-
-
upload
-
version control
Inspiration
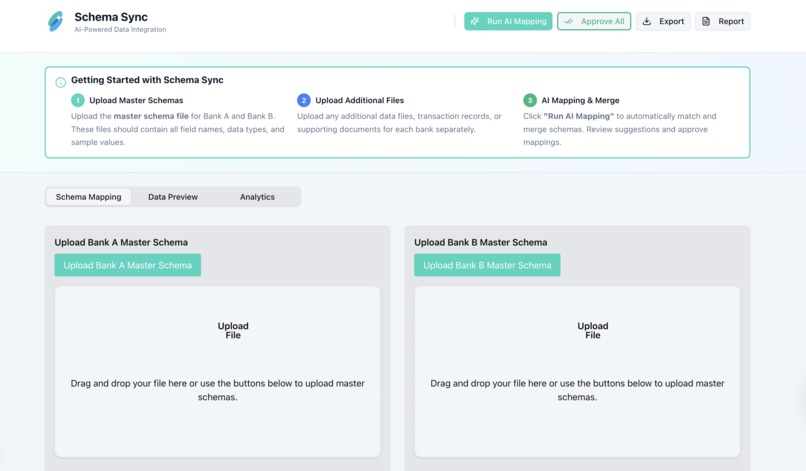
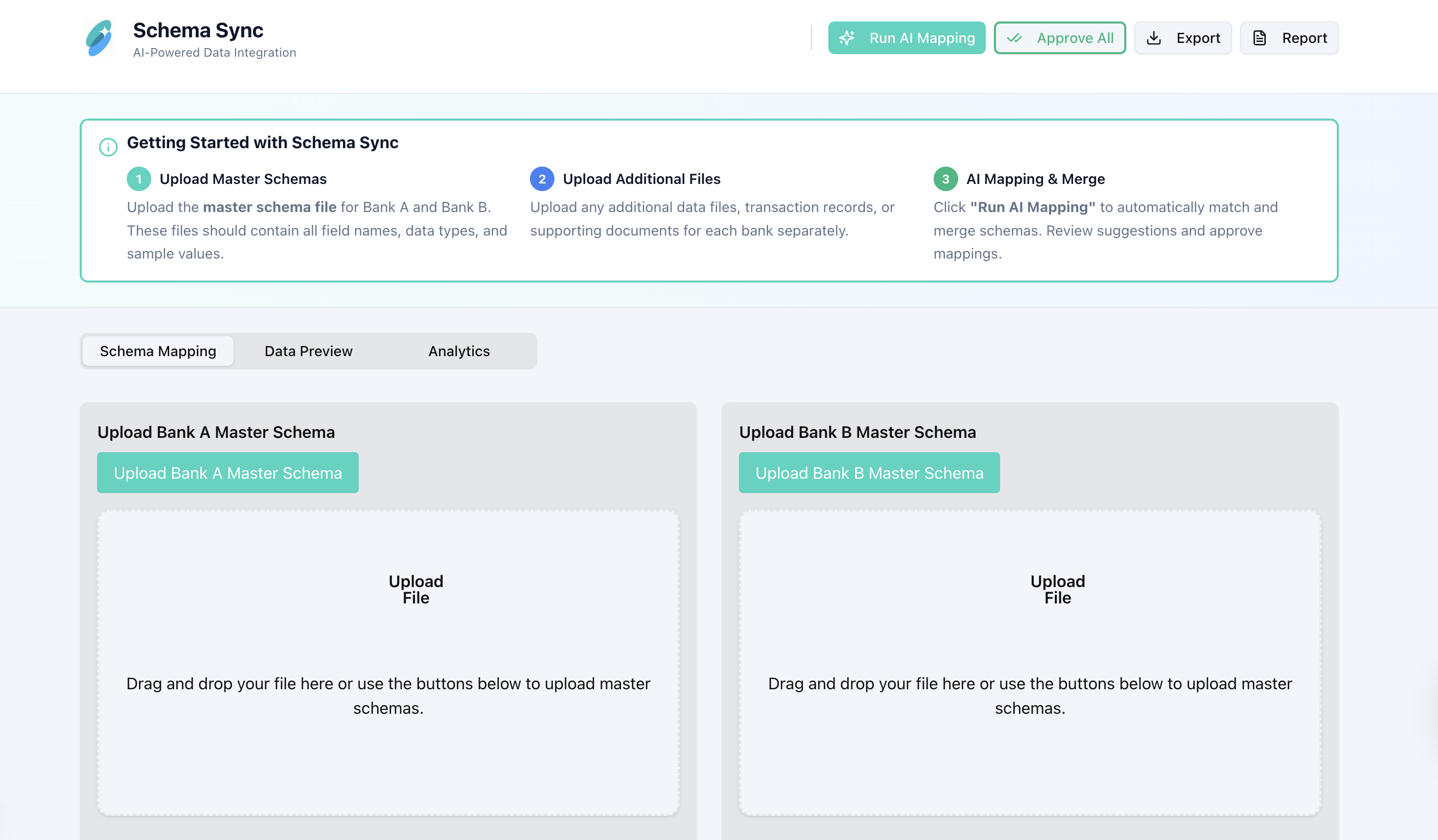
When two banks merge, data chaos follows. Each has its own schema, formats, and naming conventions, which turns integration into weeks of manual mapping and Excel wrangling. We wanted to build an AI copilot that handles the tedious mapping work, preserves every record’s context, and helps analysts focus on insights, not cleanup.
What It Does
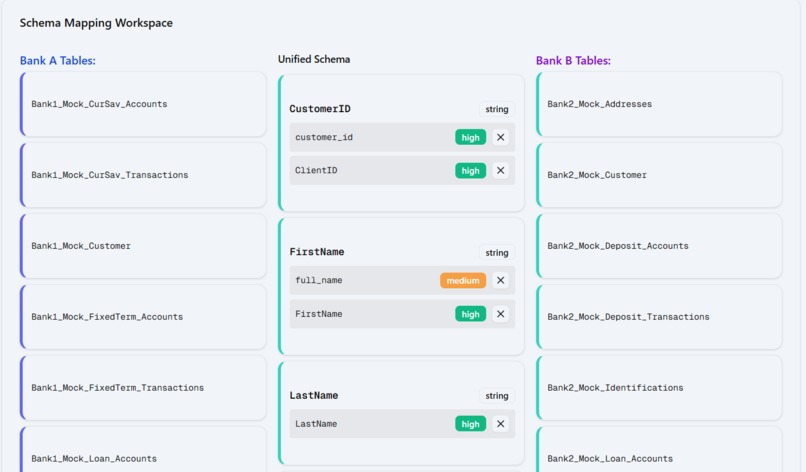
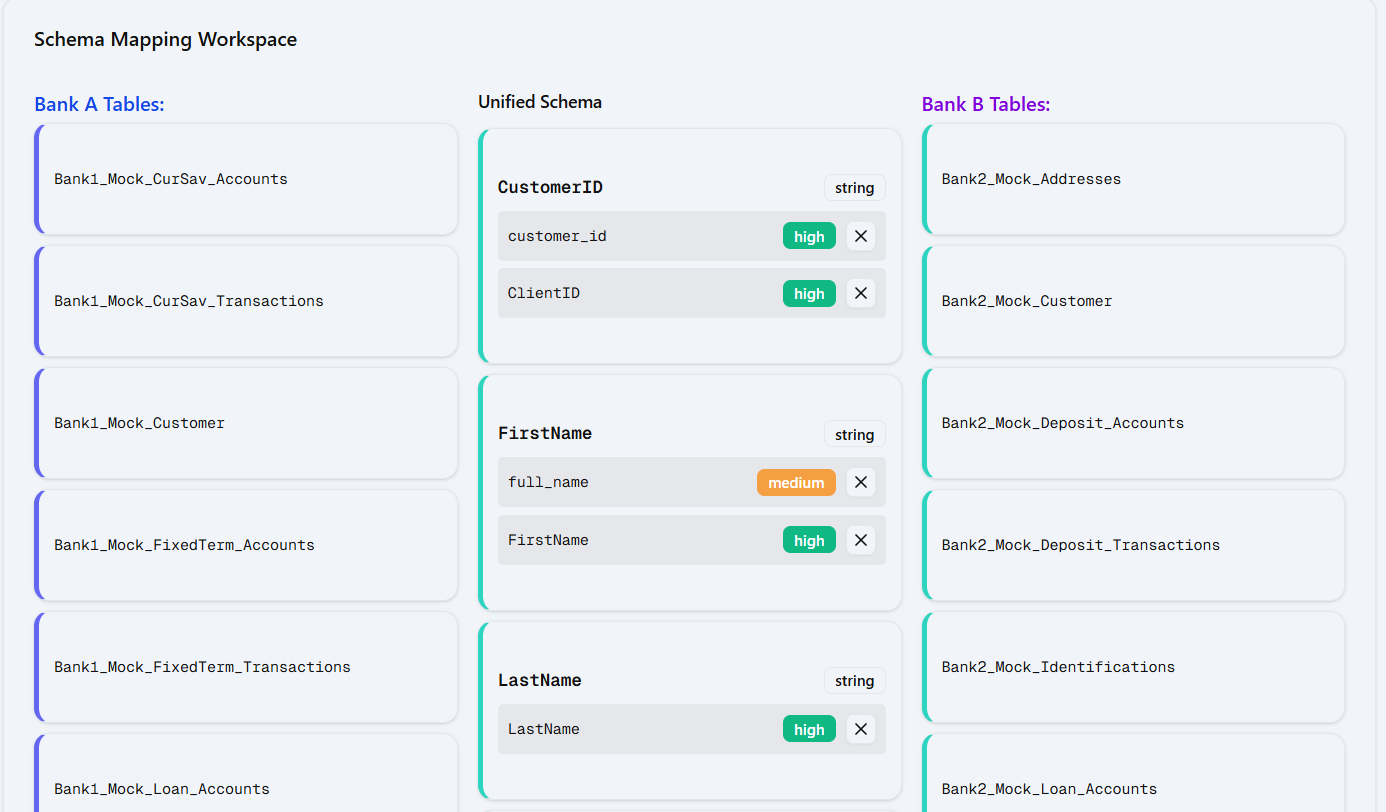
Schema Sync turns complex, mismatched datasets into a single unified view. Simply upload the schemas and data files for the two banks, and our AI-powered matcher will suggest field pairings with confidence scores. Then, the visual workspace lets users review, approve, or override matches. The merged output includes completeness and consistency reports, plus audit logs for every mapping decision. Finally, one-click Excel/PPT exports deliver ready-to-use tables for teams and executives.
How We Built It
- Frontend: React (Next.js) + TypeScript + shadcn/ui for a sleek, drag-and-drop mapping workspace.
- Backend: FastAPI (Python) for schema parsing, validation, and merging logic.
- AI Layer: SBERT embeddings + cosine similarity to detect equivalent tables and columns across datasets, producing ranked match suggestions with confidence scores.
- Data Layer: Snowflake warehouse for ingestion, transformation, and validation to ensure data integrity and context retention.
- Exports: openpyxl & python-pptx for polished Excel and PowerPoint outputs.
- Infrastructure: Dockerized microservices with lightweight CI/CD via GitHub Actions. Our team used GitHub for version control. Each member worked on their own feature branch (e.g., isabel_dev, selvahini-dev, sansita-dev) and merged changes into main via pull requests. This workflow ensured clean integration and avoided conflicts during development
Challenges We Ran Into
Handling Multiple Data Formats
Deciding how to manage the different data formats was difficult, as we had to consider what would make the rest of the workflow run more easily. Eventually, we settled on converting the schemas into JSON objects for easier comparison with AI.
Schema Standardization and Conversion
It was unclear how to best represent the uploaded schemas in a way that the AI mapping logic could process reliably. The solution was to convert all schemas into structured JSON objects, which allowed easier comparison and manipulation programmatically.
Frontend-Backend Integration and File Uploads
The frontend needed to manage file selection, progress indication, and proper routing of files to the correct backend endpoint. The backend had to be able to accept multiple upload types while respecting the intended storage structure and parsing logic.
The project faced challenges in handling ambiguous or inconsistent column names, preserving data completeness during merges, managing type conflicts and null values, and ensuring high performance for AI-powered similarity checks. Additionally, designing an intuitive UI that works for both analysts and non-technical users was critical.
Accomplishments We’re Proud Of
- Implementation of AI to assist with data mapping for efficient integration.
- Frontend-Backend integration
- Successfully merging the data from the two banks
What We Learned
- How to leverage cosine similarity to compare semantic similarity with SBERT
- Utilizing SQLite for database usage
- Data handling in general
What’s Next for Schema Sync
- Fine-tuning our own AI model to lead to higher accuracy and confidence ratings when mapping data together
- Generate analysis reports
- Extend the AI model to support multi-bank and multi-system integrations
Further Documentation
https://docs.google.com/document/d/1oW48YH8hn71Ys28lzQzdd4CesOMKlL6mA0H4zsUnxBE/edit?usp=sharing https://docs.google.com/document/d/18WgKH_BULrKiIP5a7n6-lmQwaibr5gJuNRIlTVnumg4/edit?tab=t.0



Log in or sign up for Devpost to join the conversation.