
Inspiration
Scientific articles are tough to read. As students and researchers ourselves we really want to have a smart search system that can help us to deal with the relations and topics of the papers. We created a multi-functional specific-domain search system. We are targeting the academia community.
What it does
Researchers and students may create queries that include finding all papers that address a problem in a specific way, or discovering the roots of a certain idea. We want to provide a solution to help them with the identification and classification of concepts, and the relations connecting them.
How we built it
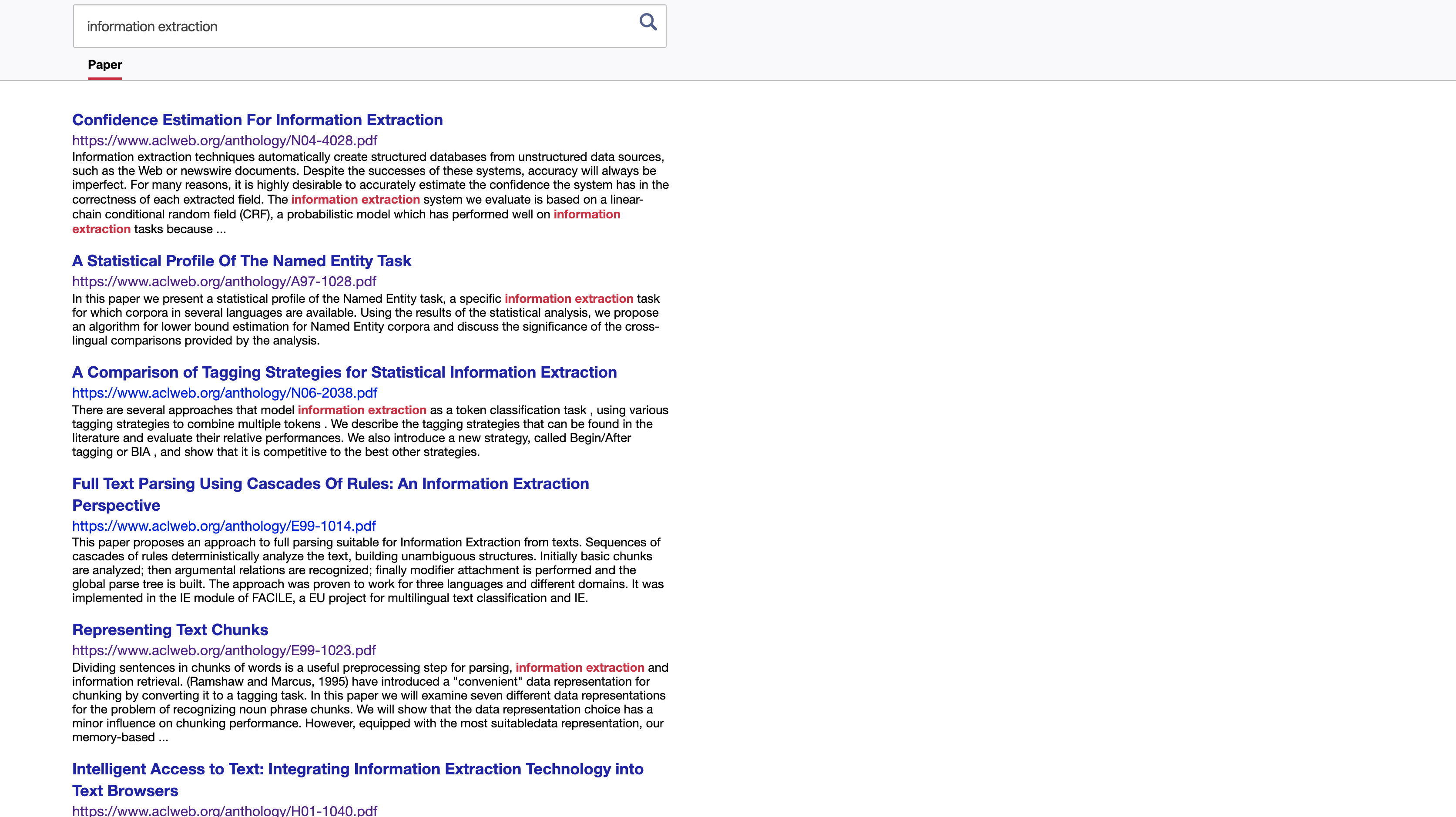
Our system employed OCR to extract the text from pdf, elastics to index, Bert to preprocess, LSTM to extract entities, LDA to disambiguate entities and CNN to classify the relations. Finally we demonstrate those features on html in web search.
Challenges we ran into
Designing the pipeline and front end design are two major challenges for us.
Accomplishments that we're proud of
Our pipeline works and we created a runnable system.
What we learned
We learned the process of front end developing from prototype to choose frameworks and finally flesh out the vision.
What's next for scientific paper search & analyzer
We aim to further improve our accuracy of entity extraction and relation classification.
Built With
- elasticsearch
- gensim
- python
- pytorch
- tensorflow
- tesseract

Log in or sign up for Devpost to join the conversation.