Inspiration
Modern science produces an enormous volume of papers, experiments, datasets, and meetings every year, yet meaningful scientific discovery is slowing down. During literature reviews and research discussions, we repeatedly encountered the same issues: failed experiments being unknowingly repeated, assumptions remaining implicit and unchallenged, and valuable insights from papers or meetings getting lost over time.
This led to a core realization: scientific knowledge exists, but scientific reasoning is fragmented and manual.
There is no unified system that can reason across the entire scientific process from reading papers to analyzing failures and generating new hypotheses. This project was inspired by a simple question:
What if we treated science as a living system that can be reasoned over continuously?
What We Built
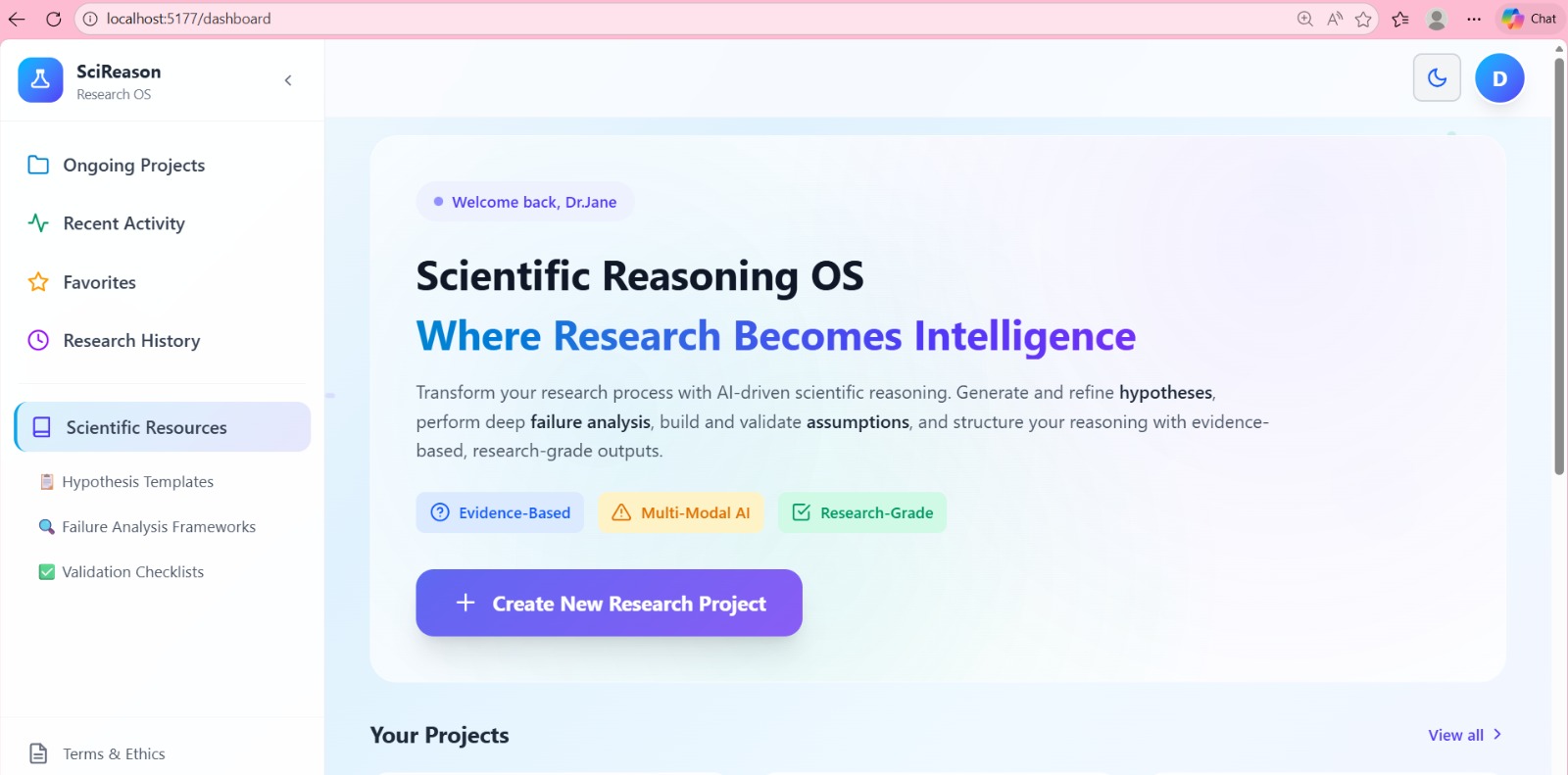
Scientific Reasoning OS is a Research Intelligence Platform designed to read, structure, and reason over scientific knowledge rather than merely summarize it.
The system:
- Ingests research papers, experiment logs, and meeting transcripts
- Extracts structured information such as entities, methods, results, and assumptions
- Builds a knowledge graph representing relationships between papers, experiments, hypotheses, and assumptions
- Uses a long-context AI reasoning engine to perform:
- Cross-disciplinary reasoning
- Failure analysis
- Assumption auditing
- Hypothesis generation
- Cross-disciplinary reasoning
Instead of reacting to user queries, the system actively reasons, flags risks, and proposes new scientific directions.
How We Built It
The project was designed using a modular, systems-engineering approach.
A FastAPI backend orchestrates ingestion, workflows, and API access. Scientific knowledge is stored in a knowledge graph, while vector embeddings provide long-term semantic memory for papers and experiments.
An AI reasoning layer performs hypothesis generation, causal inference, and failure analysis. Workflow orchestration manages multi-step pipelines such as paper ingestion, parsing, embedding, reasoning, and graph updates, as well as experiment failure analysis and alerting.
Conceptually, the system models scientific reasoning as an evolving function:
$$ \text{Insight} = f(\text{Papers}, \text{Experiments}, \text{Assumptions}, \text{Failures}, t) $$
where insights are continuously updated as new evidence is introduced over time ( t ).
Challenges We Faced
One major challenge was enabling long-context reasoning without overwhelming the AI model with raw, unstructured data. Designing a flexible knowledge graph capable of representing science across multiple disciplines was another non-trivial problem.
Managing asynchronous, multi-stage workflows while preserving traceability required careful orchestration. Additionally, teaching the system to treat failed experiments as valuable signals rather than noise was both a technical and conceptual challenge.
Balancing depth with a hackathon-friendly scope was a constant trade-off throughout development.
What We Learned
Through this project, we learned that:
- Scientific progress is often bottlenecked by knowledge management rather than lack of intelligence
- Failed experiments contain structured information that is rarely captured or reused
- Knowledge graphs and reasoning models complement each other far better than standalone language models
- Workflow orchestration is as important as the reasoning engine itself
Most importantly, we learned that AI becomes truly powerful when it reasons over structured knowledge rather than raw text.
Future Vision
Scientific Reasoning OS is an early step toward a future where assumptions are continuously audited, experiments are designed with failure-awareness, and cross-disciplinary insights emerge naturally.
The long-term goal is not to replace researchers, but to build a system that reasons alongside them preserving knowledge, challenging assumptions, and accelerating scientific discovery.

Log in or sign up for Devpost to join the conversation.