system is deterministic and transparent, it misses nuance. I aim to replace this heuristic layer with a fine-tuned NLP model specifically trained to classify study designs (e.g., distinguishing a true RCT from a study that merely "randomly selected" participants). This would significantly improve the accuracy of the evidence hierarchy.
Expanding the Source Corpus: Scientific knowledge isn't limited to what's indexed by Semantic Scholar. Integrating additional data sources like PubMed, arXiv, and OpenAlex would provide a more comprehensive view of the literature, particularly in specialised or emerging fields.
Ultimately, the goal is to evolve SciVerify from a research tool into a standard layer of the scientific consumption stack — an always-on "reasoning microscope" that helps researchers, journalists, and the public distinguishing high-quality evidence from noise.
I will share the outcome of the competition, along with insights from my project built with Elastic Agent Builder, with my 16,000 LinkedIn followers after receiving the official results.
Built With
- docker
- elastic-agent-builder
- elastic-cloud
- elasticsearch
- es|ql
- hatchling
- make
- mypy
- opentelemetry
- prometheus
- pybreaker
- pydantic
- pytest
- python
- ruff
- semantic-scholar-api
- structlog
- tenacity
- typer
- uv

Log in or sign up for Devpost to join the conversation.