-
-

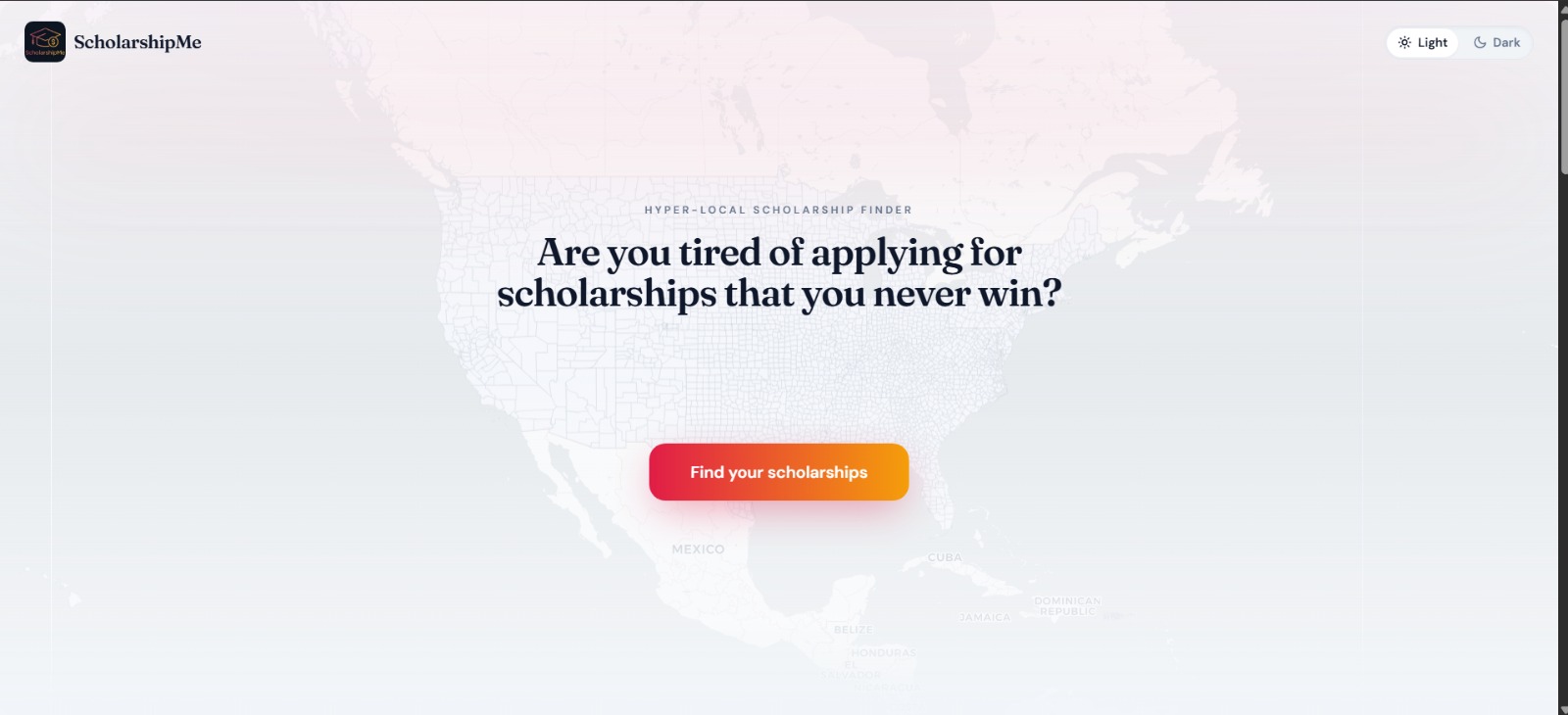
Landing page
-
Landing page -light mode
-

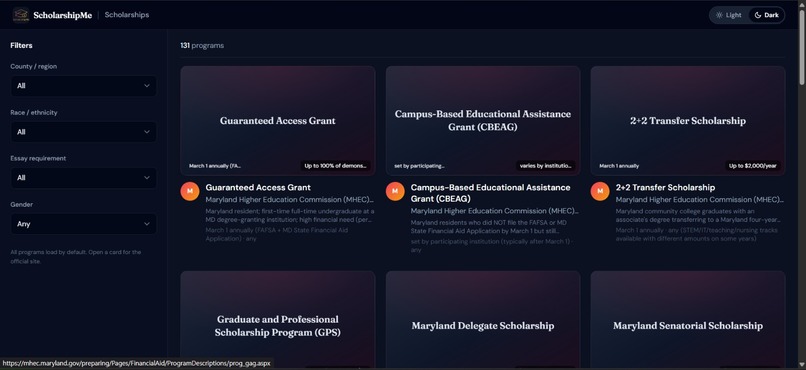
Some unique scholarship examples
-

-
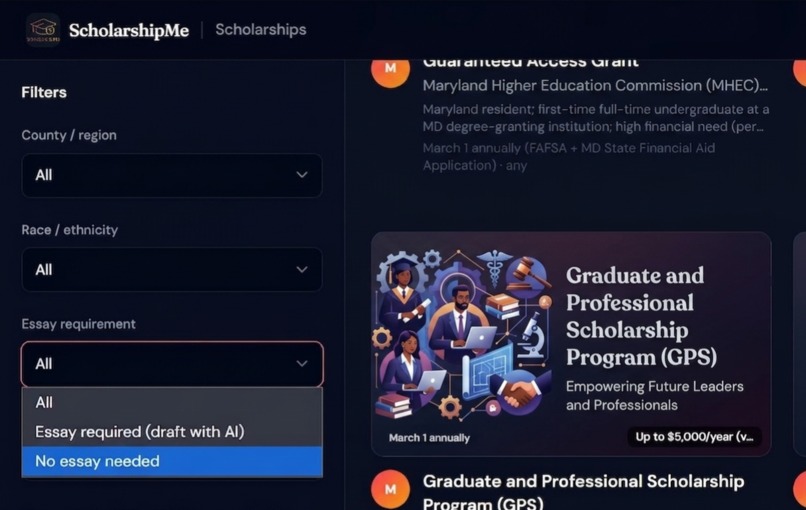
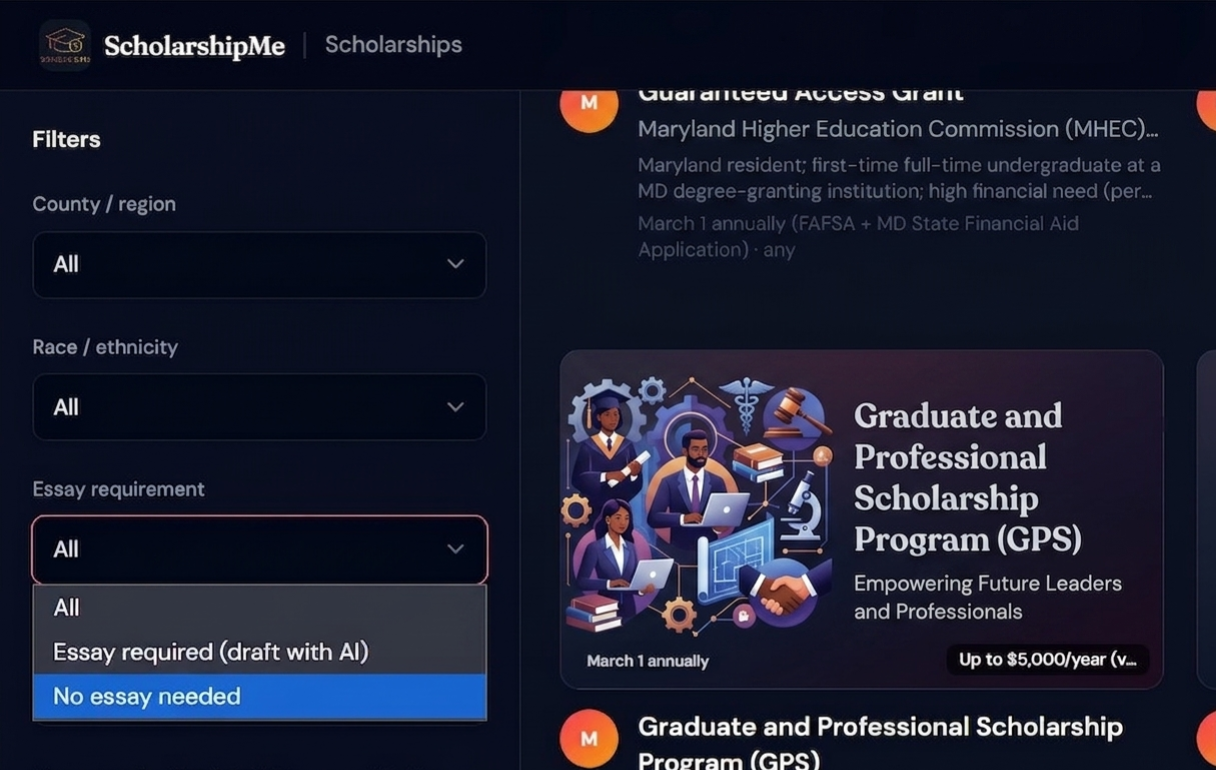
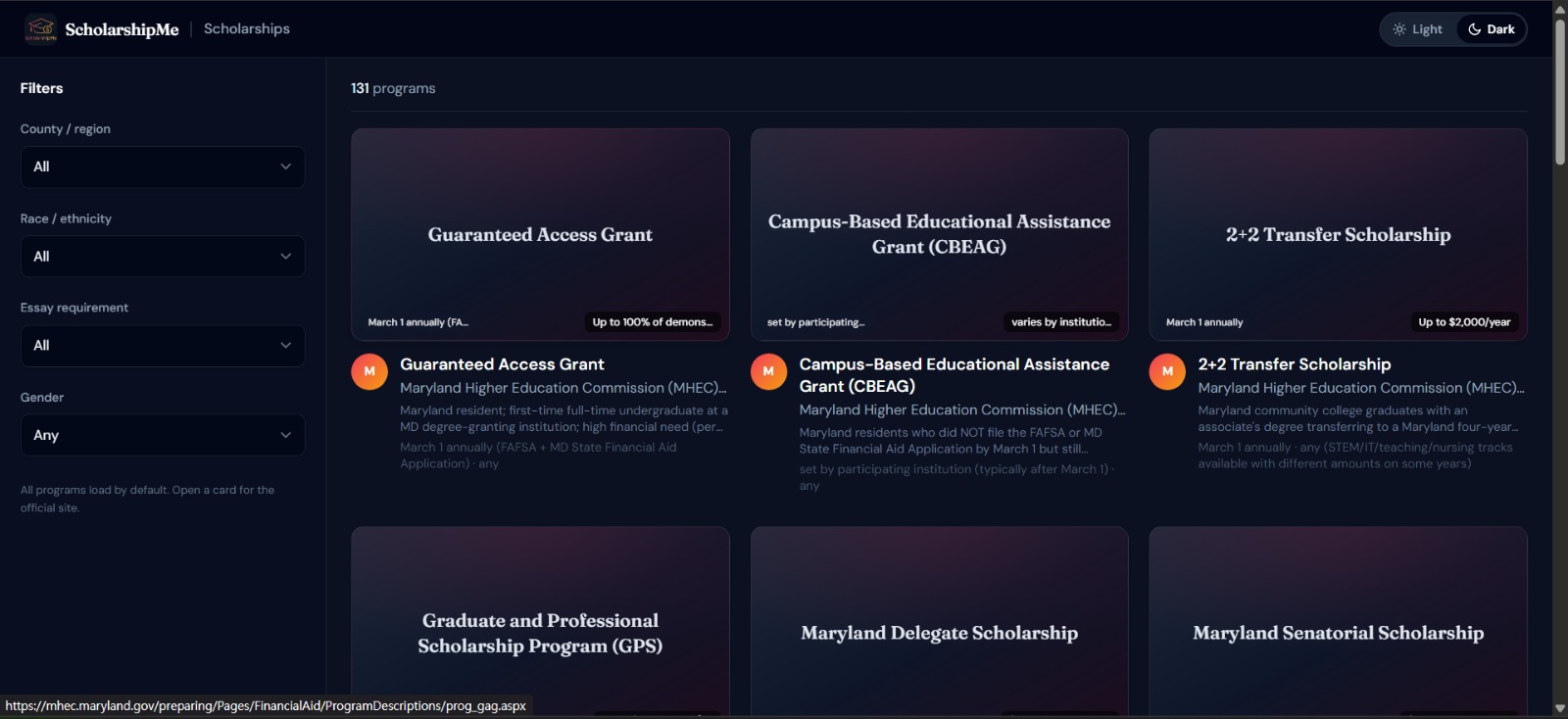
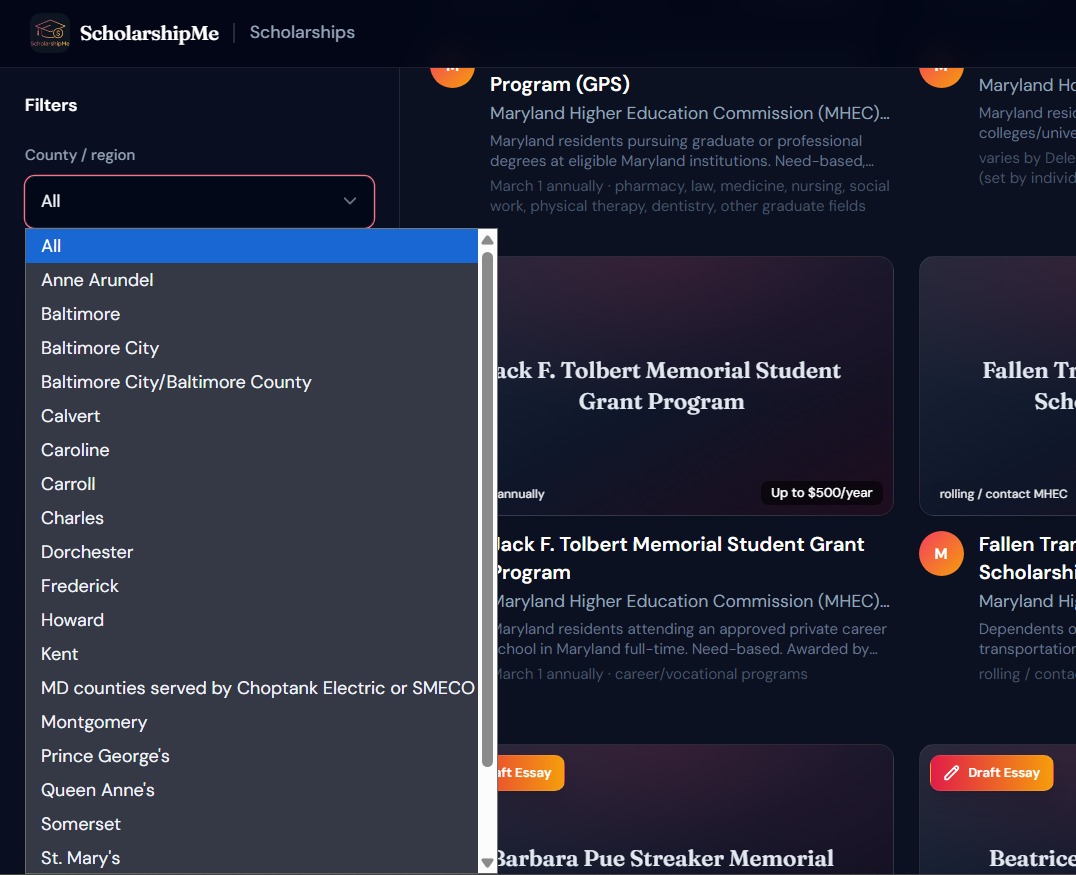
Filter view for scholarship
-
-
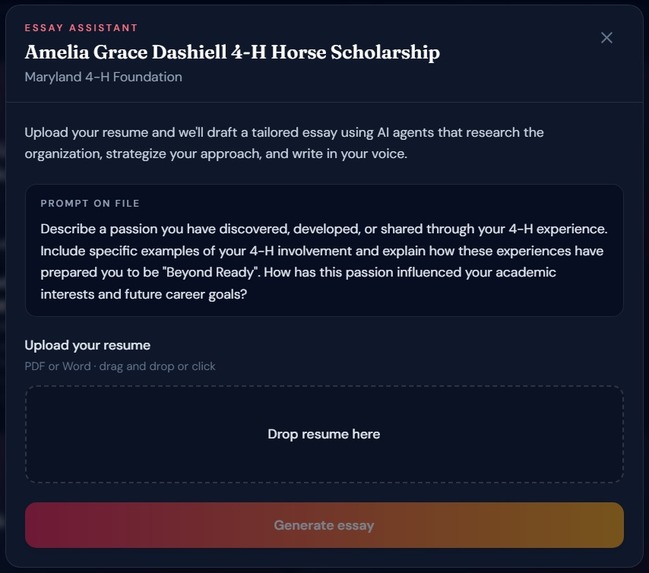
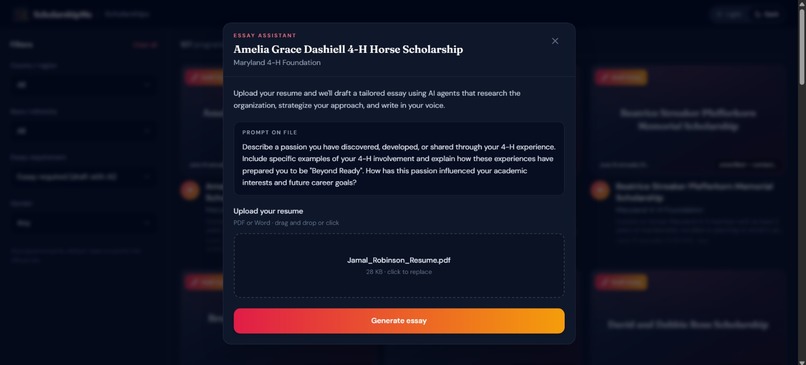
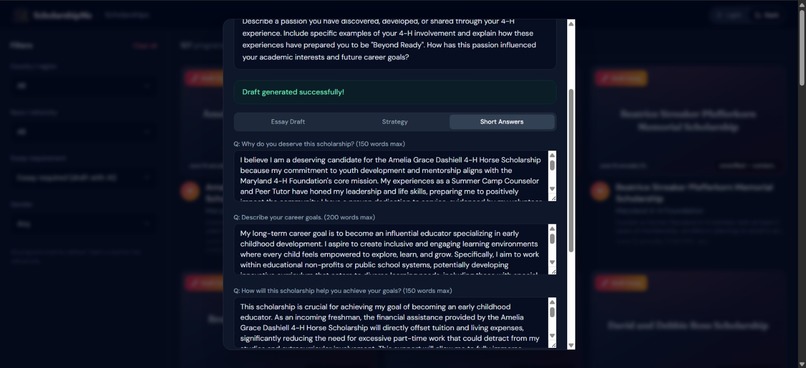
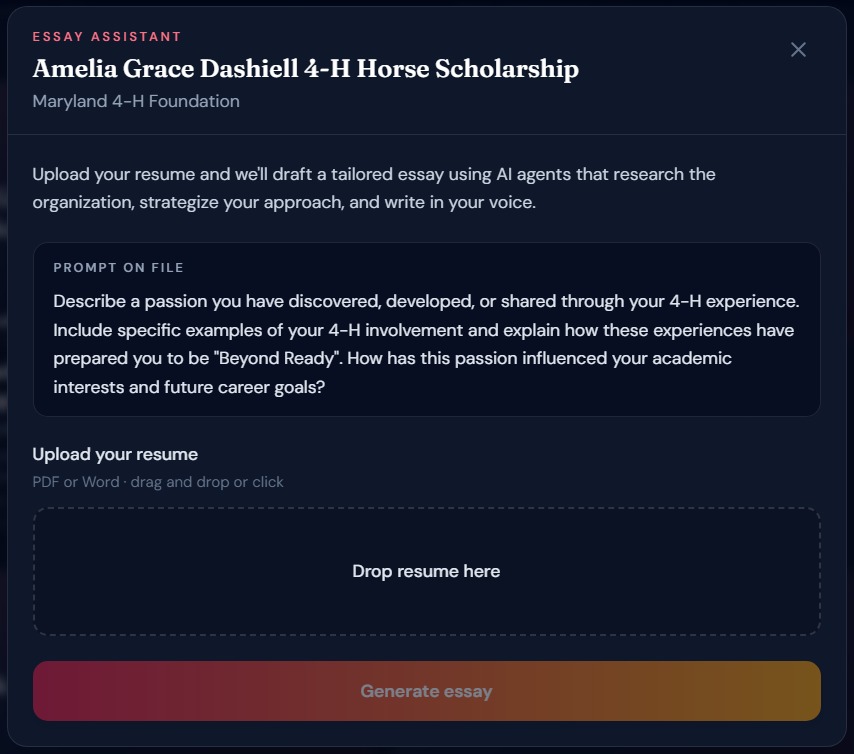
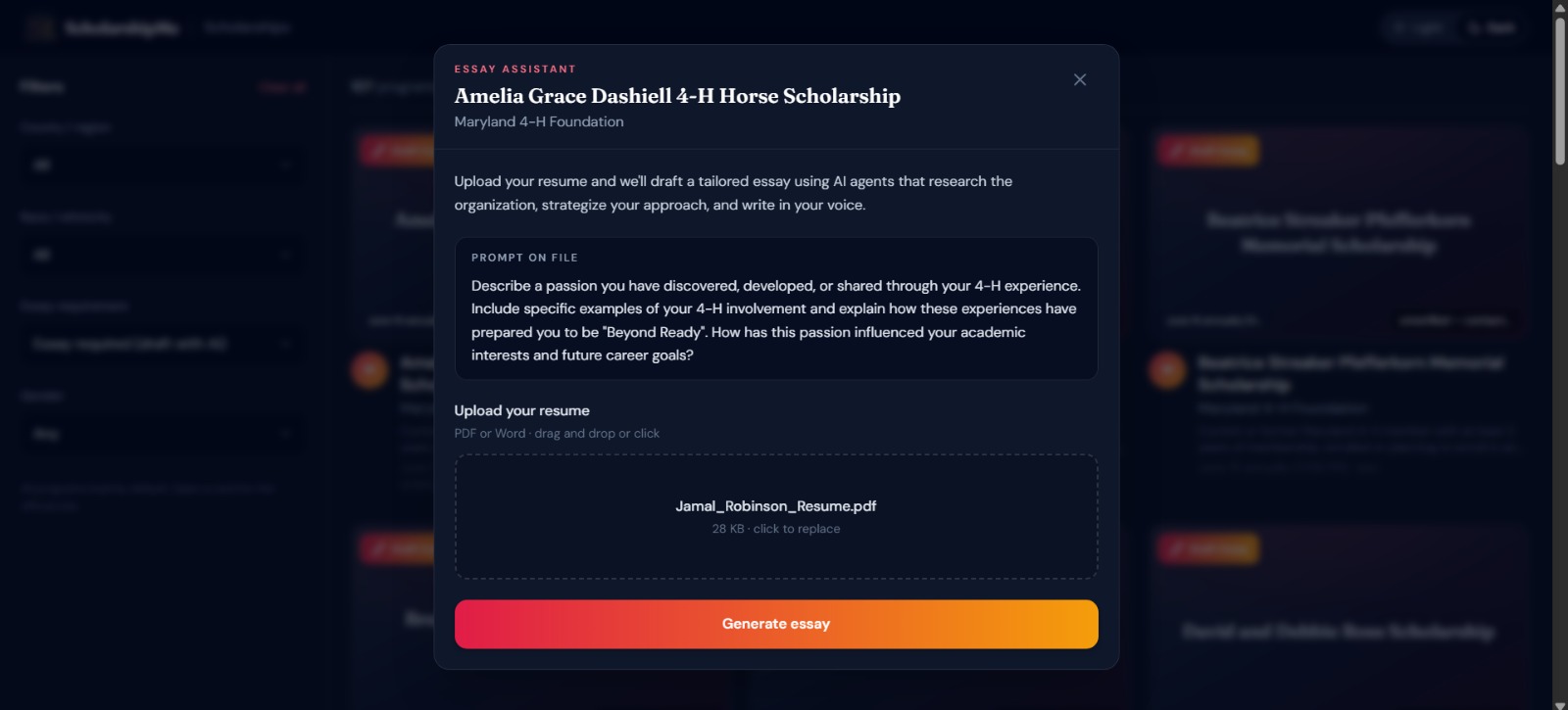
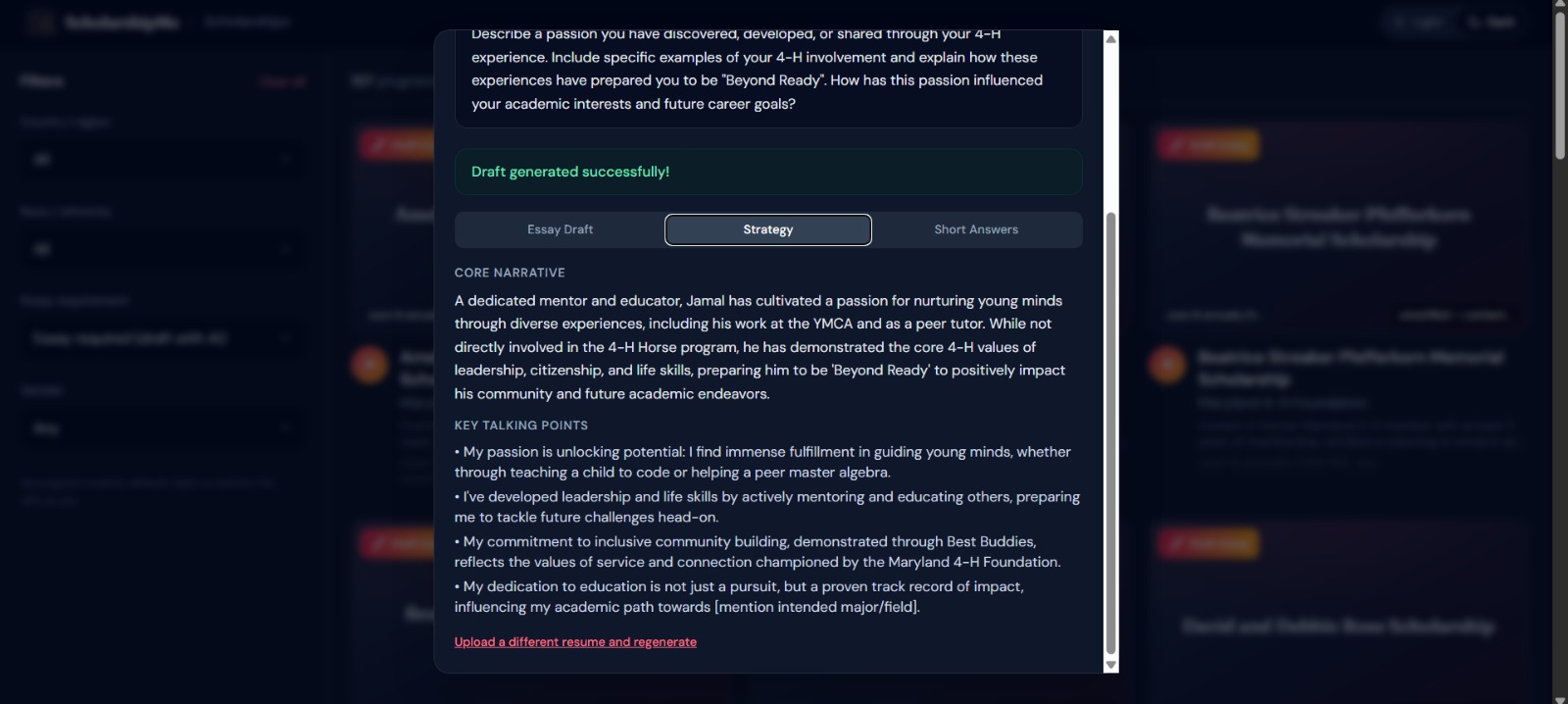
Essay generation
-
-
-
-
-
-
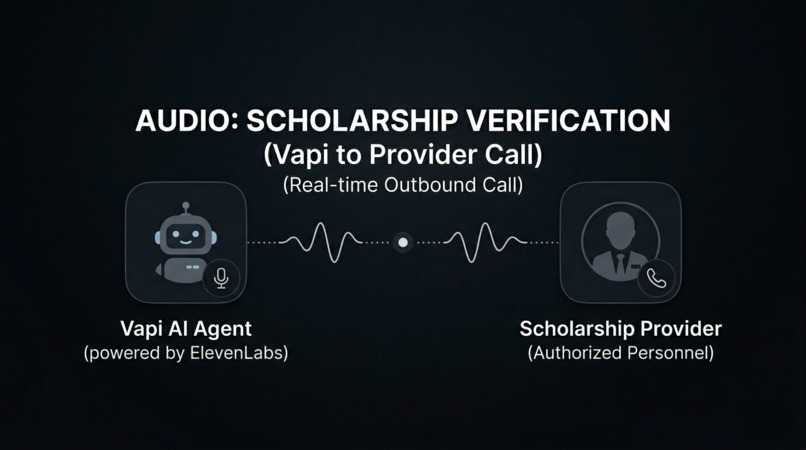
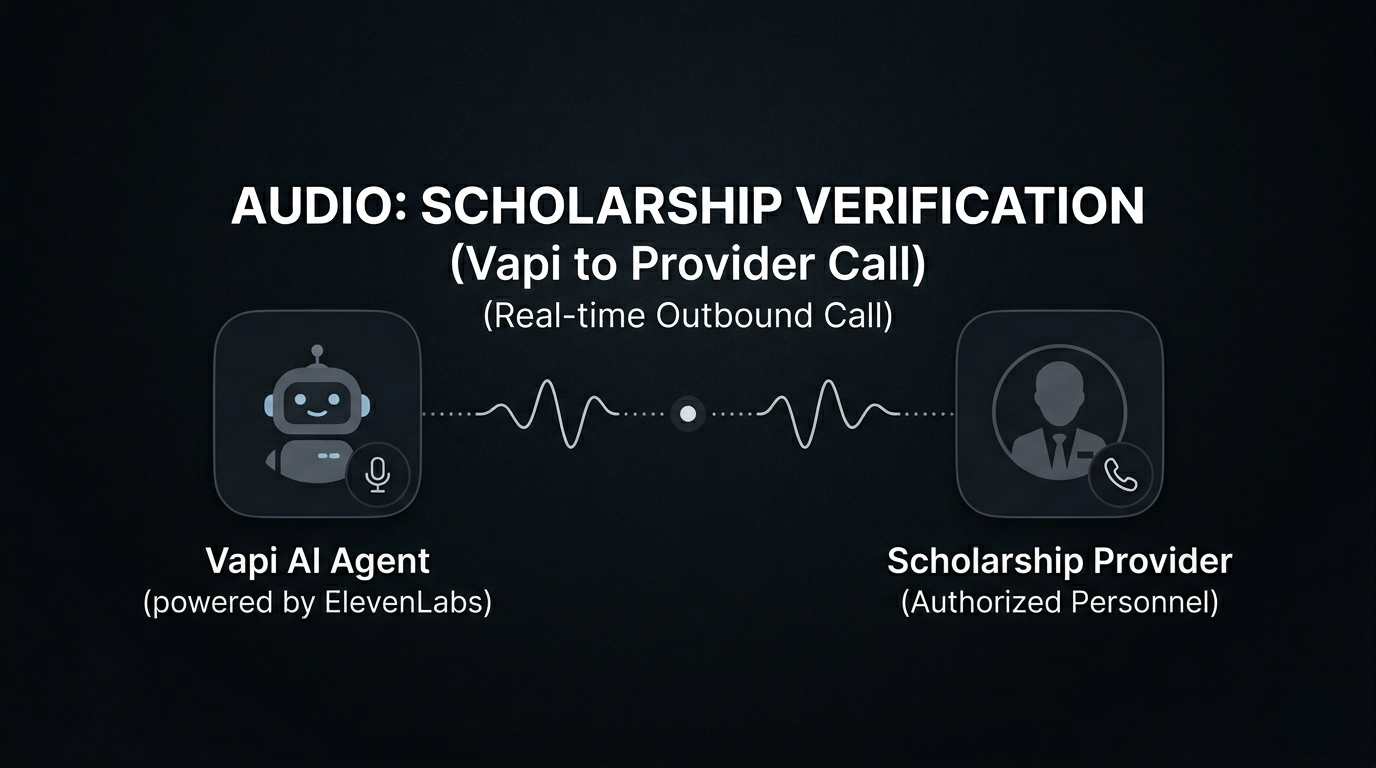
Vapi to verify scholarships
-
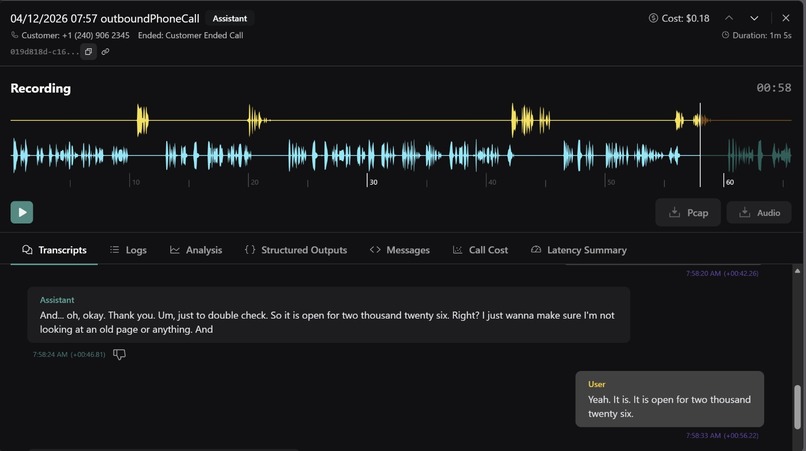
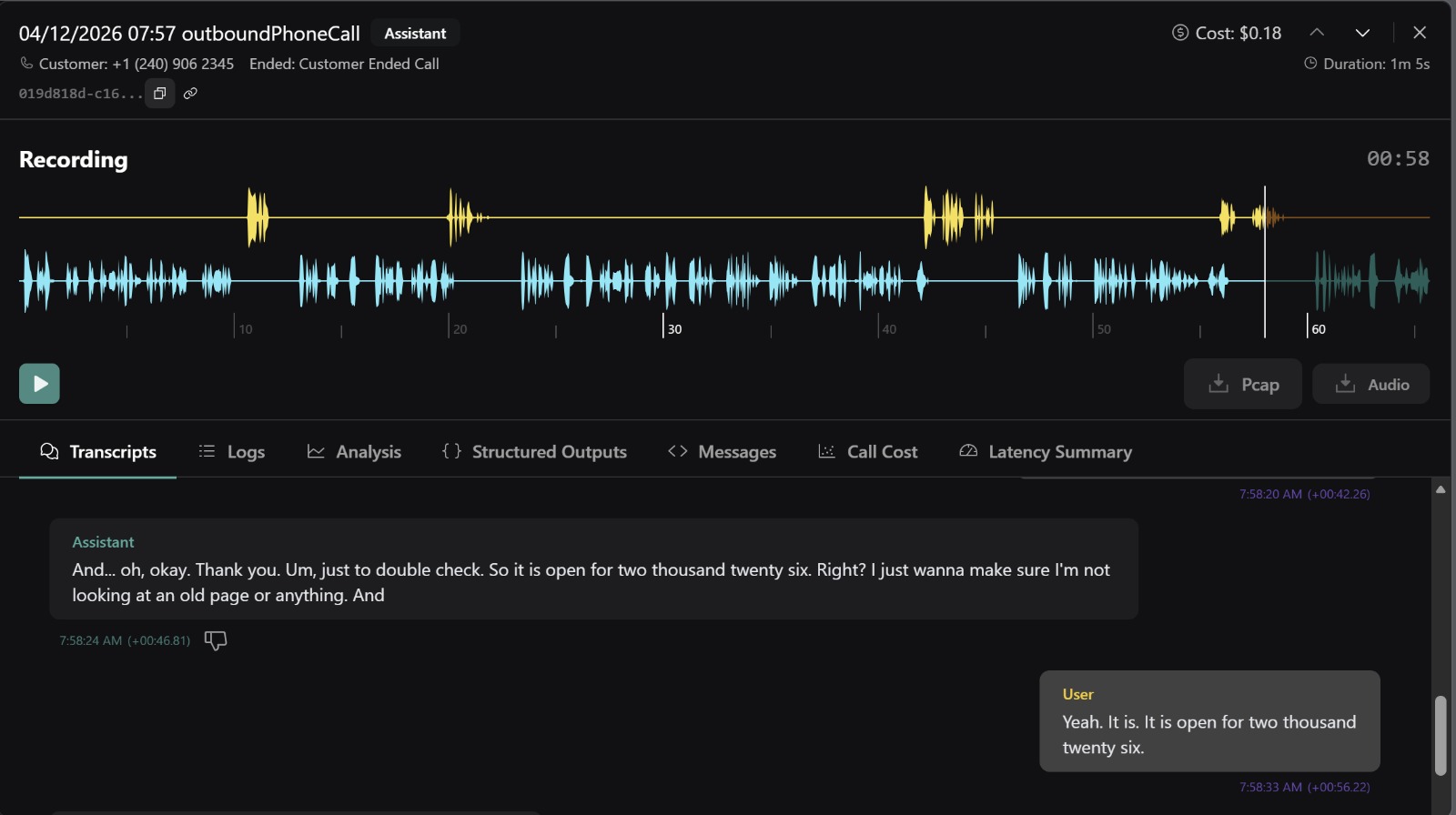
Vapi dashboard
-
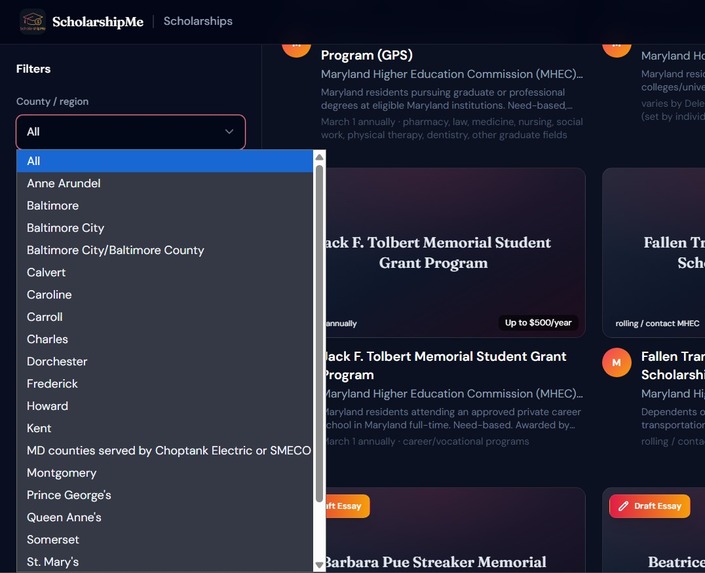
More specific filters
-
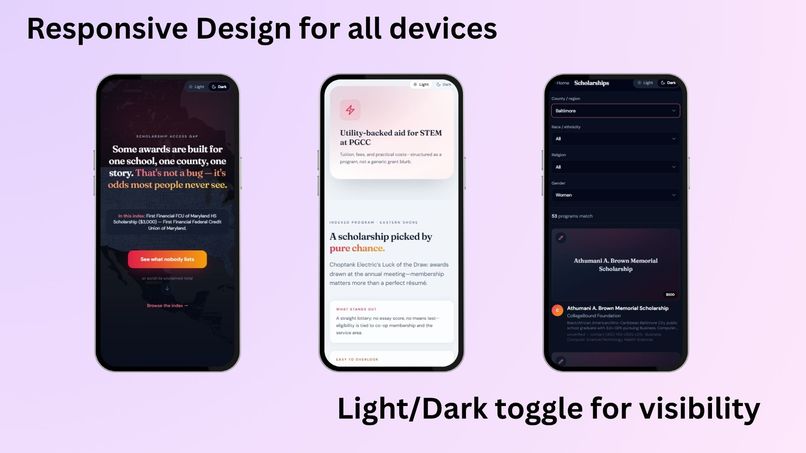
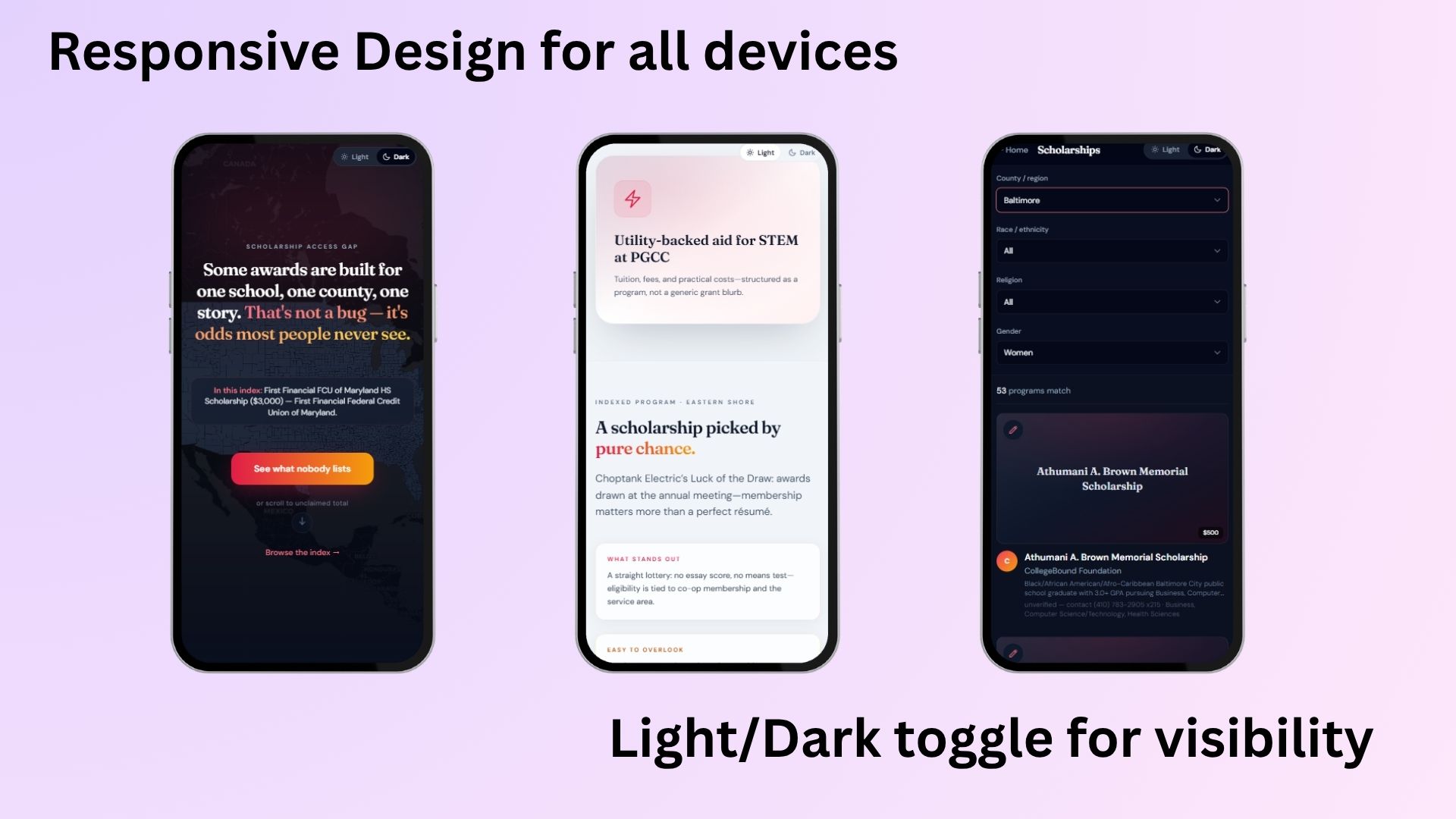
Responsive Mobile view



Inspiration
When we got accepted to our dream schools, we were over the moon, until reality hit. The financial burden of college tuition was overwhelming. We turned to scholarships, expecting a straightforward process. What we found was anything but.
We spent countless hours scrolling through Fastweb, Niche, and Scholarships.com, platforms with thousands of listings, but every scholarship had 10,000+ applicants. Writing essays, gathering transcripts, and submitting applications became a part-time job on top of school. The process was exhausting, the odds were stacked against us, and the time investment rarely paid off.
That's when we asked: what if the problem isn't the student, it's where they're looking?
We discovered that millions in scholarships go unclaimed every year. Not national ones, hyper-local awards from Rotary chapters, credit unions, community foundations, and civic organizations. Scholarships with 30 applicants instead of 30,000. The kind nobody lists on aggregator sites. We set out to build the tool we wished we had.
What It Does
Our platform does three things no existing tool does together:
Hyper-local scholarship database — We built a searchable database of 131+ scholarships (for one specific location) that don't appear on major aggregator sites, scraped and verified from community foundations, civic organizations, Greek chapters, credit unions, and local employers across Maryland. Users can filter by county, race/ethnicity, gender, and essay requirements to find exactly what fits them. We compared the result with mainstream AI, It returned around 30 scholarships which is lesser than 25% of our scholarships.
AI voice call verification — Scholarship data scraped from the web goes stale fast — deadlines change, amounts get updated, programs get discontinued. We built an AI calling agent that phones each organization's scholarship office to verify details in real time. The agent confirms deadlines, award amounts, eligibility criteria, and application status, then writes the verified data back to our database. This means students see information that's been human-verified through an actual phone call, not just web-scraped and hoped for the best.
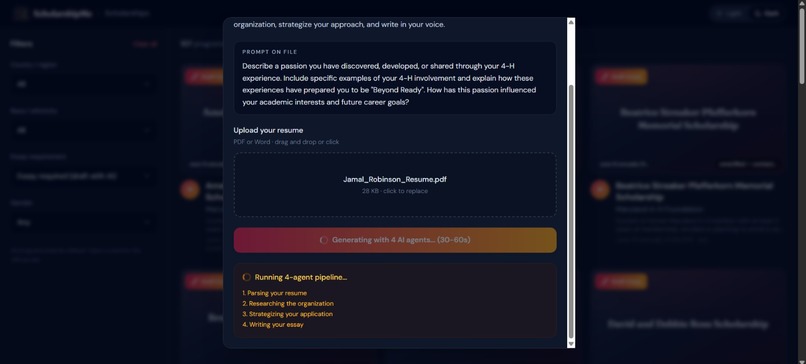
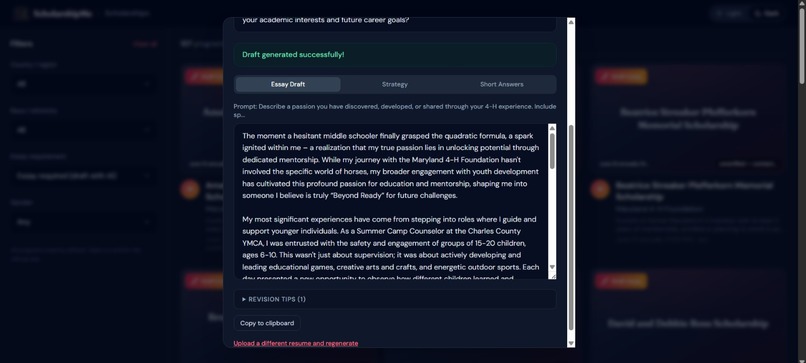
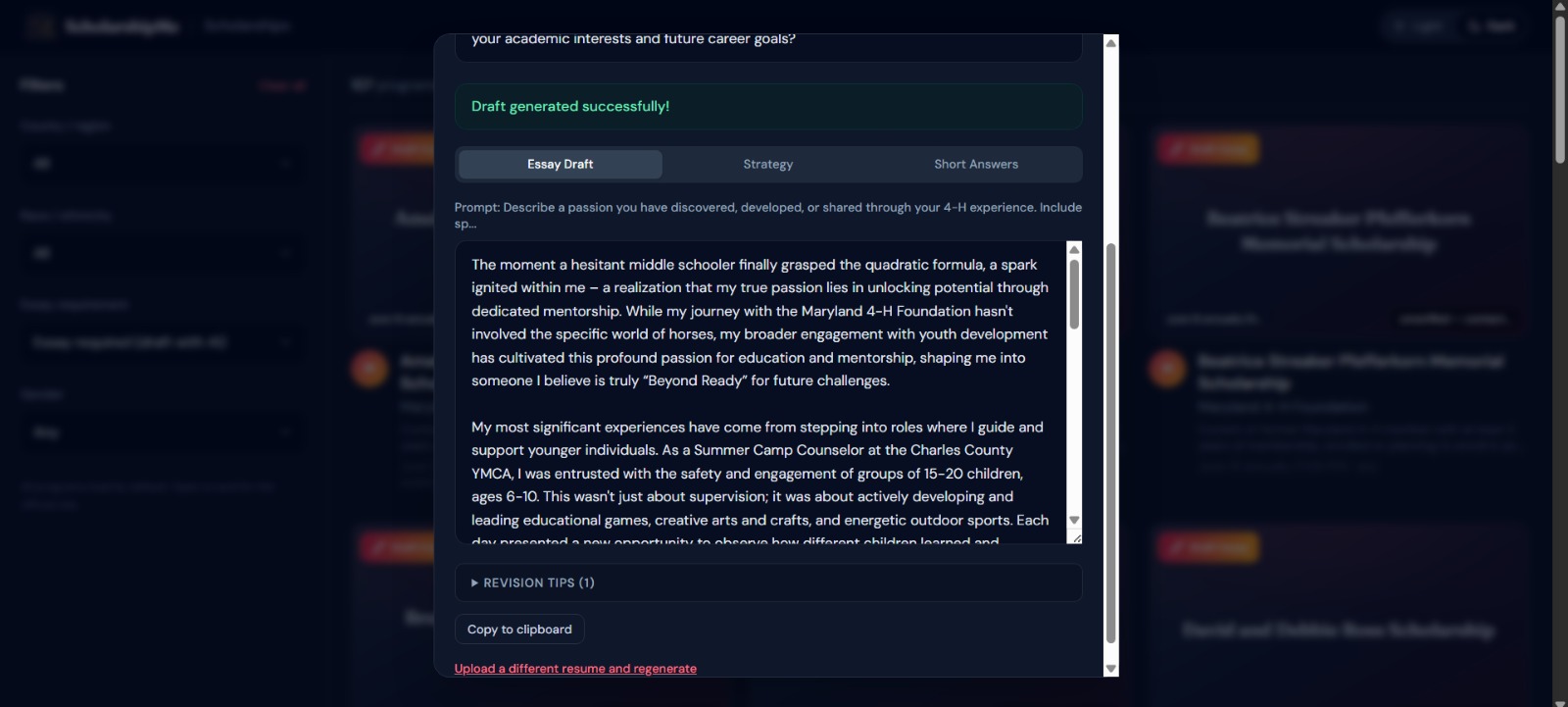
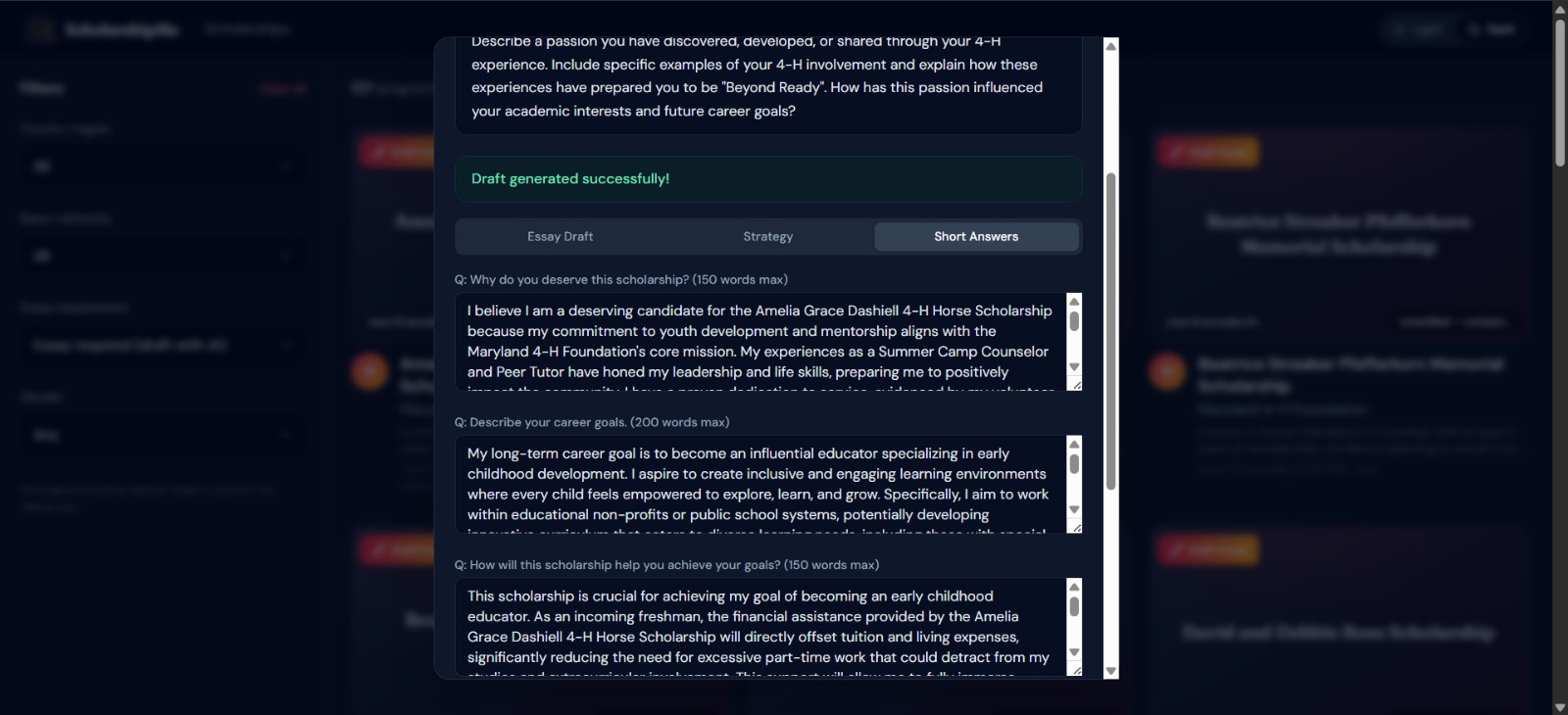
AI-powered essay drafting — For scholarships that require essays (60% of our database), users upload their resume and a 4-agent AI pipeline researches the organization, strategizes the application angle, writes a polished draft, and formats everything for export, in under 60 seconds.
How We Built It
The Data Pipeline
We built a custom autonomous research agent with a 10-tier scraping system that systematically searches government APIs, state agencies, community foundations, civic organizations, credit unions, and corporate programs. Each scholarship is decomposed to individual award granularity, not "Organization X Scholarships (varies)" but specific named awards with verified amounts, deadlines, and eligibility criteria. Our schema captures 46 fields per scholarship including essay prompts, application portal types, contact information, and geographic restrictions down to ZIP code and school district level.
AI Voice Call Verification
Web-scraped data is only as good as the last time someone updated the page. Many community organizations update their scholarship info once a year — or never. So we built an AI calling agent that verifies every entry by phone.
For each scholarship in our database, the agent:
- Calls the organization's verified contact number (extracted during scraping from the org's own website, not third-party directories)
- Confirms whether the scholarship is still active for the current cycle
- Verifies the deadline, award amount, and key eligibility requirements
- Asks about any changes from the prior year
Call outcomes are written back to the database in dedicated verification fields: verified, verified_active, verified_deadline, verified_amount, call_outcome, call_date, and call_notes. This gives every scholarship entry an audit trail — students can see not just what the website says, but what the organization confirmed over the phone.
This is why our schema requires verified contact information for every entry. A bad phone number wastes a call and produces no data, so the scraping agent follows a strict 4-step extraction process (scholarship page → org contact page → footer → PDF) and records where each phone number came from in a contact_source field.
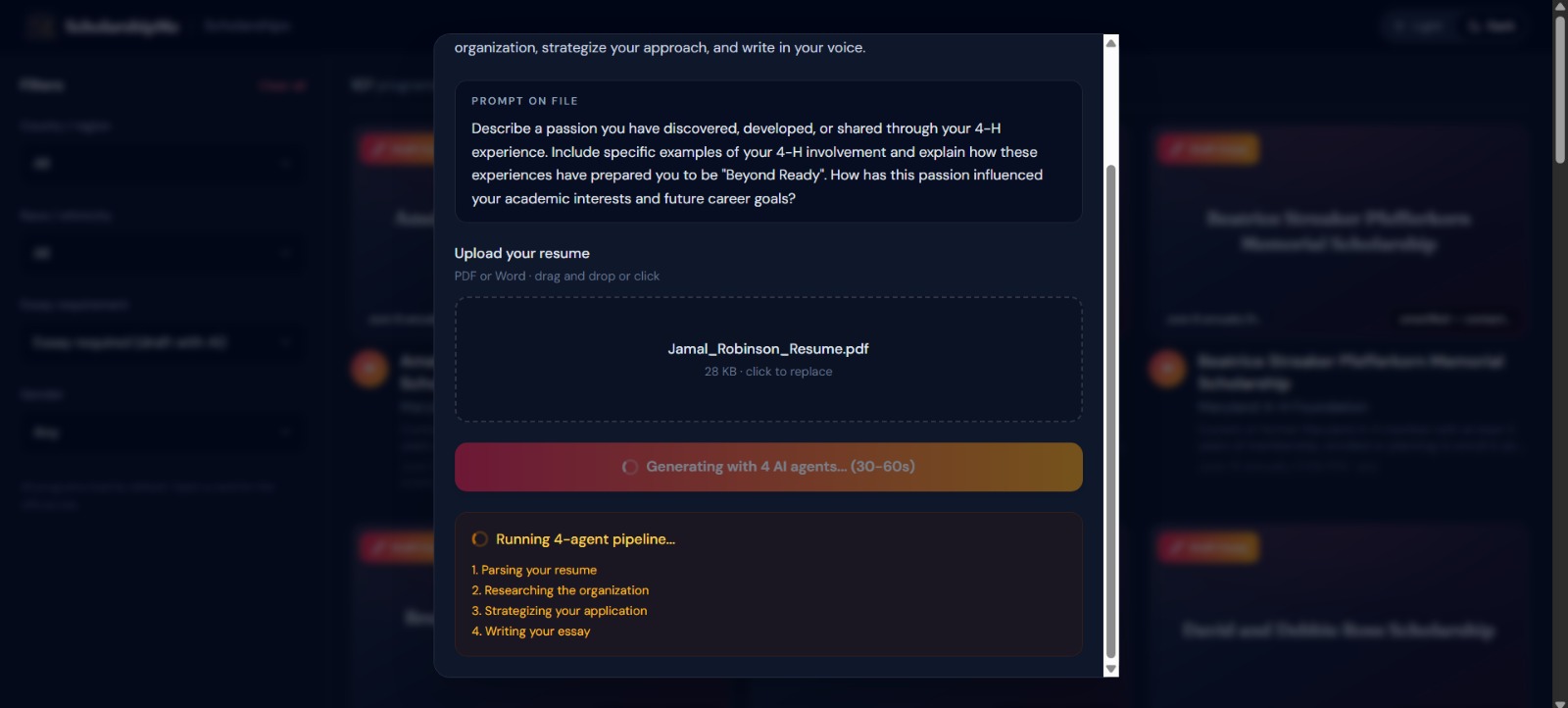
The 4-Agent AI Pipeline
This is the technical heart of the project. When a user clicks "Draft Essay" on any scholarship, four specialized AI agents execute sequentially, each with an exhaustive system prompt (11,000–13,000 characters each):
Agent 1 — Information Collector: Researches the sponsoring organization's mission, values, past winners, and essay requirements via live web search with CSV data fallback. Outputs a structured intelligence dossier with data confidence scoring.
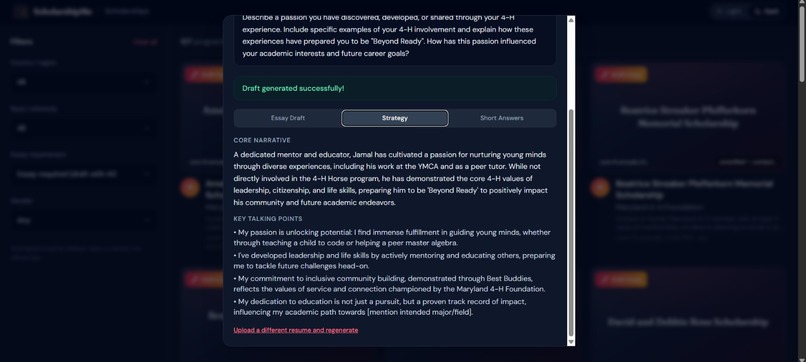
Agent 2 — Thinker: Cross-references the collector's intel with the user's resume using a 4-lens strategic framework (selection committee perspective, applicant pool analysis, story arc construction, authenticity balance). Produces per-essay strategies with specific opening hooks, word budgets, and tone recommendations.
Agent 3 — Writer: Executes the Thinker's blueprint with 7 writing principles (show-don't-tell, specific-over-generic, student's authentic voice). Generates complete submission-ready essays, short answers, and personal statements, not outlines, not templates.
Agent 4 — Filler: Structures all upstream outputs into CSV-compatible format with status tracking, completeness validation, and quality scoring.
Each agent's output flows into the next via an AgentContext state object, with error isolation ensuring one agent's failure doesn't crash the pipeline.
The Resume Parser
Users upload a PDF or DOCX resume directly on any scholarship that requires an essay. We extract text via PyPDF2/python-docx and send it to Gemini with a structured extraction prompt that maps to a 30+ field user profile schema, name, GPA, experiences, leadership roles, awards, career goals. This profile feeds directly into the Thinker and Writer agents so the drafted essay is personalized to the applicant, not generic.
Full-Stack Architecture
| Layer | Technology |
|---|---|
| Frontend | React, TypeScript, Vite, Tailwind CSS |
| API | FastAPI + Uvicorn (6 REST endpoints) |
| AI Engine | Google Gemini API, 4-agent pipeline |
| Voice Verification | AI calling agent with structured call scripts |
| Data Processing | Python, Pandas, Pydantic |
| Resume Parsing | PyPDF2, python-docx, Gemini extraction |
| Database | CSV (131 scholarships, 46 columns per entry) |
The FastAPI server serves both the API endpoints and the built React SPA from a single process, zero deployment complexity.
Challenges We Faced
Data quality is everything: National aggregators list scholarships at the organization level ("XYZ Foundation Scholarships, varies"). We had to decompose these into individual named awards. One organization page became 5–20 database rows after drill-down.
Verified phone numbers are harder than they look: A bad phone number is worse than no phone number — it wastes an AI call, gets flagged as spam, and produces no data. We learned to only record numbers found on the organization's own website, never from Google snippets or third-party directories. Even then, many scholarship coordinators are volunteers with no public number, so 30% of entries required manual follow-up.
"Same 4-H essay" problem: Our database had 24 entries saying "Same 4-H essay" instead of the actual prompt. We built a resolution system in the data loader that finds the canonical prompt within each organization and backfills all references at load time.
Agent response parsing: LLMs don't always return clean JSON. We built a 3-tier parser (direct parse, code block extraction, brace matching) that gracefully degrades, ensuring the pipeline never crashes even with malformed responses.
Resume-to-profile mapping: Resumes are wildly inconsistent in format. Our Gemini extraction prompt had to handle everything from high school student one-pagers to graduate CVs, inferring academic level, extracting GPA from random locations, and parsing leadership roles from activity descriptions.
What We Learned
The data doesn't exist in one place. No API, no master list. Hyper-local scholarships live on community foundation PDFs, Google Forms, Rotary chapter Facebook pages, and credit union websites. That's why we had to run multiple AI agents with effort levels set to high, building the database was harder than building the app.
Web scraping alone isn't enough. Websites go stale. The only way to know if a scholarship is truly active is to call the organization. Automating that verification step with voice AI turned our database from "probably accurate" to "confirmed this month."
Good, simple UI matters from day one. Students are already overwhelmed. If the tool feels like another chore, they won't use it. We learned to prioritize clean filters, clear essay badges, and one-click drafting over feature bloat.
40% of scholarships don't need essays. Students skip scholarships because they assume every one requires a 500-word essay. Surfacing the no-essay ones is an instant win for applicants short on time.
What's Next for ScholarshipMe
Expand beyond Maryland — Our 10-tier scraping agent is state-configurable. Next targets: Virginia, DC, and the full DMV corridor, then a nationwide rollout state by state.
Automated monthly re-verification — Schedule the voice calling agent to re-verify every scholarship on a monthly cycle, keeping the database permanently fresh without human intervention.
Application tracking dashboard — Let students track deadlines, submission status, and outcomes across all their scholarships in one place. Feed win/loss data back into the system to improve recommendations.
Self-improving agents — Track which essay drafts lead to wins. Over time, the Thinker and Writer agents learn which strategies, tones, and angles actually convert for specific organization types.
Direct application submission — Integrate with Google Forms, Submittable, Kaleidoscope, and AwardSpring APIs to let students submit applications directly from ScholarshipMe without copy-pasting.
Mobile app — Scholarship deadlines don't wait. Push notifications for upcoming deadlines and new scholarships matching your profile.
Community verification layer — Let past winners confirm scholarship details, share tips, and flag expired programs, turning the database into a living, student-maintained resource.
Built With
- beautiful-soup
- fastapi
- framer-motion
- google-gemini-api
- httpx
- leaflet.js
- pandas
- pydantic
- pypdf2
- python
- python-docx
- railway
- react
- react-router
- tailwind-css
- typescript
- uvicorn
- vapi-(voice-ai)
- vite




Log in or sign up for Devpost to join the conversation.