-
-
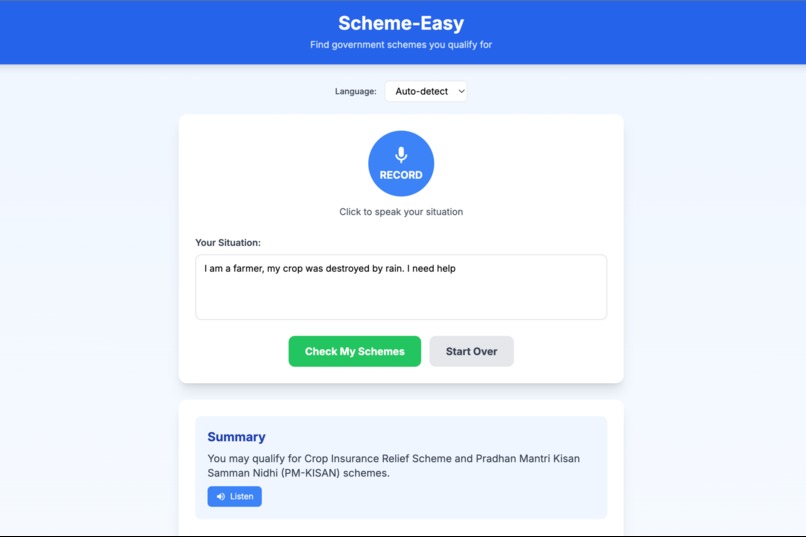
"Step 1: Just speak your problem. Our local Whisper model transcribes and understands the context"
-
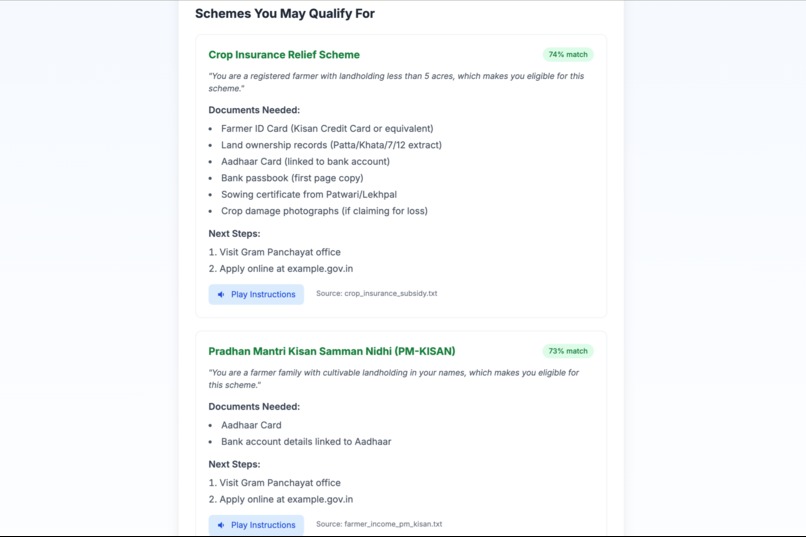
"Step 2: Get precise results. The AI matches your situation to specific schemes like PM-KISAN, listing exactly what documents you need "

Inspiration
Government welfare schemes in India are powerful tools for poverty alleviation, but they often suffer from a massive information gap. Millions of eligible citizens—farmers, daily wage workers, and the elderly—miss out on benefits simply because they are unaware of the schemes or cannot navigate complex, bureaucratic websites.
We have noticed that existing portals are often text-heavy, written in English, and require a high level of digital literacy. We wanted to build a bridge: Scheme-Easy. Our inspiration was to create a tool that works the way humans communicate—through voice and simple language—empowering even the least tech-savvy users to claim their rights.
What it does
Scheme-Easy is a privacy-first, voice-enabled chatbot that acts as a personal welfare assistant.
- Listens: The user taps a big button and speaks their situation in their native language (e.g., "I am a farmer and my crop was ruined by rain").
- Understands: The app transcribes the speech locally using Whisper and analyzes the intent.
- Matches: It runs a RAG (Retrieval-Augmented Generation) search against a database of government schemes using vector similarity.
- Guides: It responds with a simple, jargon-free summary of eligible schemes, a precise checklist of required documents (like Aadhaar, land records), and immediate next steps.
- Speaks: It uses Text-to-Speech to read the instructions back to the user, making it accessible to those who cannot read.
How we built it
We architected the system to be 100% local and free, ensuring that user data never leaves their device and there are no API costs.
- Frontend: We built a responsive, accessible UI using React and Tailwind CSS. We utilized the Web Audio API to capture high-quality voice input directly from the browser.
- Backend: We used FastAPI (Python) to handle requests.
- The AI Engine (The "Brain"):
- Transcription: We integrated OpenAI Whisper (Local) to convert speech to text without external APIs.
- Vector Search: We used FAISS to create a searchable index of scheme documents.
- LLM & Embeddings: We leveraged Ollama running locally. We used
nomic-embed-textfor creating vector embeddings and Llama 3.2 for generating human-like responses.
- Data Pipeline: We wrote a custom ingestion script (
ingest.py) that parses raw text/PDFs of schemes, chunks them, and builds the vector index automatically on startup.
Challenges we ran into
- Going Local: Transitioning from cloud APIs (OpenAI) to a fully local stack was tricky. We had to configure Ollama correctly to accept requests from our Python backend and ensure the models (
llama3.2) were loaded efficiently. - Audio Processing: Getting the raw audio bytes from the React frontend to be readable by the local Whisper model required careful handling of temporary files and
FFmpegformats. - Environment Conflicts: We faced the infamous
OMP: Error #15on macOS, where the PyTorch and FAISS libraries conflicted over OpenMP runtimes. Debugging this required diving deep into environment variable configurations (KMP_DUPLICATE_LIB_OK). - Accuracy vs. Speed: Balancing the speed of the transcription (using the
basemodel) vs. the accuracy (usingsmallormedium) was a constant trade-off we had to tune.
Accomplishments that we're proud of
- Zero-Cost Architecture: We successfully built a powerful AI application that costs $0 to run. By using local models, we eliminated the barrier of expensive API subscriptions.
- Privacy by Design: Since no audio or text data is sent to the cloud, users can trust the app with sensitive personal information.
- Seamless Voice Integration: The "Record -> Transcribe -> Query -> Speak" loop feels magical and works surprisingly fast on local hardware.
- Robust Ingestion: Our system allows anyone to simply drop a new
.txtfile into a folder, run one command, and instantly have the AI "learn" a new government scheme.
What we learned
- The Power of Open Source AI: Models like Llama 3 and Whisper have democratized AI development. You no longer need a massive budget to build intelligent apps.
- RAG Intricacies: We learned that "retrieval" is just as important as "generation." Fine-tuning how we chunk the documents (by splitting them into eligibility vs. benefits) significantly improved the quality of the answers.
- Full-Stack Integration: Connecting a React frontend to a Python/AI backend taught us valuable lessons about CORS, file handling, and asynchronous API calls.
What's next for Scheme-Easy :
- Multilingual UI: While the AI understands multiple languages, we want to localize the buttons and menus into Hindi, Marathi, and Tamil.
- Mobile App: We plan to wrap the React frontend into a Capacitor or React Native app for easier distribution on Android phones in rural areas.
- WhatsApp Integration: Since most of our target demographic uses WhatsApp, creating a bot version of Scheme-Easy is our ultimate goal for widespread adoption.
- Offline Mode: We aim to optimise the vector search to run even on low-end devices without an active internet connection.
Built With
- css
- faiss
- fastapi
- javascript
- numpy
- ollama
- pypdf2
- python
- react
- uvicorn
- whisper

Log in or sign up for Devpost to join the conversation.