Inspiration
Andrej Karpathy, one of the most famous AI researchers, has heavily promoted the use of AI to advance the research frontier. A leading computer science researcher Don Knuth from Stanford recently published a paper called "Claude Cycles" that explained how LLMs and human direction directly solved a pure math and algorithms research problem. As AI researchers at Purdue, Daniel and I found inspiration in their words and in our personal experiences. We found that the tools we use are disorganized across various platforms and many repetitive tasks could be automated. Frontier AI labs are publishing research at unprecedented speeds and we hope to be the first to formalize that velocity using AI.
Although the benefits of LLMs are advancing in coding tasks, we have not seen a product combining frontier research and AI. Our motivation is not to replace AI researchers, but accelerate their work so a small high-skilled team of purely researchers equipped with AI, can outpace a large team with a variety of employees.
We noticed that LLMs can uniquely solve a couple problems. LLMs are generalizable and adaptable so they can be used to automate novel Machine Learning research experiments, reproduce experiments in published papers, conduct deep literature review, and assist in paper creation.
What it does
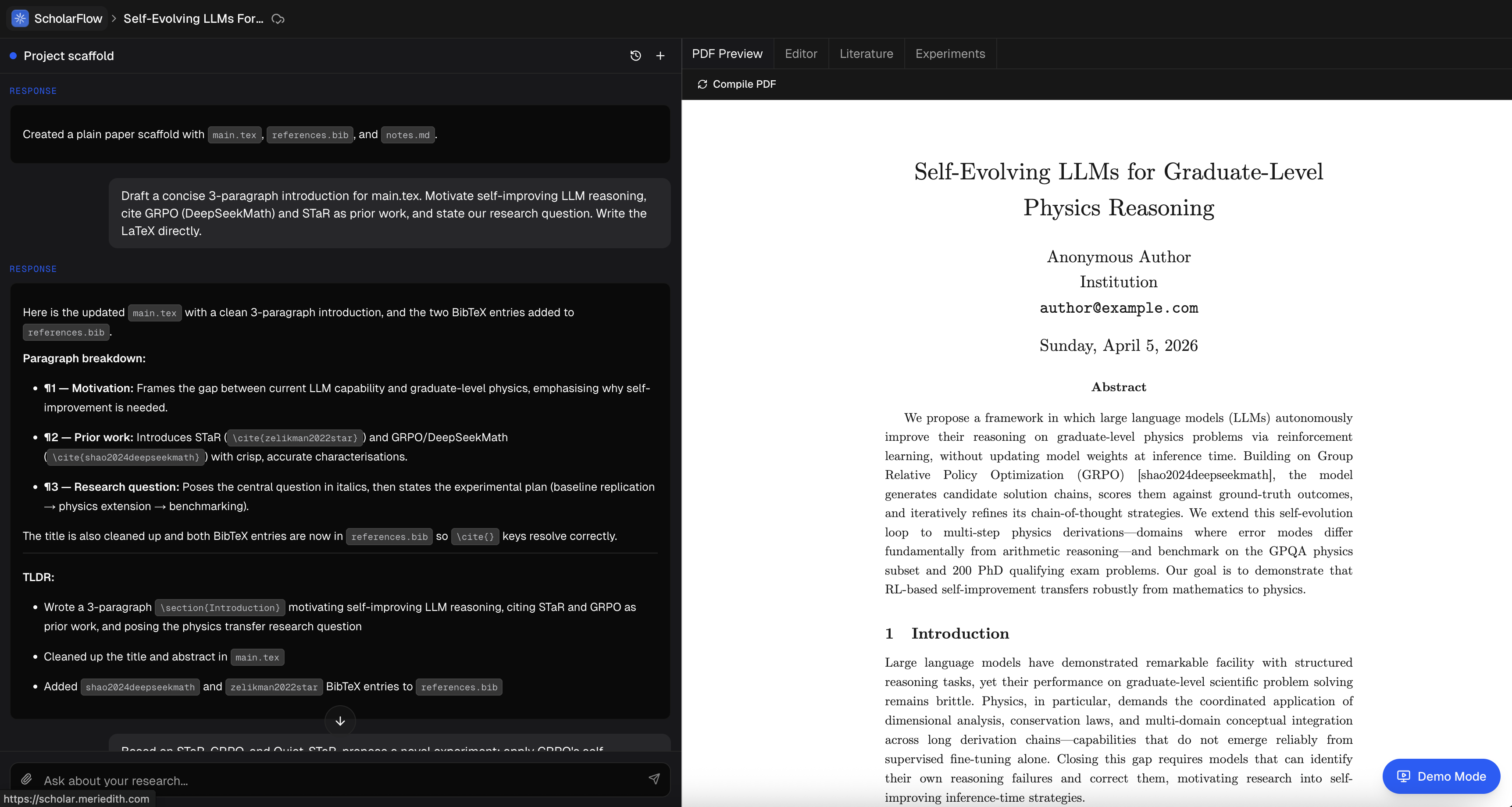
Our AI research platform, ScholarFlow, facilitates an end-to-end workflow assisting researchers from idea to paper. We offer an integrated research environment (IRE), a spin on integrated development environment (IDE), that allows for seamless context switching between different services within the platform.
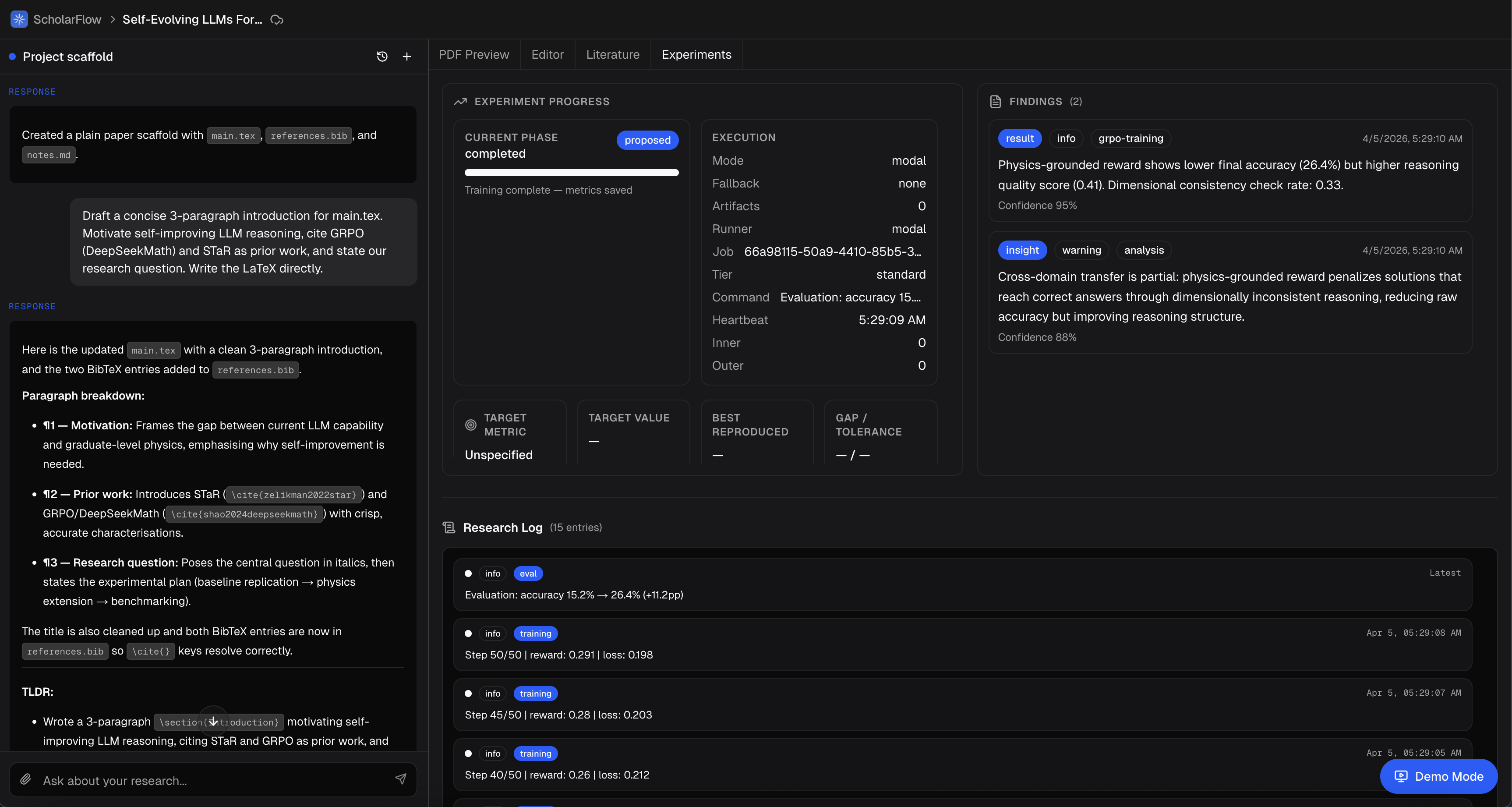
Automating novel Machine Learning experiments: Replaces research engineers by offering quicker development times, highly customized workflows and rich reports for researchers.
- An intake form allows researchers to input Experiment Name, Description, Benchmark/Success Criteria, Github Repo, Computer tier, Dataset and access credentials, and Context papers.
- This information runs through our preprocessing pipeline that creates a compressed executable code package, benchmark evaluations and dataset connection.
- Our pipeline will automatically train the machine learning model on the dataset using the configurations specified and infer information necessary.
- We use a GPU accelerated cloud worker facilitated by Modal to execute an asynchronous compute instance running the code package and returning the final evaluations.
- Our pipeline produces a final report of all findings and evaluation of the metric compared to benchmarks.
Reproducing technical papers: Automates the menial task of reproducing technical papers, verifies their credibility and provides a baseline for future work.
- Given an input paper, we kick off the extraction pipeline and create the same executable code package and similar benchmark evaluations.
- We send the code package o the async compute worker and attempt to simulate the results listed in the paper.
- We produce a report that compares the findings in our reproduced experiment to the ones listed in the paper and is used as context for future novel experiments.
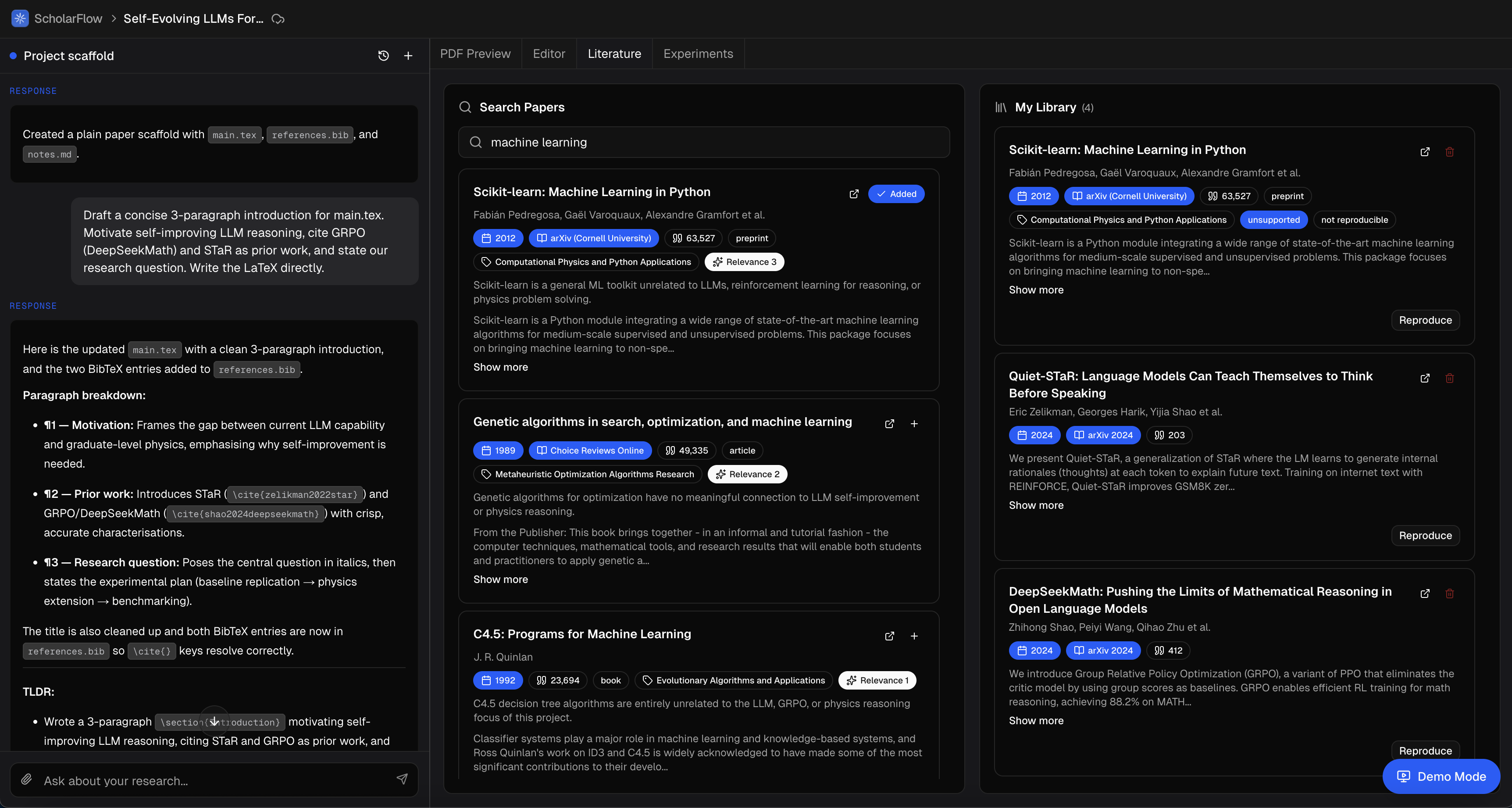
Deep Literature Review: Solves a massive pain point by creating a curated paper search and persistent library of researcher selected papers for future reference.
- The researcher inputs a query and we search a database of hundreds of thousands of high quality research papers in seconds to output a curated list of relevant results.
- The results are scored with a relevancy score to the research project's goal and direction to provide further context to the researcher.
- Researchers can add papers to their "library" which is a custom persistent database of papers linked to each project that can be referenced in automated experiments and paper creation.
- Using AI, we create a specialized summary of the paper with context of the research project for a quick read and an option for further reading.
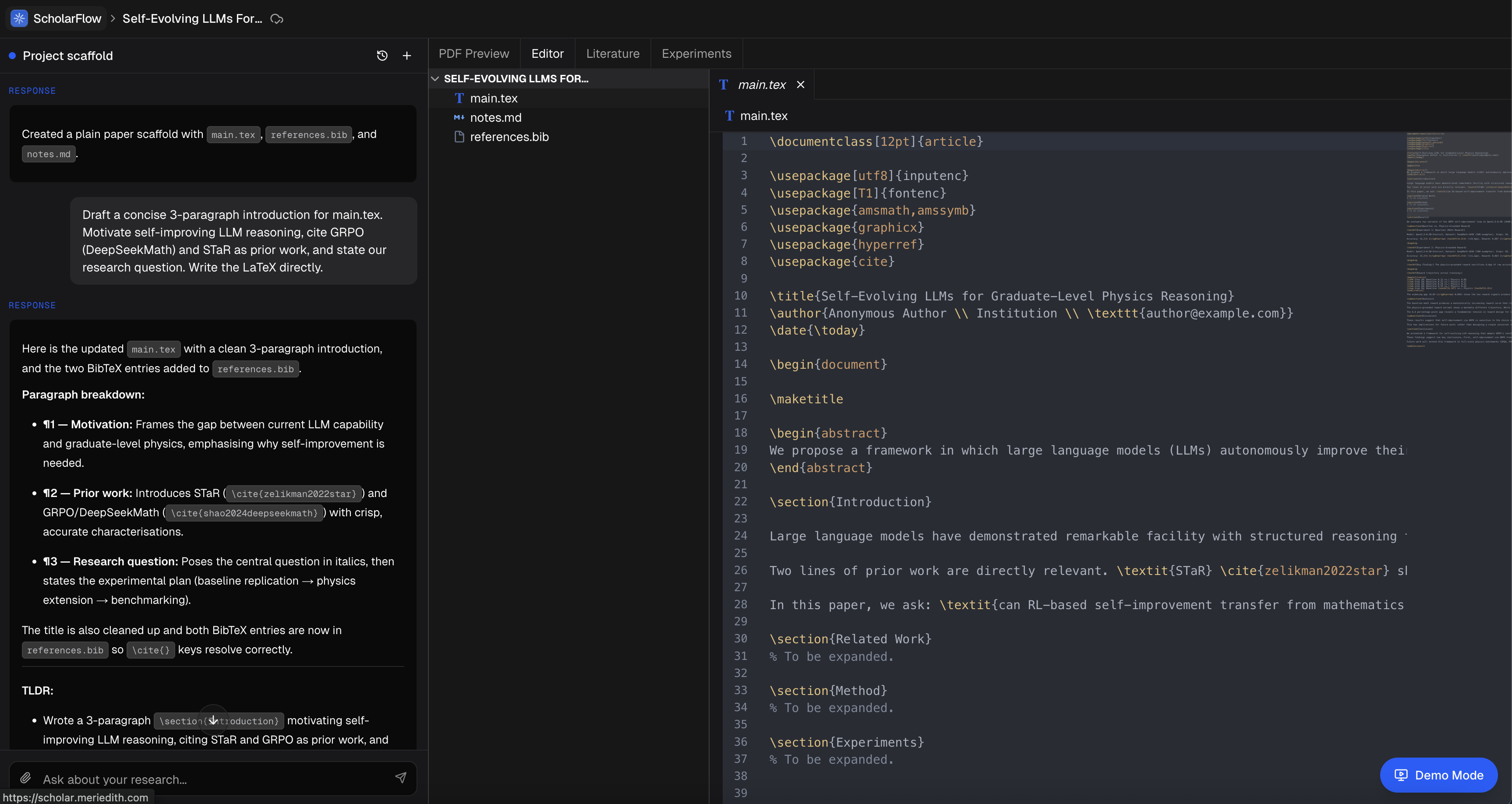
Paper Creation Chat Assistant: A Cursor x Overleaf IDE for fast, context aware and AI assisted paper writing to help formalize findings and generated a high quality paper.
- An overleaf-like feature that allows Latex file hosting and compilation with an in-built PDF viewer.
- A cursor-like chatbot feature that allows dynamic prompt-based file editing and file creation.
- The chatbot features project context based references where you can reference specific automated experiment findings, papers in your library, and files in your workspace facilitating an integrated workspace.
- The chatbot answers questions about the research domain and acts like a peer researcher to generate ideas with.
How we built it
Machine Learning Experiment Automation Layer:
- The preprocessing pipeline enriches the data using a web search for relevant information concerning the dataset connection and benchmark evaluation while extracting relevant code samples for stitching.
- The pipeline uses Anthropic API and the Claude sonnet model to process data and stitch the wide variety of code samples to generate the compressed executable consisting of only a couple files and their dependencies reducing bloat, improving runtime and reducing errors during inference.
- We use the Modal API to kick off an asynchronous worker that will train and evaluate the model and has a published websocket connection to our backend to stream real-time detailed logs.
- We developed an automated code-healing agent that ingests error messages from the Modal instance, edits the code package and retries the run.
- We extract the results from the Modal instance and output a robust report using LLMs reviewing the experiment for the researcher.
- The researcher can edit experiment information with new insights and retry the experiment with the click of a button.
Literature Review:
- We search hundreds of thousands of papers in real time using the OpenAlex API that uses semantic and project context based search on a large curated list of papers in all research domains.
- The papers are graded on a relevancy score using a semantic model that compares the papers with all context in the workspace including input prompt, latex files, research library and experiments.
- After researchers add a paper to their library, we use LLMs to process the paper and generate a project context based summary as a quick read.
Paper Creation:
- We built a custom mpm Latex compiler and in-built editor storing latex files, edits, and hierarchy and compiling on demand.
- The chatbot is equipped with specific tools and context of the hierarchy of the file structure in the custom Latex IDE to execute edits.
- We process the researcher input and allow the LLM to select tools (create, delete, edit) similar to an MCP configuration as needed, and the LLM returns a structured output with concrete tasks.
- On top of tool handling, the chatbot is equipped with web search to enrich domain based questions a researcher may have about their research.
- The researcher can tag artifacts in the workspace using their unique ID (@12345), which will pull context and provide more information for the LLM to act on.
Deployment:
- We built our application's frontend using Next.js and hosted it publicly on Railway.
- Our backend is hosted on Inngest facilitating the asynchronous experiment runs and other capabilities.
- We use SQLite for data storage and host data on the user side, to simplify the experience for users, remove security risks and keep data persistent across one session.
Challenges we ran into
- We ran into challenges to get a reliable experiment automation system running with relatively quick outputs but we were able to create the custom compressed code package that sped up the training and testing process.
- We explored many options to get a service that was able to search a large database of papers, and in the end OpenAlex worked very well.
- Building out a context aware chatbot was difficult, but by using well scoped data models and structured tool calling we were able to make the LLM's output deterministic and accurate.
Accomplishments that we're proud of
- We're proud of building a reliable experiment automator that can directly help researchers conduct more high quality experiments and iterate quicker towards important findings.
- We're especially proud of discovering the compressed code package pipeline which is a novel solution for efficient generalized code execution for any compute heavy domain.
- Building a robust search across hundreds of thousands of texts was also a big achievement, solving a massive pain point for researchers who rely on outdated search techniques and manual paper reviewing which is tedious.
- We're impressed that we were able to build a full fledged latex compiler, text editor and AI-equipped IDE that's context aware across the whole workspace for paper generation.
What we learned
- We looked into researcher's menial tasks and problems, and we learned a lot about the day to day life of top researchers in the AI/ML industry.
- We learned a lot about automated systems and the benefits of LLM's generalization for code generation.
- We learned about all the backend effort that it takes to build a dynamic chatbot similar to cursor's agentic IDE and how to make LLMs more deterministic.
What's next for ScholarFlow
- We plan to expand our domain from just machine learning and AI based experiments to other domains like physics, chemistry, computational biology and more.
- Our chatbot will be trained specifically on research papers to offer hyper focused and accurate results to knowledgable researchers.
- We plan to add a collaborative mode similar to Google docs and Notion where multiple researchers can work in the same workspace in real-time.
Built With
- anthropic
- claude
- javascript
- latex
- modal
- mpm
- next.js
- openalex
- railway
- sqlite



Log in or sign up for Devpost to join the conversation.